最近两天,DeepSeek-R1 的热度冲上云霄,不仅连续登顶中国、日本、美国三大 App Store 的免费榜。
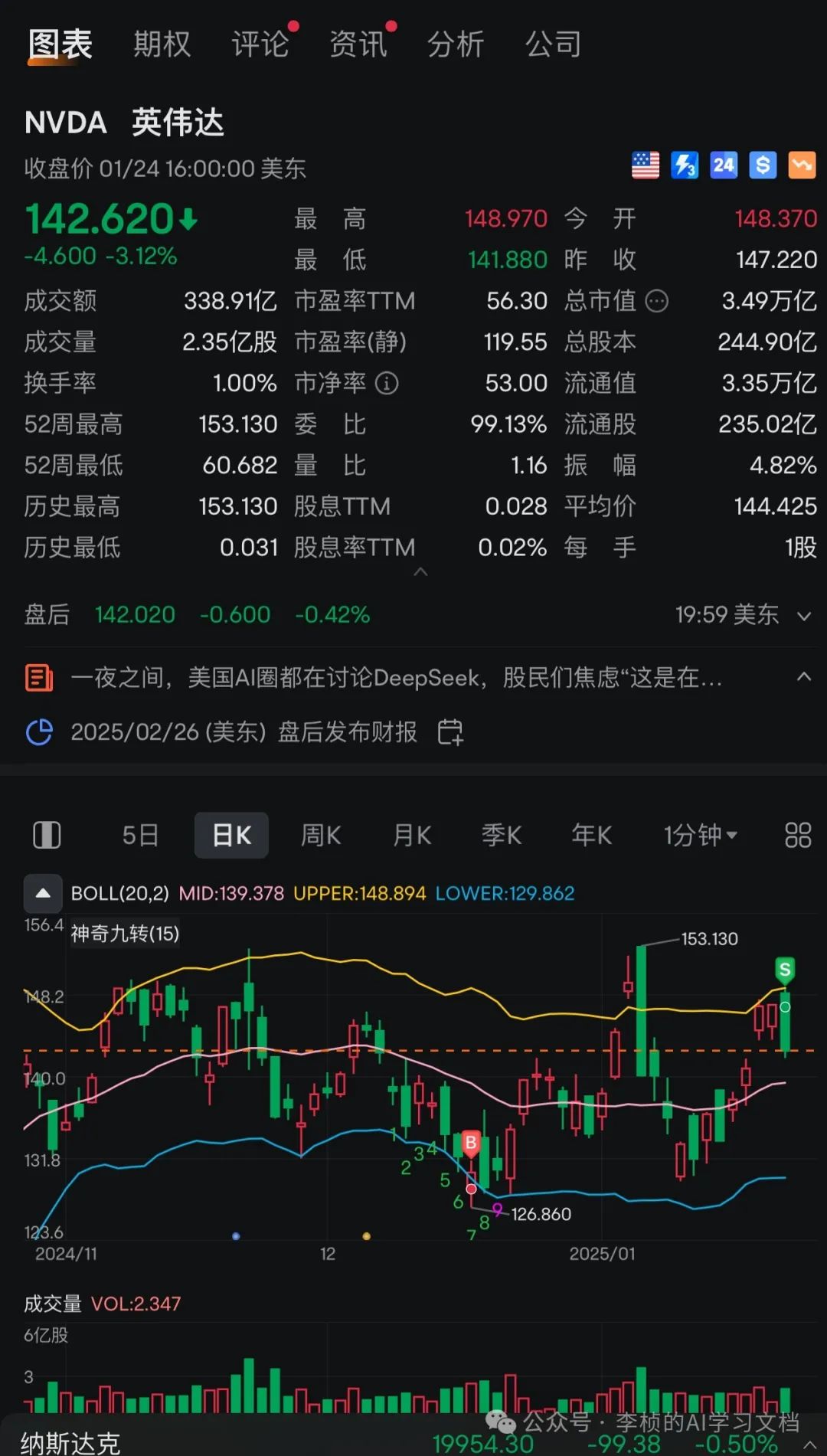
还在美股盘前交易时段让英伟达的股价一度重挫 13%,连带台积电也受到波及。 注意 13% 是个什么概念, 也就一个多腾讯的市值吧,一个腾讯吧(DeekSeek 就可以做空英伟达挣钱了,哈哈哈哈哈)
很多朋友看到社交媒体或新闻报道,第一时间都会好奇:这款模型究竟是什么来头,怎么突然“爆火”到这种程度?年后的企业课程,董事长要求必须讲讲 Deep Seek 。
更有意思的是,我老家那几位平时从未接触过 AI 的长辈们,甚至七大姑八大姨都在问:“DeepSeek 是干啥的?怎么用?中国之光,咋回事”
不过也有人在评论区说在试用 DeepSeek-R1 后,吐槽“它连 8.11 和 8.9 谁大都要好几秒才想明白,这不是说好的深度推理模型吗?”可见关于 DeepSeek,这两天满屏都是消息,却也真真假假、观点不一。于是,趁着这个时机,我整理了关于 DeepSeek 的相关信息,希望用 8 问 8 答,让你对 DeepSeek-R1 有一个更为全面和深入的理解。
Q1:DeepSeek 是什么样的公司?
DeepSeek 背后的公司名为「深度求索」,成立于 2023 年 7 月 17 日。从字面可以看出,“深度求索”这四个字,就暗示了这家公司的定位:深度学习与前沿探索。
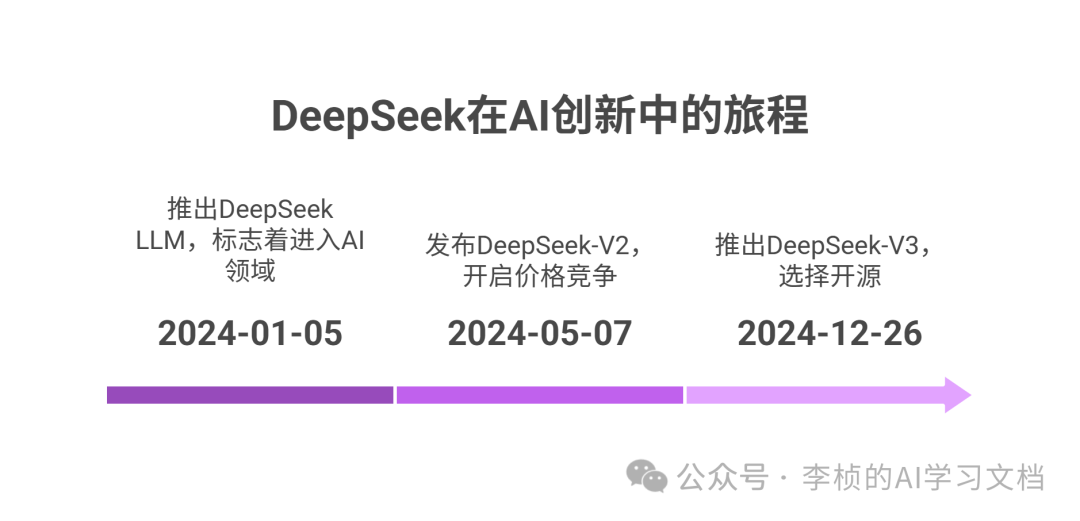
时间线:
- 2024 年 1 月 5 日:他们推出了首个大模型 —— DeepSeek LLM,这也是深度求索正式进军 AI 领域的开端。
- 2024 年 5 月 7 日:发布 DeepSeek-V2,并率先掀起了国内大模型的“价格内卷”。当时,DeepSeek-V2 的 API 价格只相当于 GPT-4o 的 2.7%,迫使国内其他大厂(字节、阿里、百度、腾讯等)在随后的短短一周内跟进降价。
- 2024 年 12 月 26 日:DeepSeek-V3 面世且选择开源,训练成本仅约 557.6 万美元。在同等性能的情况下,远低于许多海外巨头的训练投入。凭借这个几乎媲美主流闭源模型的性能,DeepSeek-V3 让海外科技圈大为震动,进一步奠定了“东方 AI 新势力”的国际名声。

(不知道是不是真的, 但是感觉有点酸酸的)
- 2025 年 1 月 20 日:他们正式发布 DeepSeek-R1,再度震惊全球。根据多方测评,R1 与 OpenAI 最新推理模型 o1 能力旗鼓相当,但在 API 定价上只要后者的 3.7%,并依然开源。
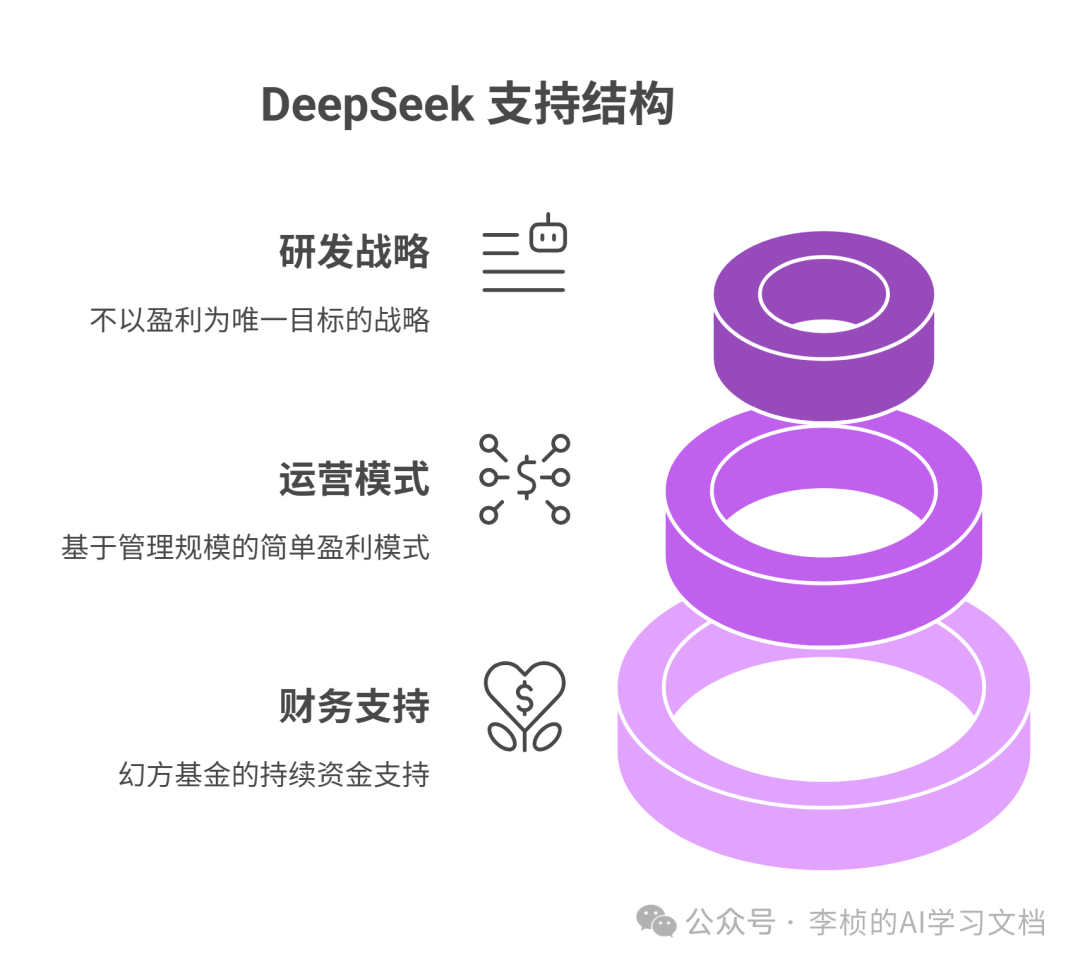
值得一提的是,深度求索的背后资金支持是来自国内知名量化私募「幻方基金」。
这种基金的盈利模式相对简单:与管理规模挂钩,收取管理费和部分收益提成,无论行情涨跌都能保持收益。也正是这种“旱涝保收”的资本运作模式,让幻方能够长期为深度求索输血,保持研发不以盈利为唯一目标的战略。(我就说没有功利心的学习,才可以放开手脚干吧,盯着 资产平衡表怎么干活。)回想当年英伟达尚未对华限售时,幻方就能一次性购入上万块 A100 显卡组建超大规模算力集群。也正因为有这样的资金与硬件后盾,DeepSeek 才敢一路高歌猛进。对于深度求索来说,他们的目标或许不只是赚“快钱”,而是想要真正实现通往更广阔的 AI 星辰大海。
Q2:DeepSeek-R1 又是什么?为什么最近大火?
DeepSeek-R1 是深度求索最新发布的“深度推理模型”,也是最近全球 AI 圈的热门话题。 不少人会拿它和 GPT4o 相提并论,但严格来说,两者并不在同一个维度上。
GPT4o 属于多模态通用模型,可处理文本、图像、语音、视频,甚至还能输出多种媒体形式。
而 DeepSeek-R1 的定位更像是专注文本与逻辑推理的“大脑”,它和 OpenAI 的 o1 模型 才是真正的一对“正面交锋”。
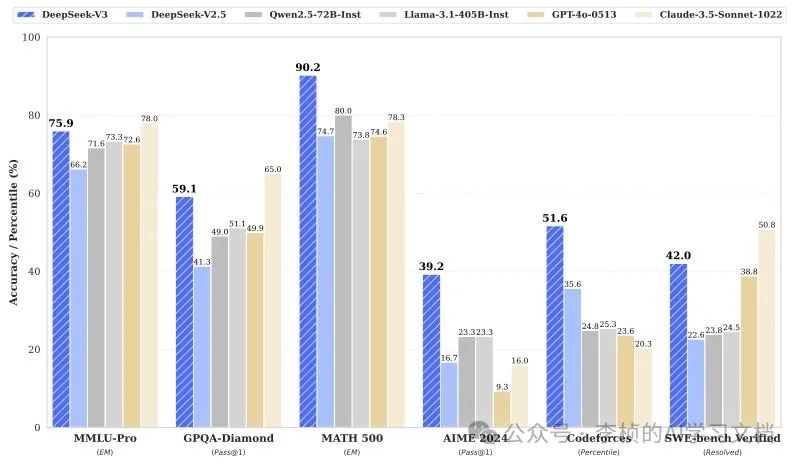
先前很多文章曾详细介绍过 OpenAI o1,这款模型被业内普遍认为是“进入下一代 AI 时代的通行证”。现在回头看,DeepSeek-R1 的出现,就是要在这一高阶推理和语言理解的赛道上,与 OpenAI 正面竞争。 从各方跑分来看,DeepSeek-R1 与 o1 几乎持平,推理速度和可靠性也相差无几,且 DeepSeek-R1 一上线便实现开源,加之低廉的 API 定价策略,无怪乎会令 Meta、OpenAI 等美国科技公司彻夜难眠。
相关链接:
- HuggingFace 模型地址:https://huggingface.co/deepseek-ai
- R1 论文链接:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
可以说,DeepSeek-R1 的发布,再次巩固了深度求索作为“价格屠夫+技术黑马”的双重地位,引发了全球研究机构和资本市场的又一轮“震荡行情”。
Q3:普通人想用 DeepSeek-R1,该从哪里开始?
深度求索官方在推出 DeepSeek-R1 的同时,也面向开发者和普通用户提供了多种使用途径:
- 网页版本
- 网址:https://chat.deepseek.com/
- 网页端的操作方式非常简洁,只需在对话框中输入问题即可。
- 当你在选项中勾选“深度思考功能”后,就会调用 R1 模型进行深度推理;如果不勾选,调用的则是相对更通用的多模态模型 v3(即类 GPT4o 的版本)。
- 应用商店 App
- iOS、Android 版本均已上线,直接在相应商店搜索 “DeepSeek” 即可下载安装。
- 功能与网页端大同小异,目前免费使用,但由于用户量激增,偶尔可能出现无法连接或服务器断线等情况。你可以在 https://status.deepseek.com/ 查询服务器状态以确定是否是官方问题还是个人网络原因。
-
- 当然DeepSeek 也存在问题,上下文过长, 会产生无法执行的问题。
- 最近也有黑客恶意攻击,以及测试人数增多等多个问题,导致用一下就断,大家有可能拿不到那么好的体验。
- API 与模型开源
注意: Coze 现在的模型应该是
DeepSeek V3 这个模型,不是推理模型 R1,学习智能体的小伙伴可以等一下,才会用到。
- 如果你是开发者,完全可以直接调用官方开放的 API,或在 HuggingFace 下载开源模型进行本地化部署。
- 价格仍然是 DeepSeek 的一大优势,相比其他同档次模型,R1 的 API 费用非常“亲民”。如果你有量级庞大的需求,比如企事业单位、科研院所等,DeepSeek 也提供了企业版本与私有化部署服务可供选择。
- “我是谁”(也就是你的背景信息)
- “我想要达成什么目标”
- “我是一个小学生。” 将这句话放在请求前面,相当于你先告诉模型:“请你按照小学生的理解程度给我解释问题。” 模型就会立刻切换到低门槛、易理解的表达方式。
- 如果你觉得“小学生”有点过于简单了,可以说“我是一个初中生/高中生/对某领域只有一点基础的人”等等。这样,R1 在给你回复时会更贴近你的认知水平,避免“高深术语”让你抓狂。
- 如果你要让它分析最近财报、美元指数,或者想让它根据网络搜索最新资讯进行综合评估,它确实做得到。
- 实际体验中,也可能有些资料抓取不完整或理解不全面,但相比只能“闭门思考”的推理模型,R1 这点已经是非常大的突破。
- 当训练与推理成本更低时,大模型的应用门槛便降低了,进而会鼓励更多公司、更多个人去探索 AI 的可能性,刺激更广泛的商业落地。
- 一旦需求暴增,整体算力的消耗反而会继续扩大,不见得就“神话崩塌”。至于股市短期的涨跌,本就受多重因素影响,DeepSeek 只是时间节点凑巧,成了舆论的“背锅侠”。
- 如果你担心它的回复太晦涩,那就告诉它你是小学生水平或初学者;
- 如果你希望它写作风格独特,那就直接说明模仿某位作家的笔调;
- 如果你要它结合最新新闻做分析,也可利用它的联网能力完成实时搜索。
总之,DeepSeek-R1 的使用门槛并不高。对个人用户而言,挑选网页端或 App 就足以满足日常咨询、学习与拓展;对于具备开发能力的团队,则可以直接将 R1 集成到各类场景中。
Q4. 如何与 DeepSeek-R1 对话?
先要明确的是,DeepSeek-R1 是一款偏重“深度推理”的模型,它并不像那些“通用聊天大模型”那样,一上来就能和你唠家常、胡侃海聊。如果你用对待 GPT4o 的方法去和 R1 沟通,尤其是那种带有严格结构化提示词的方式,很可能得不到理想效果。
1. R1 并不“自作聪明”
几个月前,OpenAI o1 发布时,我第一反应就是用以前的 Prompt 写法(“你是一个 XX,帮我按照 1、2、3 步骤完成什么什么”),结果对话质量非常糟糕,几乎让我误认为它是“废物”。后来才发现,o1(和 R1 一样)更像是一个需要你主动说明目标的“资深员工”,而非随时陪聊、什么都能接话的“通用客服”。
海外曾有篇很火的文章标题就叫 “o1 isn’t a chat model (and that’s the point)”,强调的正是这个道理。它的思路跟 R1 一脉相承:
“请先清晰地告诉我想做什么,别用那些又长又繁琐的任务描述去捆住我的思路。”
2. 放弃“我是 XXX,你要按 1、2、3 步来执行”式写法
传统大模型的 Prompt,往往被教导要写得极其详细,包括“你扮演什么角色”“我要做什么任务”“输出格式怎样”“按照固定步骤执行”等等。但对于 R1,其实大可不必。 你越是过度限制它,反而让它失去“自我推理”和填补信息空缺的能力。R1 不傻,它只是不知道你心里在想什么。如果你把所有思路、想法、背景,都抛给它,让它来推断和补全,常常会收获更令人惊喜的结果。
3. 最核心的 Prompt:你是谁 + 你的目标
把 R1 当作一个能力超群、但需要明确目标指令的“得力干将”。对话时,你需要告诉它:
其他那些眼花缭乱的框架或步骤,都可以先舍弃。背景信息给得越充分,它越懂你的处境;目标表述越清晰,它越能锁定关键问题,并通过它内建的推理能力给你做出更有针对性的解决方案。
简言之:
“把思维定式扔掉,用普通人能够理解的‘人话’,告诉 R1:你是谁、你想干嘛,就够了。”
句句写在了了我的心趴上, 我的天呢! 你再看看,调优做的比较好的 KIMI, 通义千文
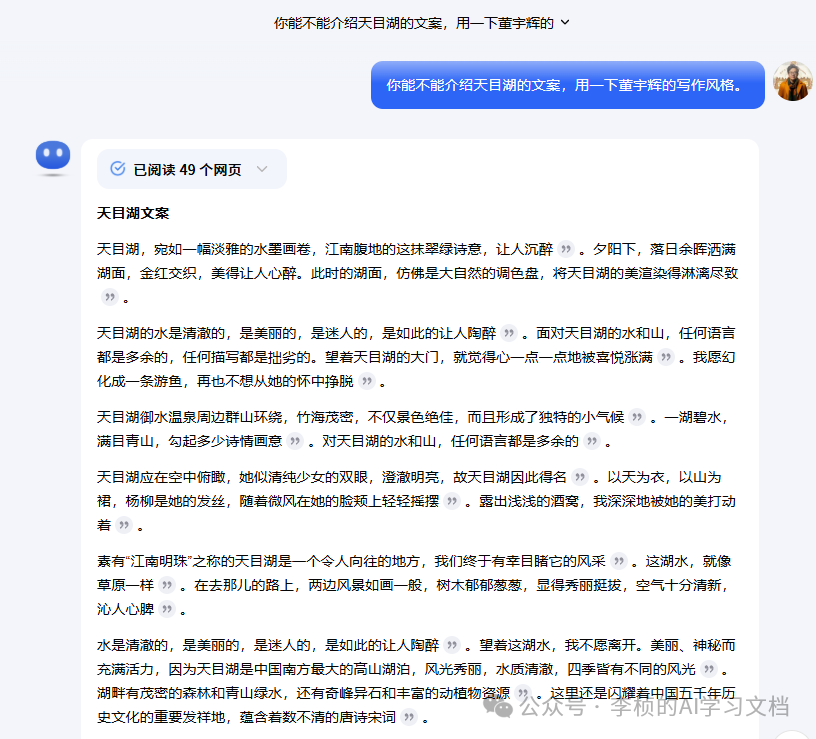
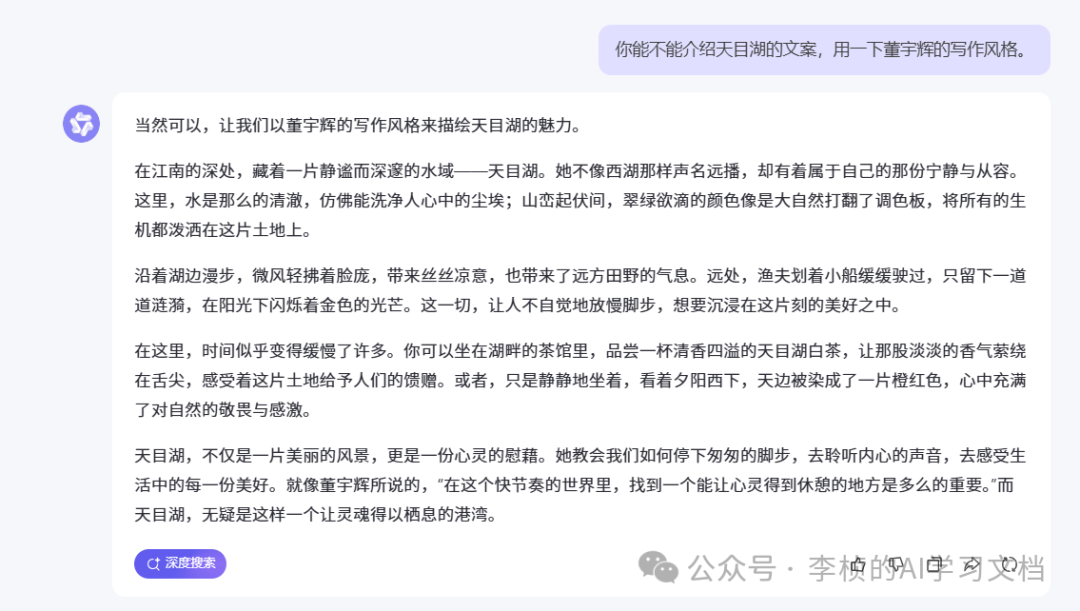
这种深度思考的模型确实厉害!
以前还要教给 AI 董宇辉的行文手法是这个样子的:
董宇辉风格核心要素提炼 (提示词)
诗意化叙事
→ 将风景转化为情感容器
→ 用通感打破物理界限
时空折叠手法
→ 历史与现实的蒙太奇剪辑
→ 具象场景与抽象哲思的量子纠缠
人文精神锚点
→ 以经典文学为暗线(陶渊明、苏轼的意象投射)
→ 对现代性的温柔批判
细节:
- 每段须包含一个动词的陌生化使用(钟声「掉」进湖心/萤火虫「读」湖)
- 禁止使用「美如画」等陈词,改用文物质感比喻(碎成青瓷纹路)
- 保持15-25字/句的呼吸感韵律现在完全不用的, 真的是一个巨大的进步。 我可能之后,真的看呆了。
五。 看不懂 R1 的输出怎么办?
有些人发现 R1 回复的内容专业术语太多、概念复杂,一时不知所云,常调侃说:
“这家伙能不能 ‘说人话’?”
其实,这既不是 R1 的锅,也并非只有推理模型才会面临的问题。根源在于模型并不了解你的知识背景和理解水平。如果你在 Prompt 中阐明了“我目前处于什么水平”,它就会自动进行话术调整,把专业内容用“更朴素通俗”的语言讲出来。

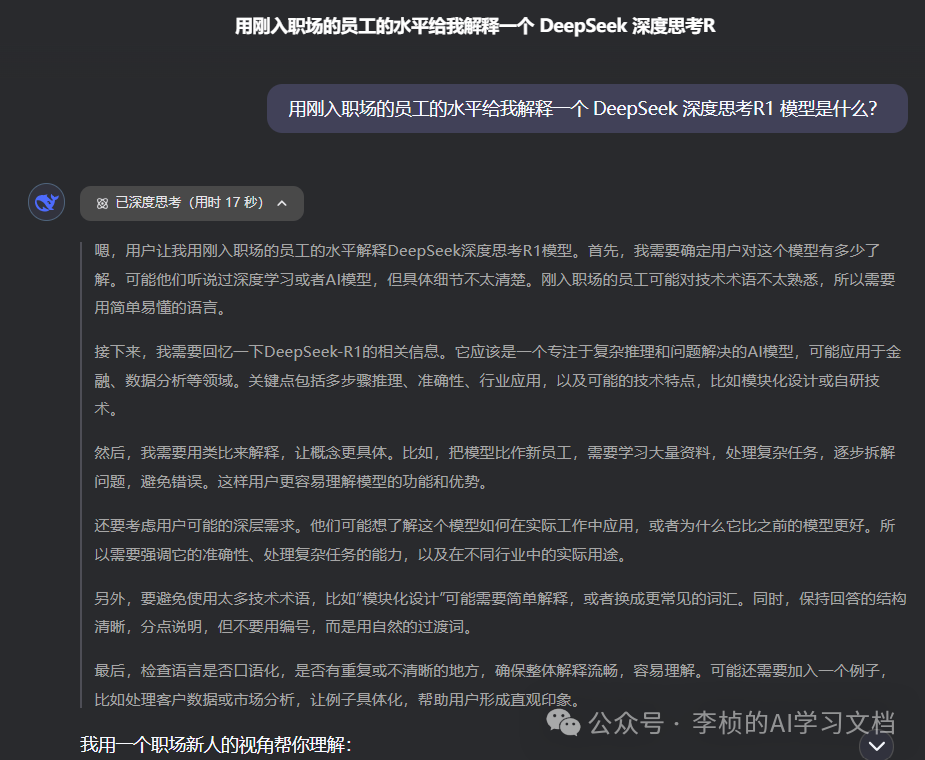
教大家一招“自降身份”Prompt:
举例来说,我想让 R1 解释大模型中的“RL”是什么。如果不先说“我是个小学生”,它可能直接来一段专业论文式的描述,看得人头疼。然而,只要一加上这句,自降身段,R1 立刻就用通俗易懂的方式举例说明,让我瞬间明白。
六。 R1 的写作能力真有传说中那么强?
与传统看重推理与计算的 AI 模型相比,DeepSeek-R1 在中文写作方面的表现相当亮眼。 过去,我们普遍认为各大模型的写作水准都差不多,“要不就是一团糟,要不就是太过程式化”,唯有 Claude 在某些场景中稍显突出。然而,R1 这次一鸣惊人,不仅逻辑严谨,还能相当灵活地模仿各种文风,明显拉开了差距。
1. 文风模拟:信手拈来
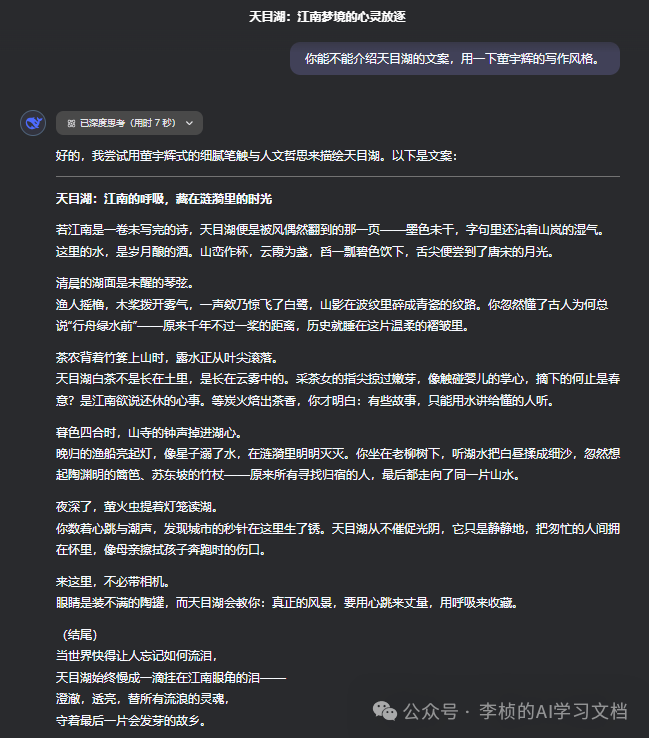
还是说回董宇辉风格的天目湖这篇文章。
天目湖:江南的呼吸,藏在涟漪里的时光
若江南是一卷未写完的诗,天目湖便是被风偶然翻到的那一页——墨色未干,字句里还沾着山岚的湿气。
这里的水,是岁月酿的酒。山峦作杯,云霞为盏,舀一瓢碧色饮下,舌尖便尝到了唐宋的月光。
清晨的湖面是未醒的琴弦。
渔人摇橹,木桨拨开雾气,一声欸乃惊飞了白鹭,山影在波纹里碎成青瓷的纹路。你忽然懂了古人为何总说“行舟绿水前”——原来千年不过一桨的距离,历史就睡在这片温柔的褶皱里。
茶农背着竹篓上山时,露水正从叶尖滚落。
天目湖白茶不是长在土里,是长在云雾中的。采茶女的指尖掠过嫩芽,像触碰婴儿的掌心,摘下的何止是春意?是江南欲说还休的心事。等炭火焙出茶香,你才明白:有些故事,只能用水讲给懂的人听。
暮色四合时,山寺的钟声掉进湖心。
晚归的渔船亮起灯,像星子溺了水,在涟漪里明明灭灭。你坐在老柳树下,听湖水把白昼揉成细沙,忽然想起陶渊明的篱笆、苏东坡的竹杖——原来所有寻找归宿的人,最后都走向了同一片山水。
夜深了,萤火虫提着灯笼读湖。
你数着心跳与潮声,发现城市的秒针在这里生了锈。天目湖从不催促光阴,它只是静静地,把匆忙的人间拥在怀里,像母亲擦拭孩子奔跑时的伤口。
来这里,不必带相机。
眼睛是装不满的陶罐,而天目湖会教你:真正的风景,要用心跳来丈量,用呼吸来收藏。
(结尾)
当世界快得让人忘记如何流泪,
天目湖始终慢成一滴挂在江南眼角的泪——
澄澈,透亮,替所有流浪的灵魂,
守着最后一片会发芽的故乡。
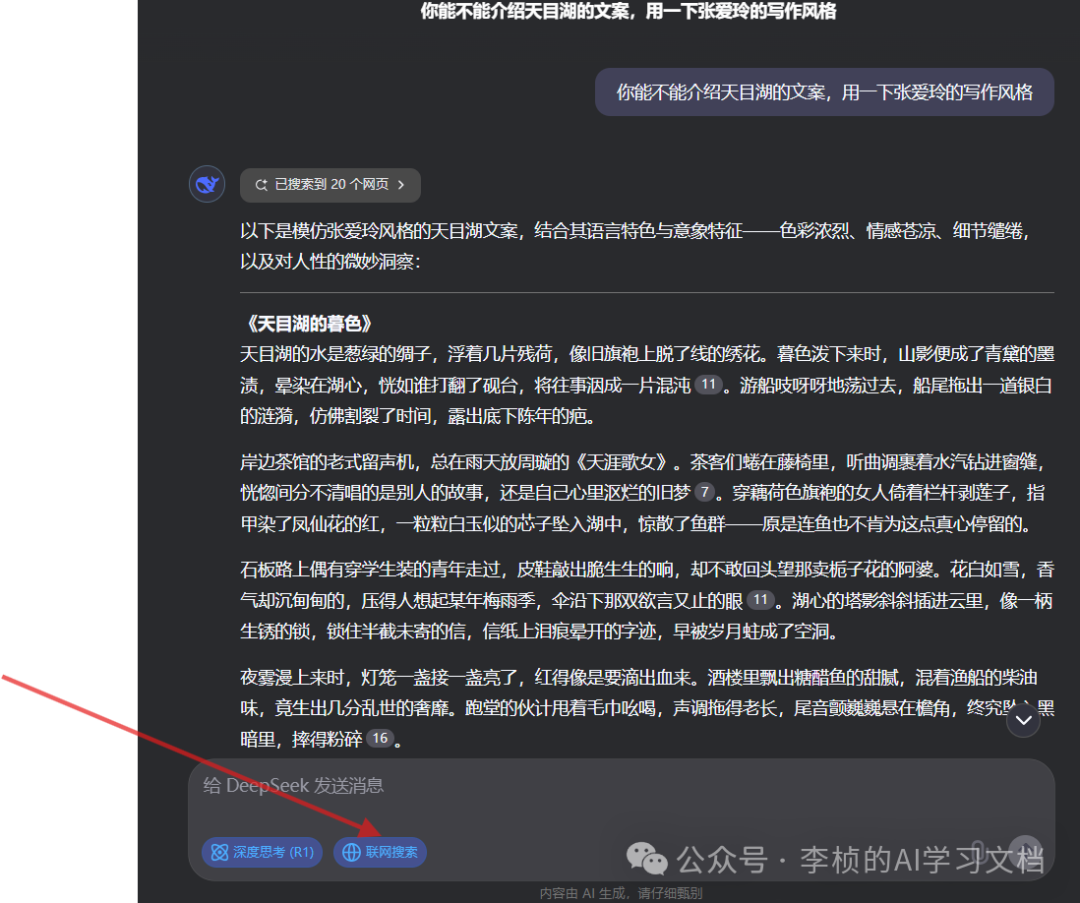
只要给 R1 一个简单的指令:“你能不能介绍天目湖的文案,用一下董宇辉的写作风格。”它就能写出一篇神似董宇辉文风的文旅介绍,颇具个人特色。 同理,如果你要它模仿张爱玲风格写首词,它能马上写出张爱玲风格的作品。虽说未必能与真正的张爱玲一较高下,但确实已达到了一个很惊人的水准。
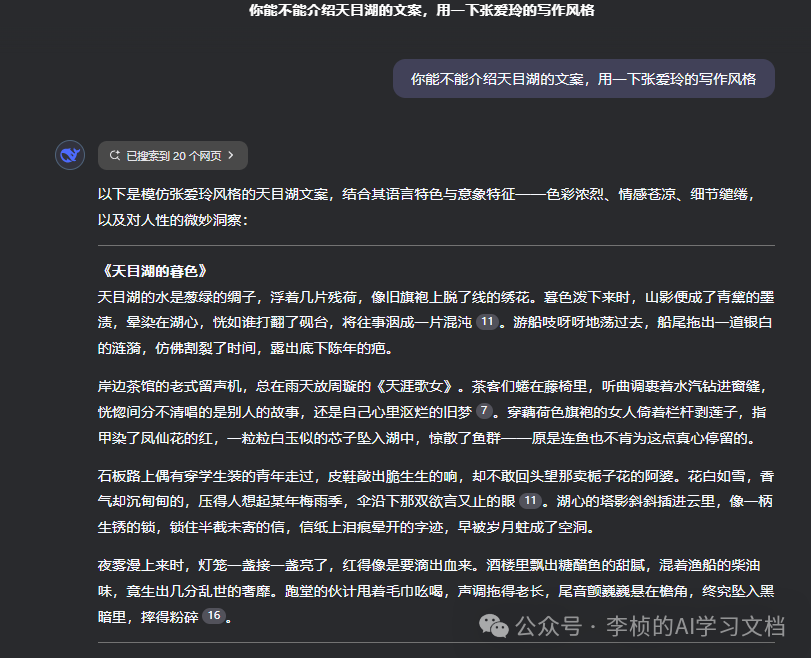
2. 一句话就够,不必“教”它该怎么写
在测试时,我并没有给 R1 详细描述“张爱玲是怎样写作的”,只是一句简单提示,它就能推理、整理并输出较为贴合该风格的文字。简洁 Prompt + 高度自由,这就是 R1 与传统大模型的明显差异之一。
七。 R1 能够联网吗?
众所周知,大部分推理模型(比如 OpenAI o1)通常不带联网功能,或对外部数据的获取存在限制,这就导致它们的知识库经常停留在某个时间点,并且无法即时处理最新新闻、数据或文档。
DeepSeek-R1 则是少数“推理 + 联网”并行的模型。
举个例子:
“我想用鲁迅的文风写一篇 2000 字左右的公众号文章,分析 2025 年春节档哪几部电影可能会爆,别给我搞成条理化提纲,就一气呵成。”
在执行这个请求前,R1 会对网络信息进行检索(比如当下有哪些电影已经定档或有风声要上映),然后结合鲁迅的写法给出一篇类似杂文风的讨论文。从我测试的结果来看,整体质量颇高,读起来还真有那么几分神似“鲁迅杂感”的味道。
八。 算力神话崩盘了?
最近,A 股和美股中与“算力”相关的板块双双大跌,许多人把原因直指 DeepSeek-R1:“因为大模型的推理成本被大幅降低,所以算力需求不再紧俏,算力神话要崩了。” 但这其实是一种误读。历史上,工业革命时期就出现过“杰文斯悖论(Jevons Paradox)”,说的是当蒸汽机效率提升后,看似煤炭需求应该减少,可事实却是需求量反而增长。这是因为效率提升后,使用成本下降,反过来会刺激更多场景和更大规模的使用。
放到 AI 领域也是一样:
综合来看,算力需求大概率还会走上升趋势。DeepSeek-R1 的发布,只是让人们意识到:未来的 AI 不一定都烧钱,技术革新也许会让“高质低耗”成为可能。但这和算力生态的长期需求并不矛盾,反而很可能是新一轮扩张的催化剂。
当我们和 DeepSeek-R1 这样定位于“深度推理”的大模型对话时,最关键的不是去制定复杂的对话结构,而是明确你的目标、坦陈你的背景和需求。
这种更高自由度、更多样化的表达和能力,正是 DeepSeek-R1 相较于传统模型的差异化优势。而它的出现,也让我们再度目睹了 AI 领域那令人震撼的进步速度。
时代在高速演进,或许只要再给它一些时间,我们将看到更多“天马行空”的功能落地,让 AI 真正成为我们最强的助力,而不是仅仅停留在“聊天”层面。无论在算力还是应用层面,这场革命都才刚刚开始!
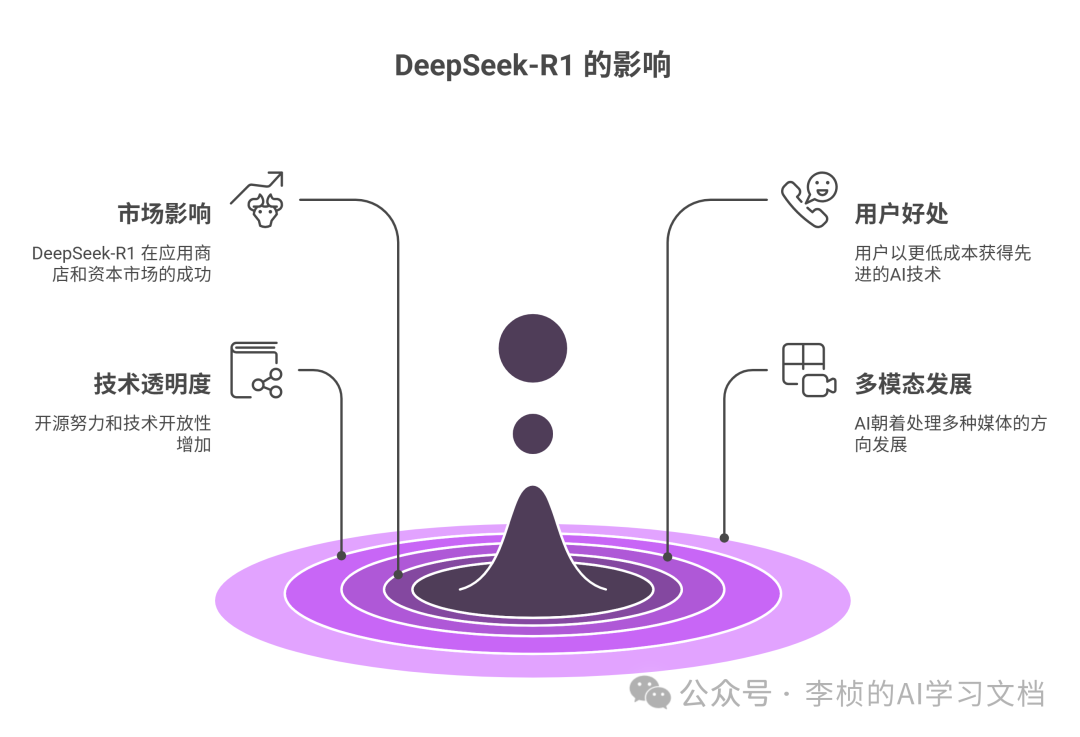
在这个 AI 快速迭代的时代,DeepSeek-R1 的出现再次说明:价格与开源策略依然是推动 AI 平台竞争的关键因素之一。短短几天之内,DeepSeek-R1 不仅成功“攻占”了各大应用商店榜单,还让资本市场对全球算力供应与 AI 格局产生了新一轮的震动。 对于普通用户而言,这样的竞争未尝不是好事:我们可以以更便宜的价格、更便捷的方式体验到最新的 AI 技术。同时,随着更多公司加入 AI 研发与开源行列,技术也会越来越透明、发展越来越多样化。 当然,这只是一个开始。DeepSeek-R1 以深度推理见长,而 GPT4o 等多模态模型也在不断更新迭代。可以预见,未来 AI 会朝着多模态、大一统的方向更快地演进。或许不久之后,我们就能看到一款既能完成高阶推理、又能处理文本、语音、视频甚至 AR/VR 场景的真正“全能大模型”。 对我们每一个人来说,迎接 AI 并不只意味着接受技术本身,也意味着思考如何在技术浪潮中与它共生、协同与前进。DeepSeek-R1 的火爆,为这个新春增添了一抹浓重的科技色彩。接下来,AI 的星辰大海究竟会有怎样的奇观与挑战,值得我们持续关注与期待。
愿这篇文章为你带来一些新的思考,也希望在这个充满机遇与变革的时代,我们都能用好、用对 AI,去探索更多未知的可能性。
相关文章
