今天我们聊一下来自阿里巴巴通义实验室的 Qwen3 Embedding 系列模型,如果你一直在关注大语言模型(LLM)的进展,尤其是它们在信息检索、问答系统、RAG(检索增强生成)和智能体(Agent)等领域的应用,那你一定知道高质量的文本表示(Embedding)和重排(Reranking)有多么重要。
这篇名为《Qwen3 Embedding》的技术报告,就像为我们揭开了一层面纱,让我们得以一窥Qwen3这个“大家族”如何在文本理解的基石——Embedding 和 Reranking 技术上再进一步,甚至可以说是“卷”出了新高度。
一、Qwen3 Embedding 是什么?为什么重要?
在深入技术细节之前,我们先来搞清楚两个基本概念:
1.1 文本嵌入 (Text Embedding):简单来说,就是把我们日常使用的文字(比如一个词、一句话、一段文档)转换成计算机能够理解和处理的数字向量。这个向量就像是文本在多维空间中的“坐标”,语义上相似的文本,它们的向量在空间中的距离也会更近。好的Embedding能够精准捕捉文本的语义信息。
1.2 文本重排 (Text Reranking):当搜索引擎或者问答系统初步召回一系列可能相关的文档后,Reranking模型会对这些文档进行更精细的打分和排序,把最相关的结果排在最前面,提升用户体验。
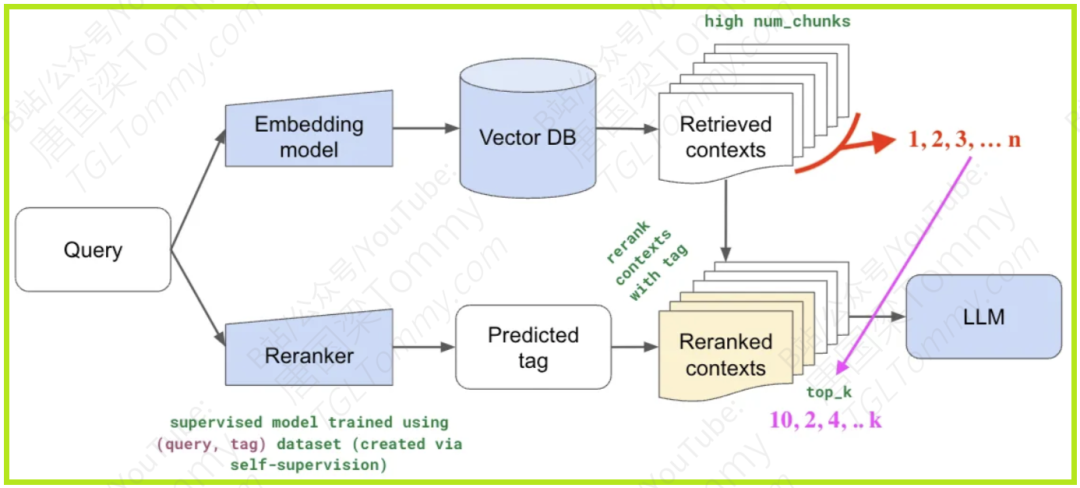
为什么Qwen3 Embedding的出现如此引人注目?
随着Qwen3这样强大的基础模型(Foundation Models)的出现,它们在多语言文本理解和生成方面展现出了惊人的能力。Qwen3 Embedding系列正是建立在Qwen3基础模型之上,旨在充分利用其强大的能力,解决现有技术的痛点。特别是在RAG和Agent这类新兴应用范式中,对Embedding的质量、效率和对指令的理解能力提出了更高的要求。比如,RAG系统需要在海量知识库中快速准确地找到与用户问题最相关的知识片段,以辅助LLM生成更可靠的答案。如果Embedding做得不好,召回的知识不准,那LLM再厉害也可能“无米下锅”或者“答非所问”。
二、核心亮点:Qwen3 Embedding 的“独门秘籍”
这篇论文介绍了Qwen3 Embedding系列模型的诸多创新之处,我们可以总结为以下几个核心亮点:
2.1 基于强大的Qwen3基础模型:
-
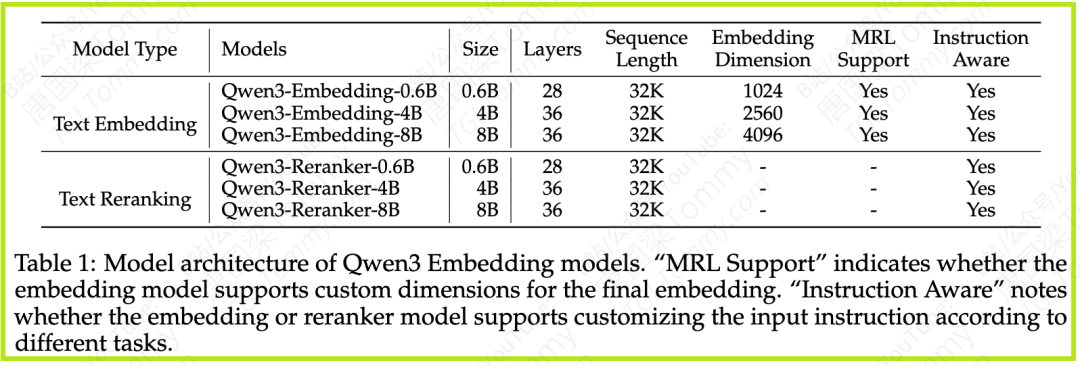
Qwen3 LLM本身就具备强大的多语言文本理解和生成能力。以此为起点,Embedding和Reranking模型天然就继承了这些优良特性。论文中提到了0.6B、4B、8B三种参数规模的模型,可以满足不同场景下对效率和效果的平衡需求。
2.2 创新的多阶段训练流程:
-
这不仅仅是简单的“预训练+微调”。Qwen3 Embedding的训练流程更为精细,结合了大规模无监督预训练、高质量有监督微调,以及巧妙的模型合并策略。
-
Embedding模型流程:
-
阶段1:大规模弱监督预训练:使用海量通过LLM(Qwen3自身)合成的文本对数据进行训练。
-
阶段2:高质量有监督微调:使用经过筛选的高质量合成数据和人工标注数据进行微调。
-
阶段3:模型合并:将阶段2中不同检查点的模型进行合并,增强模型的鲁棒性和泛化能力。
-
Reranking模型流程:主要包括高质量有监督微调和模型合并两个阶段。
2.3 LLM赋能的数据合成:
-
这可以说是Qwen3 Embedding的一大“杀手锏”。传统方法通常依赖于开源社区的问答对、论文等数据,这些数据在多样性、特定任务覆盖和低资源语言方面可能存在不足。
-
Qwen3 Embedding团队则利用Qwen3-32B模型直接合成了海量的、高质量的、多样化的训练数据。这些数据覆盖了检索、双语文本挖掘、分类、语义相似度等多种任务,并且可以精细控制任务类型、语言、文本长度、难度等维度。这种“自给自足”的数据生产方式,极大地提升了训练数据的质量和可控性。
2.4 模型合并策略:
-
在有监督微调完成后,论文借鉴了前人工作(如Li et al., 2024),采用了基于球面线性插值(slerp)的模型合并技术。通过合并微调过程中保存的多个模型检查点,可以进一步提升模型在不同数据分布上的鲁棒性和泛化能力。
2.5 灵活的指令遵循和维度表示:
-
指令感知 (Instruction Aware):无论是Embedding还是Reranking模型,都支持用户根据不同任务定制输入指令,使模型能够更好地适应特定场景的需求。
-
多表示层支持 (MRL Support):Embedding模型支持自定义最终输出的嵌入维度,这为不同应用场景下的效率和存储需求提供了灵活性。
三、技术深潜:模型架构与训练策略
现在,让我们深入了解一下Qwen3 Embedding和Reranking模型在技术上是如何实现的。
3.1 模型架构
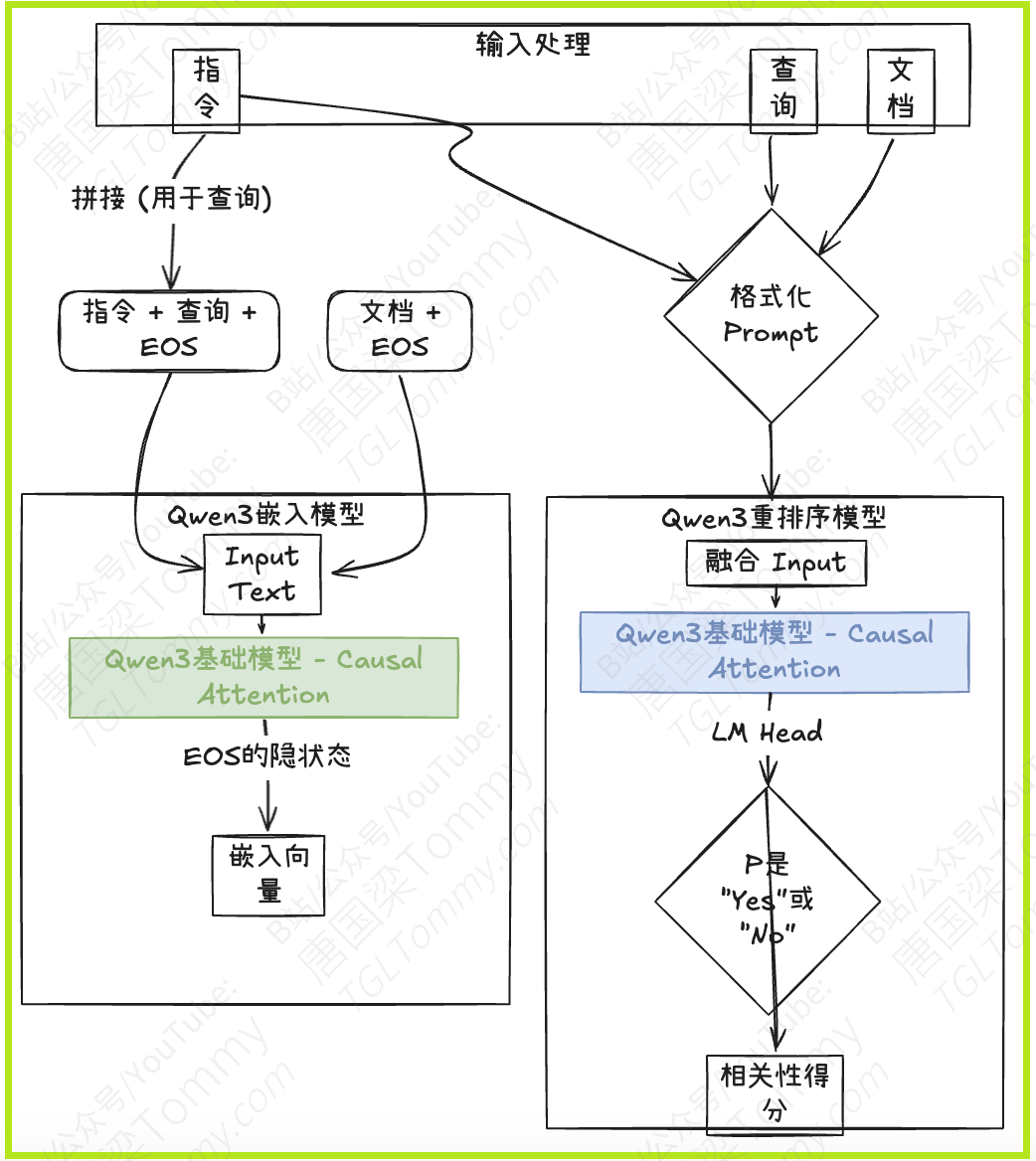
Qwen3 Embedding和Reranking模型都基于Qwen3基础模型的密集版本(dense version),并提供了0.6B、4B和8B三种参数规模。它们共享了Qwen3基础模型在文本建模和指令遵循方面的能力。
-
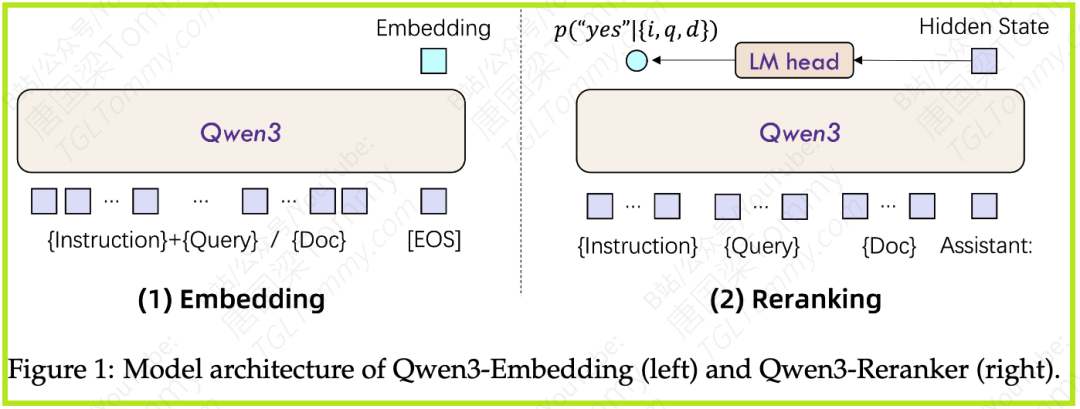
Embedding 模型:
-
采用的是具有因果注意力机制(causal attention)的LLM架构。
-
输入文本序列的末尾会添加一个特殊的
[EOS](End Of Sequence) 标记。 -
最终的文本嵌入向量取自最后一层网络对应于
[EOS]标记的隐藏状态 (hidden state)。 -
为了实现指令遵循,查询 (Query) 的输入格式为:
{Instruction} {Query}<|endoftext|>。文档 (Document) 则直接输入,不加额外指令。 -

-
Reranking 模型:
-
为了更精确地评估文本相似度,Reranking模型采用逐点(point-wise)的方式在单个上下文中进行处理。
-
同样支持指令遵循,指令会包含在输入上下文中。
-
模型将相似度评估任务构建为一个二元分类问题,即判断“文档是否满足查询和指令的要求”,输出“是 (yes)”或“否 (no)”。
-
输入格式遵循LLM的聊天模板 (chat template),具体如下:
-
最终的相关性得分通过计算模型输出“yes”和“no”的概率来得到。


3.2 创新的多阶段训练流程
如下图所示,Qwen3 Embedding 的训练流程精心设计,旨在逐步提升模型性能和泛化能力。
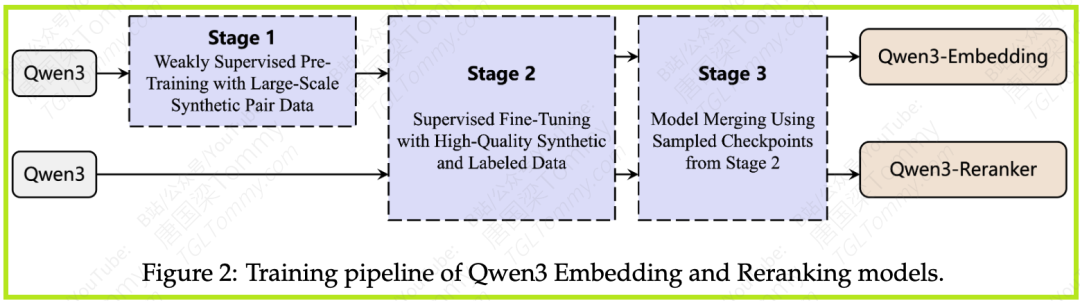
-
阶段 1: 大规模弱监督预训练
-
仅用于 Embedding 模型。
-
核心创新:与以往工作(如GTE, E5, BGE依赖于公开QA论坛、学术论文数据)不同,Qwen3 Embedding 直接利用Qwen3基础模型(Qwen3-32B)合成大规模的成对数据。
-
这种方法允许研究者在合成提示中任意定义所需数据的维度,如任务类型、语言、长度、难度等,从而实现了对数据质量和多样性的精确控制,尤其是在低资源场景和特定语言上。
-
合成了约 1.5亿对 多任务弱监督训练数据。
-
阶段 2: 高质量有监督微调
-
用于 Embedding 和 Reranking 模型。
-
核心创新:由于Qwen3基础模型性能卓越,其合成的数据质量非常高。因此,在这一阶段,研究者们选择性地将这些高质量的合成数据与传统的人工标注数据结合起来进行微调。
-
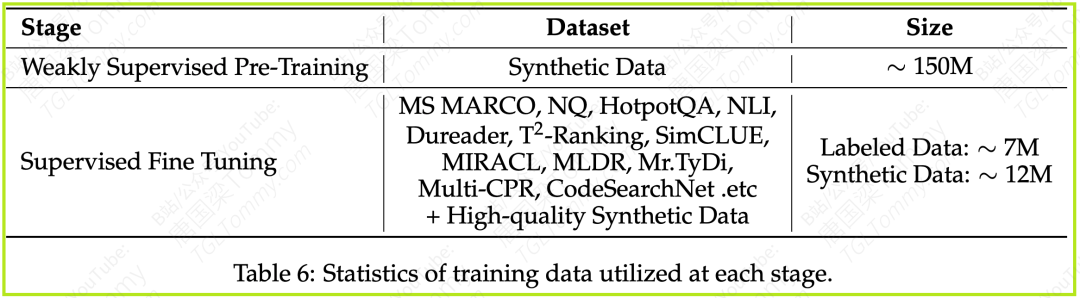
对于Embedding模型,他们从阶段1的1.5亿合成数据中,通过简单的余弦相似度筛选(保留相似度 > 0.7 的样本),得到了约 1200万对 高质量合成数据用于此阶段。同时也会使用公开的标注数据集(如MS MARCO, NQ, HotpotQA, MIRACL等,详见论文附录Table 6)。
-
Reranking模型则直接使用高质量的合成数据和标注数据进行此阶段的训练。
-
阶段 3: 模型合并 (Model Merging)
-
用于 Embedding 和 Reranking 模型。
-
在有监督微调完成后,采用基于球面线性插值 (slerp) 的技术,合并在阶段2微调过程中保存的多个模型检查点 (checkpoints)。
-
此步骤旨在提升模型在各种数据分布上的鲁棒性和泛化性能。
四、实战成绩单:令人瞩目的SOTA表现
理论讲了这么多,Qwen3 Embedding系列模型的实际表现如何呢?论文给出了一系列详尽的实验结果。
4.1 评测基准
-
文本嵌入模型:主要使用了 MMTEB (Massive Multilingual Text Embedding Benchmark) 进行评估。MMTEB是一个大规模、社区驱动的基准测试,覆盖超过250种语言,包含检索、分类、语义相似度、指令遵循、长文档检索、代码检索等多种任务。具体评估了:
-
MTEB (Multilingual) (Enevoldsen et al., 2025): 131个任务
-
MTEB (English, v2) (Muennighoff et al., 2023): 41个任务
-
CMTEB (Chinese MTEB) (Xiao et al., 2024): 32个任务
-
MTEB (Code) (Enevoldsen et al., 2025): 12个代码检索任务
-
文本重排模型:评估了三类检索任务:
-
基础相关性检索 (Basic Relevance Retrieval):在MTEB (English, Chinese, Multilingual) 和 MLDR (Chen et al., 2024) 上进行。
-
代码检索 (Code Retrieval):在MTEB-Code上进行。
-
复杂指令检索 (Complex Instruction Retrieval):在FollowIR (Weller et al., 2024) 上进行。
4.2 对比模型
对比了当前主流的开源文本嵌入模型(如GTE系列、E5系列、BGE系列、NV-Embed-v2、GritLM-7B)和商业API(如OpenAI的text-embedding-3-large、Google的Gemini-Embedding、Cohere的embed-multilingual-v3.0)。Reranking模型则与jina-reranker、mGTE-reranker、BGE-m3-reranker等进行了比较。
4.3 Embedding 模型表现
-
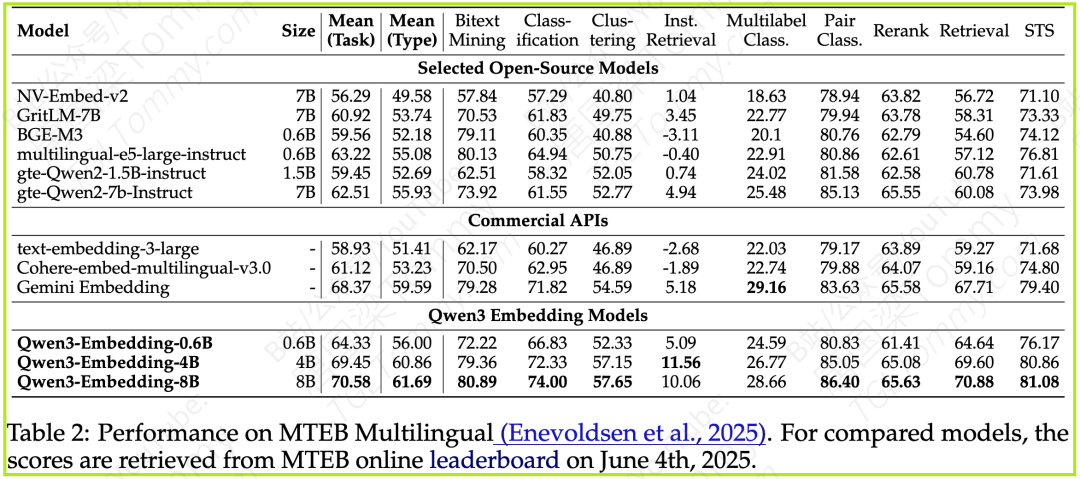
MTEB (Multilingual) - 平均任务得分
-
Qwen3-Embedding-8B 取得了 70.58 的高分,超越了所有对比模型,包括强大的 Gemini Embedding (68.37)。
-
Qwen3-Embedding-4B (69.45) 也表现出色,同样优于Gemini Embedding。
-
即便是最小的 Qwen3-Embedding-0.6B (64.33),也展现了极具竞争力的性能。
-
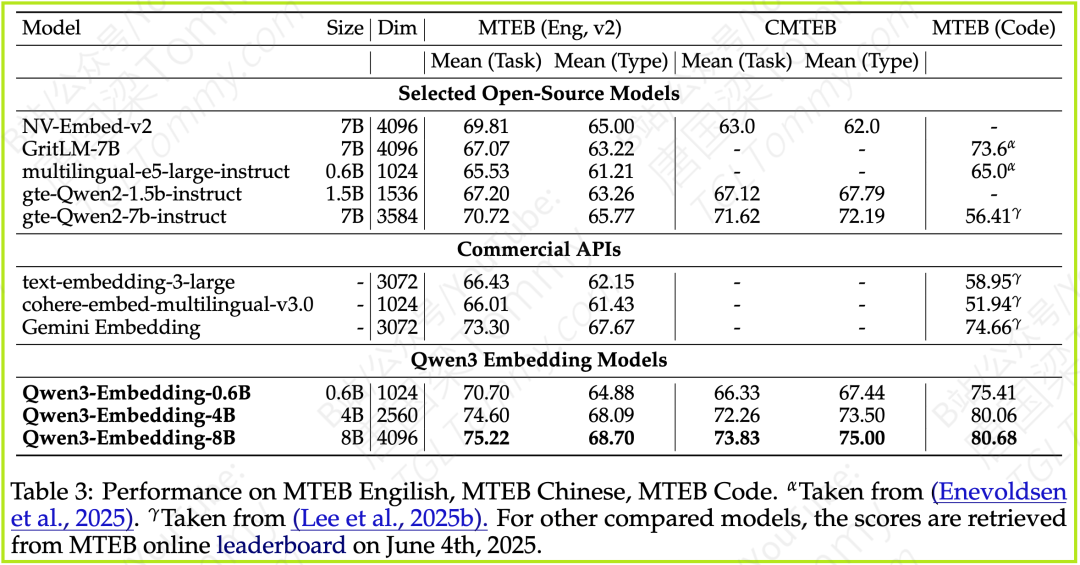
MTEB (English, v2), CMTEB (Chinese), MTEB (Code)
-
在 MTEB English (v2) 上,Qwen3-Embedding-8B (75.22) 和 Qwen3-Embedding-4B (74.60) 均超越了 Gemini Embedding (73.30)。
-
在 CMTEB (中文) 上,Qwen3-Embedding-8B (73.83) 表现最佳。
-
在 MTEB (Code) 上,Qwen3-Embedding-8B (80.68) 和 Qwen3-Embedding-4B (80.06) 大幅领先,Gemini Embedding 为 74.66。Qwen3-Embedding-0.6B (75.41) 也表现优异。
4.4 Reranking 模型表现
论文中,研究者首先使用Qwen3-Embedding-0.6B模型初步召回top-100的候选文档,然后应用不同的Reranking模型进行重排。
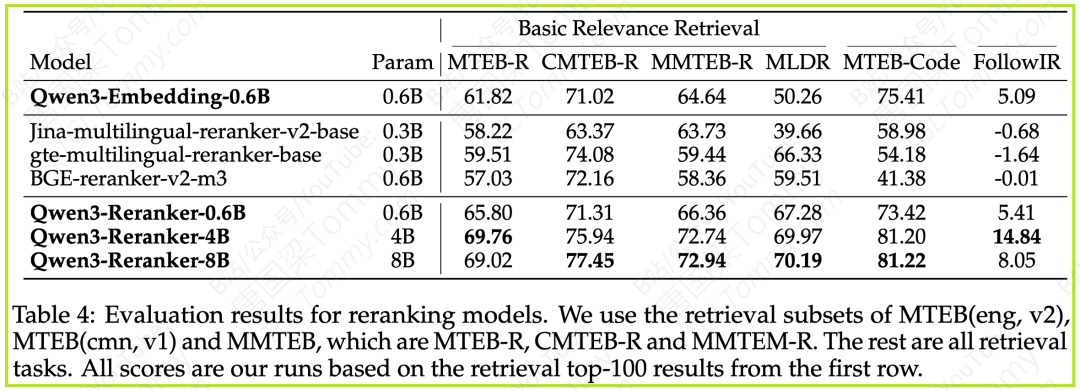
从结果可以看出:
-
所有三个Qwen3-Reranker模型都显著优于仅使用Embedding召回的性能,并且全面超越了其他基线Reranking方法。
-
Qwen3-Reranker-8B在大多数任务上取得了最佳性能,尤其是在CMTEB-R (中文相关性检索) 和 MTEB-Code (代码检索) 上优势明显。
-
Qwen3-Reranker-4B在FollowIR (复杂指令检索) 任务上表现非常亮眼,达到了14.84分,远超其他模型。
4.5 消融实验:探究成功的关键
为了验证训练流程中各个组成部分的有效性,论文针对Qwen3-Embedding-0.6B模型进行了一系列消融实验(在MMTEB, MTEB Eng v2, CMTEB, MTEB Code v1上的平均任务得分):
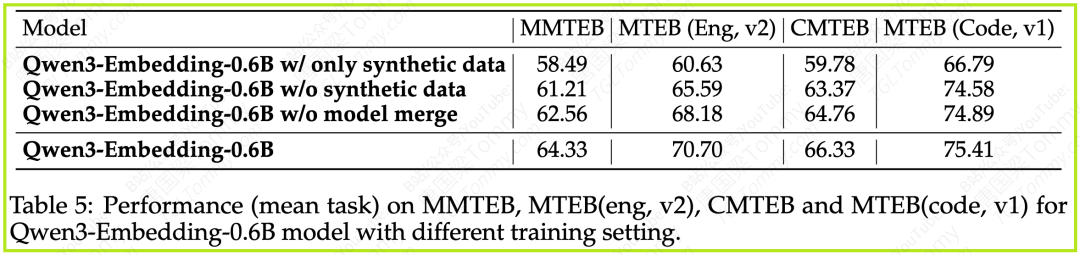
实验结果清晰地表明:
1️⃣大规模弱监督预训练(LLM合成数据)至关重要:
-
仅使用合成数据(第一行)就能达到不错的性能,说明LLM合成数据的潜力。
-
如果完全移除合成数据(第二行,仅依赖传统标注数据进行微调),模型性能显著下降。这凸显了LLM驱动的数据合成在提升模型泛化能力和覆盖更多场景方面的重要作用。
2️⃣模型合并策略有效:
-
移除模型合并阶段(第三行),模型性能也有明显下降。这证明了模型合并技术对于提升最终模型的鲁棒性和综合表现是有效的。
总而言之,Qwen3 Embedding系列模型凭借其创新的训练流程、高质量的数据合成以及强大的基础模型,在多项基准测试中均取得了SOTA或极具竞争力的成绩。
总结
Qwen3 Embedding系列模型的发布,无疑是文本表示学习领域的一个重要里程碑。它不仅展示了基于强大基础模型构建专用任务模型的巨大潜力,也为我们揭示了LLM驱动数据合成、多阶段精细训练等一系列创新方法论的有效性。
凭借其在多个权威基准测试中的SOTA表现,以及开放共享的姿态,Qwen3 Embedding和Reranking模型有望成为研究人员和开发者在构建下一代信息检索、问答系统、RAG应用和智能体时的有力工具。
参考文献
论文链接: https://arxiv.org/abs/2506.05176
GitHub:https://github.com/QwenLM/Qwen3-Embedding.git
你好,我是唐国梁Tommy,专注于分享AI前沿技术。
欢迎你加入我的精品课程《多模态大模型 前沿算法与实战应用 第一季》。本系列课程覆盖了从基础概念到高级算法实现的全流程学习路径,内容涵盖了四个重要的多模态项目,这些内容不仅基于开源项目,还自主开发了一些新功能,适合企业级模型的部署与应用。
你将不仅了解多模态架构的理论背景,还会通过多个实际项目演练,深入实践多模态大模型的应用。每个项目实践均配有详尽的讲解和实操演示,以确保你能够高效掌握多模态领域的前沿技术和应用。
更多关于精品课程的相关介绍,请查阅:《精品付费课程学习指南》
欢迎你到我的B站:唐国梁Tommy
或 我的个人网站:TGLTommy.com
学习更多AI前沿技术课程,请参阅我为大家整理的:《免费公开课学习指南》
?点击左下角“阅读原文”可直接跳转至我的B站
#Qwen3 #AI大模型 #AI前沿论文 #唐国梁Tommy #多模态大模型 #大模型教程 #AIAgent #人工智能
转载请注明:深度解读 Qwen3 Embedding:从基础模型到SOTA文本Embedding与Reranker | AI工具大全&导航
相关文章
