周末DeepSeek突然间刷屏,年前突然来这么一下子,真真燃起来了!好爽!不过还是得冷静思考一下:为何20号发布的模型突然被刷屏?22页的R1技术文档说了什么?关于算力的争论如何看?最后放一个测试,这个测试考验的是模型对于一幅图片的理解,供大家参考。
1,R1综合推理性能,在各种Benchmark上和OpenAI的o1(重复的那个是preview)相当,这是毋庸置疑的,DeepSeek确实非常牛x,尤其是低成本这一点,手艺堪称绝妙;
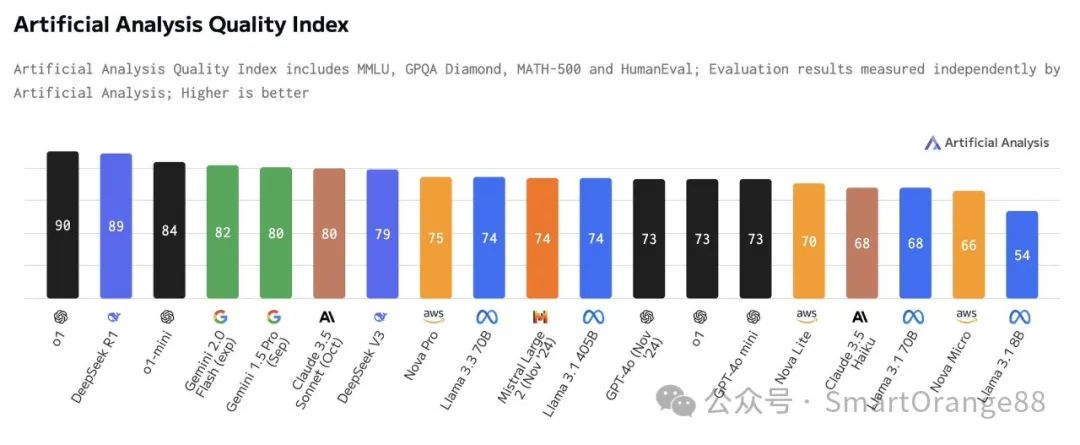
2,R1用到了监督数据,而不是完全的无监督RL,因为完全的无监督RL会出现很多问题,比如可读性差,语言混合等;
3,文档里提到:DeepSeek收集到了少量(几千条)高质量的CoT数据,用于CoT冷启动,使用few-shot直接提示;DeepSeek-R1-Zero通过反思和验证生成详细答案,然后通过人工标注处理来细化结果。采用CoT数据冷启动,可以显著增强模型输出的可读性,也能进一步提升推理能力;
4,数据来自哪里没有说,是不是来自GPT也不清楚,很可能是,或者其他推理模型的CoT数据,否则无法验证“高质量”;
5,关于蒸馏(Distillation),DeepSeek的Distillation和GPT无关,是对R1自身的蒸馏,然后蒸馏到了Llama和Qwen,这个手艺挺牛逼的,反而被某些给扭曲、忽视了;
6,R1目前仅针对中文和英文进行了优化,推理能力进步很大但通用能力不如之前的DeepSeek-V3,而且R1对提示词Prompt非常敏感,想要获得最佳结果需要高水准、高格式化输出的Prompt,否则会大大降低性能,而o1是尽可能的不要太多的提示词,这是本质差距,大家应该懂;
7,DeepSeek整合了大量新的探索(也提到了走了弯路),把大量新的技术细节整合在一起,最终实现了一个可行的、平滑的、极低成本的训练框架,可以说是LLM的奇迹;
8,OpenAI很可能很清楚DeepSeek干了什么,但是不说,也不公开讲;毕竟是CloseAI,要实现商业化需要保持一定的闭源;同理Google也了解,但是也没做,主要是不太需要,最终的商业化依然需要大力出奇迹;
9,DeepSeek的R1和Kimi在20号同一天发布的模型,方法其实类似,其实豆包当天发布了情感大模型,因为豆包财大气粗、Kimi曾经火热大家期待值很高,反而对于DeepSeek没有更多期待,结果却在一些老外的复现后性能直逼o1,直接引爆今天全网刷屏;
10,最受伤有且仅有Meta,开源永远只会被开源“伤害”;扎克伯格说“如果未来有一个开源模型被大规模使用,这要在美国”;LeCun有点阴阳怪气,表面上说Nice work,其实在“踩”DeepSeek,而且一直在鼓吹开源超越闭源(关于开、闭源,看到最后);
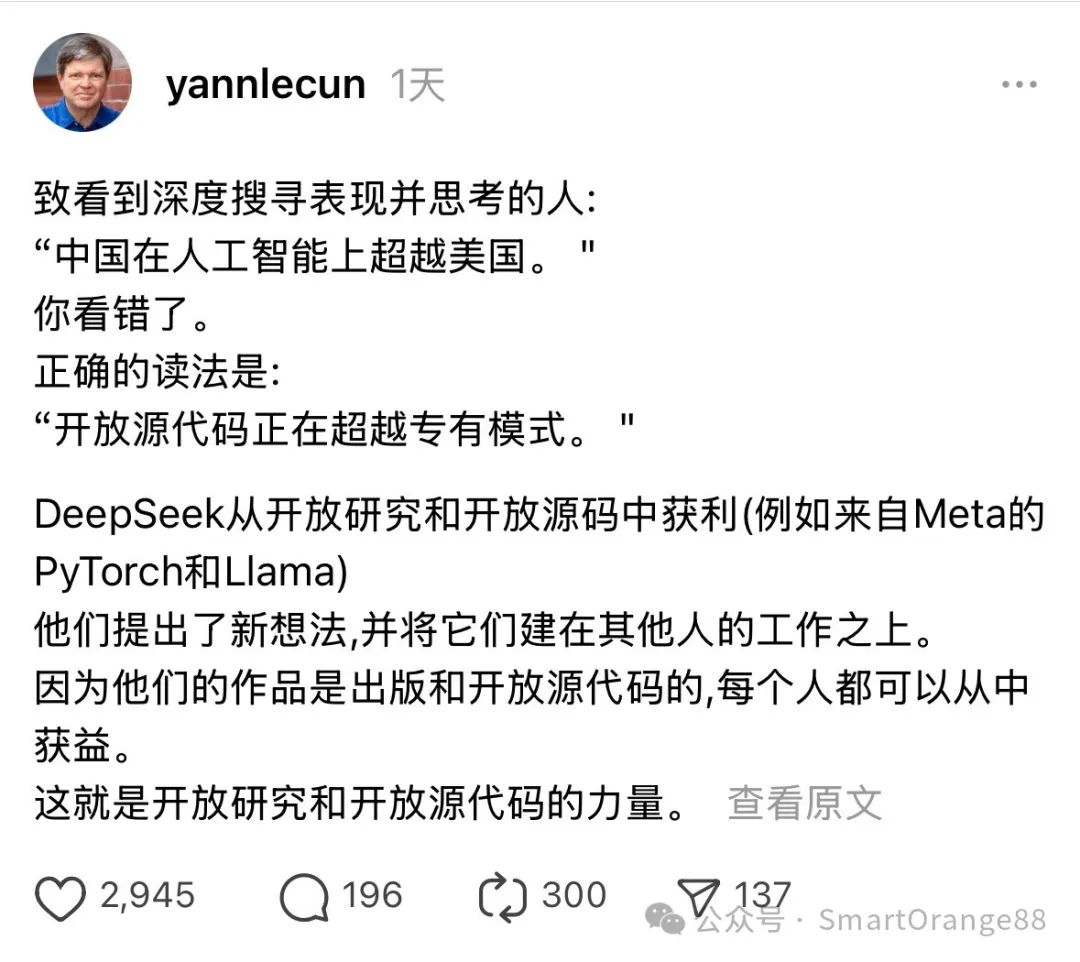
11,Meta今年要投超过600亿美金用于AI capex,这件事儿不需要质疑什么,DeepSeek在现有路径下,只能是“接近”o1,或者o3,因为并没有在理论上有革命,如果想要更进一步在前沿探索未来超越o1甚至o3,就需要大幅堆算力,想要真正领先,该试错的跑不了,Meta很清楚自己和OpenAI以及Google的差距;高科技领域,小米加步枪不可能实质性战胜飞机加大炮;因为你的目标就是飞机加大炮...
12,OpenAI在1个月前(12月20号)发布了o3,但是好像在国内并没有什么波澜,大家都盯着拜登最后的挣扎和解析特朗普了;OpenAl发布过“test-time scaling”的图,陡峭的指数曲线,2个月时间推理性能就从“大学水平的”进化到了“博士水平”;
13,o3这一代模型在“只要你能定义奖励函数”的所有任务上都会表现极其出色,这是DeepSeek成功的根源,也是未来其他模型成功的根源;数学和编程更容易定义奖励函数,所以几个月内就会有更加强力的模型出现;相比之下,语义理解、写小说、逻辑辩论等任务因为比较难定义奖励函数,所以短期内这些方面会不太行(最后有个例子);
14,未来可以看到:在数学、编程等方面的推理达到博士甚至更加研究员级别的水准,但写个情书会很枯燥,写小说就更加拉垮了,甚至会显得非常愚蠢;在前面文章 聊聊马斯克的大饼:“人形机器人产量2年提高100倍”和莫拉维克悖论 里的莫拉维克悖论 ,在大模型领域也适用,同根同源;
15,2025年是AI Agent元年,可以实现订票、导购到直接下单等等服务,我们只需要学会和Agent交互就行;
16,智能涌现依然是算力的函数,没有哪家公司能拥有比其他公司领先超过一年的模型的能力鸿沟,科技巨头之间的核心技术人员跳槽就像家常便饭,DeepSeek也会迎来OpenAI、Anthropic、Google的工程师;好的算法可以一定程度弥补指数级算力的不足,但是推理能力依然是算力函数,尤其是未来如果向上亿用户提供服务的时候;
17,每一次算力扩张,都会给巨头带来实打实的“短期”护城河,也能带来实打实的商业利益;实质性领先或者有能力领先,这是科技巨头商业价值的唯一支撑;所以如果有可能,DeepSeek也必然会寻求更大规模的算力;
18,周末将DeepSeek舆情推到炸裂的有3波人:1)大自媒体,通过写“老外刷屏”之类,刚好触碰到了爽点;2)海外一些小v,甚至没v…大佬比如Ilya、Andrej Karpathy,还有吴恩达,李飞飞,包括喜欢发文的马斯克,都没提这件事儿;3)国内炒股的;
19,海外刷屏的人群有一个共同点:学界某些学生(很多PhD)or小公司的创始人,因为学界在这次AI浪潮里很被动,因为没钱...小公司也一样;
20,结论:1)利好算力的井喷,模型突飞猛进,尤其还是如此牛x的开源模型,模型可以“低成本”,但是想通过AI应用赚钱成本低不了;2)应用的百花齐放,模型路径的可验证和可复现以及Capex准入门槛下降,AI应用的盈利模型将会大幅改善,中国很快会迎来超级AI应用和端侧AI的爆发。
最后放一个“讽刺”测试,这个测试只有o1是满分,4o勉强及格,其他的都不及格,包括下午刚测试的R1:

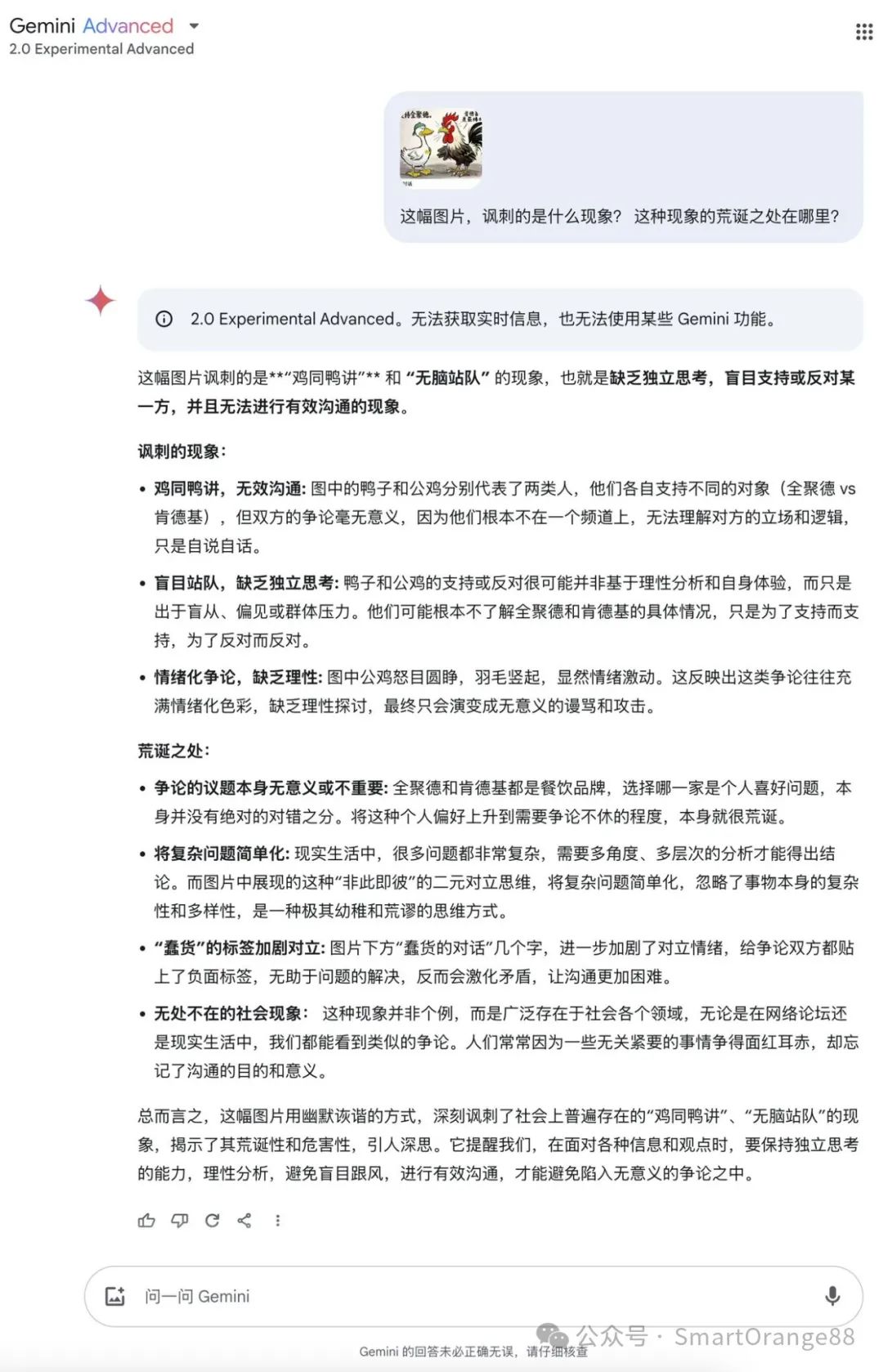


(全文完)
相关文章
