导读 本次分享题目为大模型数据建设探索与实践。
1. 从工程化视角看数据建设
2. 预训练数据配比
3. 后训练数据筛选
4. 问答环节
分享嘉宾|赵宇博士 中国电信人工智能研究院 大模型数据负责人
编辑整理|Kathy
内容校对|李瑶
出品社区|DataFun

01
从工程化视角看数据建设
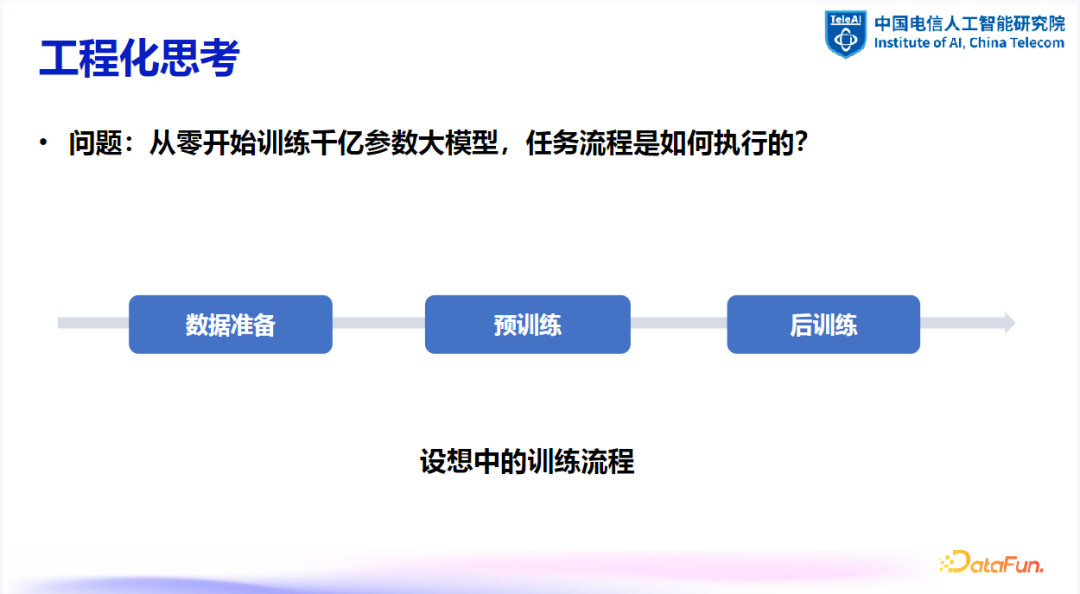
1. 数据准备与训练流程
-
预训练周期长:预训练阶段不仅时间跨度长,而且涉及大量的数据和资源协调。一个模型从开始训练到结束,可能会经历季节的更迭。 -
数据版本动态调整:伴随模型训练进展,数据版本需要持续动态调整。初始的数据准备可能无法完全满足模型训练的需求,因此在整个训练过程中需要不断地进行微调。此外,在后训练阶段,还需要对数据进行筛选,以适应模型训练的前进方向。

2. 影响数据版本更新的因素
-
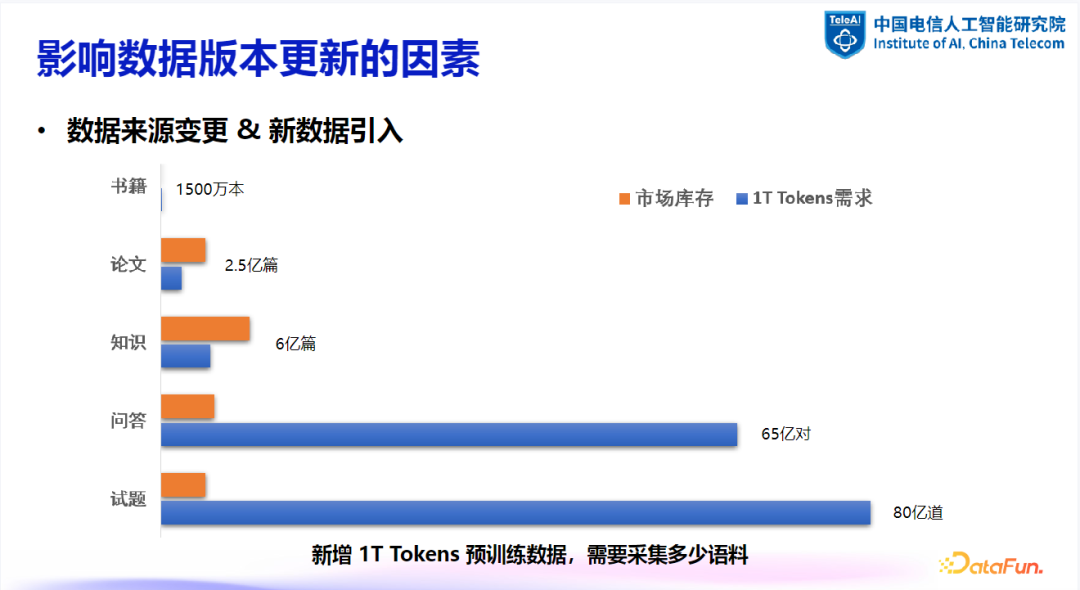
数据来源变更:数据来源的变化直接影响数据的构成与质量。 -
新数据引入:随着数据市场的不断发展,引入新数据成为一种可能。通过分析不同数据来源和通用语料长度,可以得出实际的需求量与市场库存量之间的差异。这一差异表明,尽管数据市场在繁荣发展,但要通过采购方式获取足量的训练数据仍具有挑战性。
-
数据配比差异:在训练过程中,数据的自然配比与理想的配比可能存在差异,需要根据训练情况适时调整。

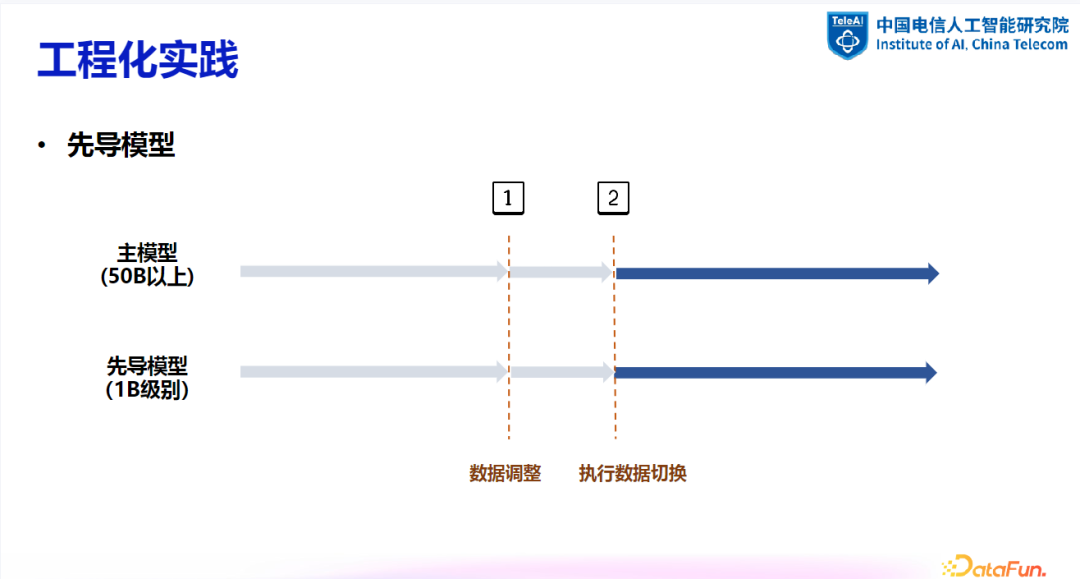
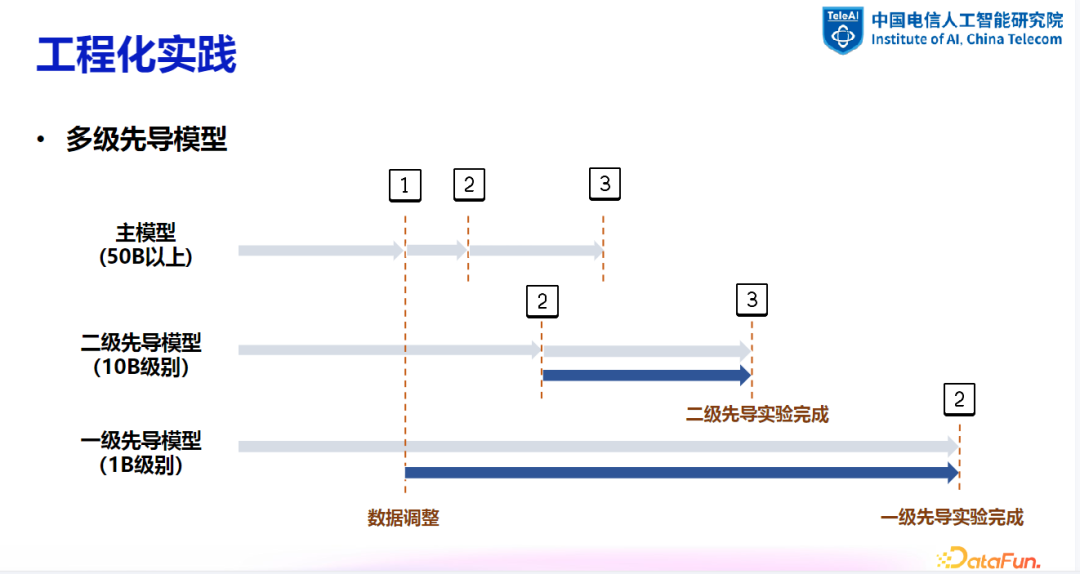
3. 先导模型在工程实践中的应用

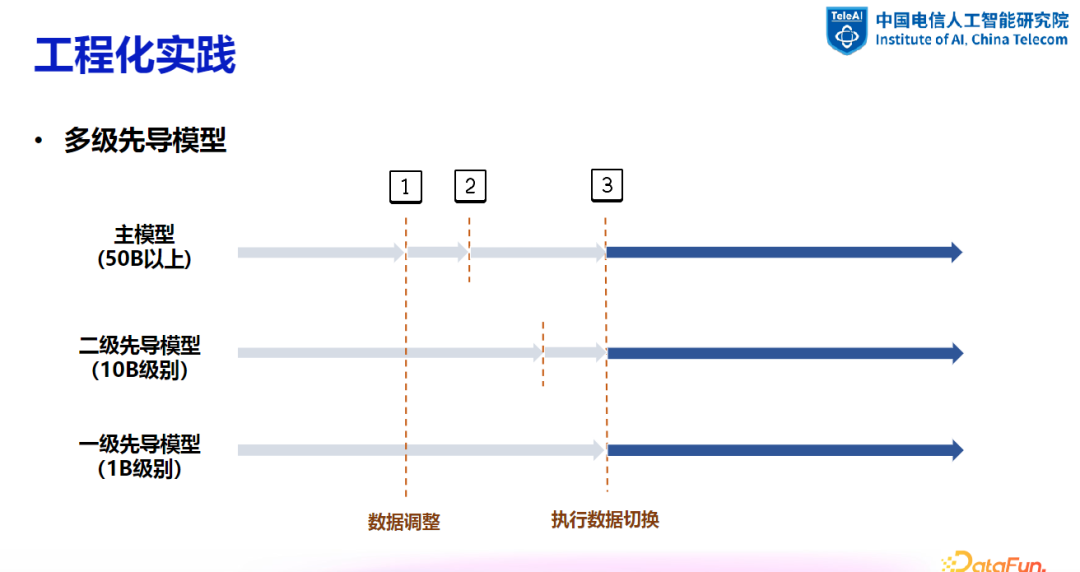
4. 评测指标与数据版本更新
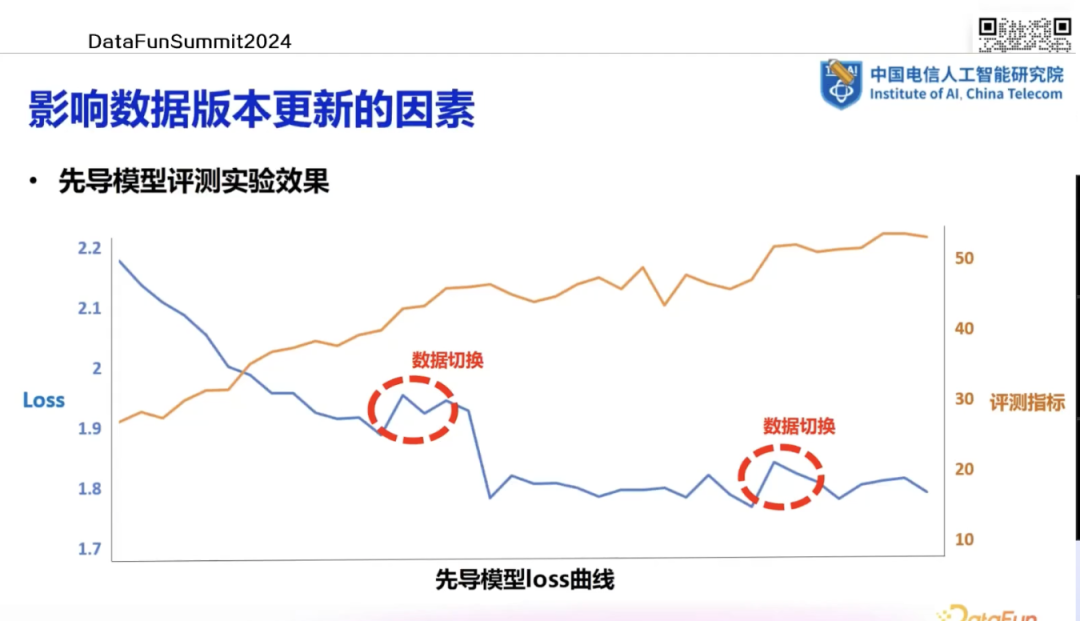
5. 数据处理流程

02
预训练数据配比策略
1. 数据配比策略概述
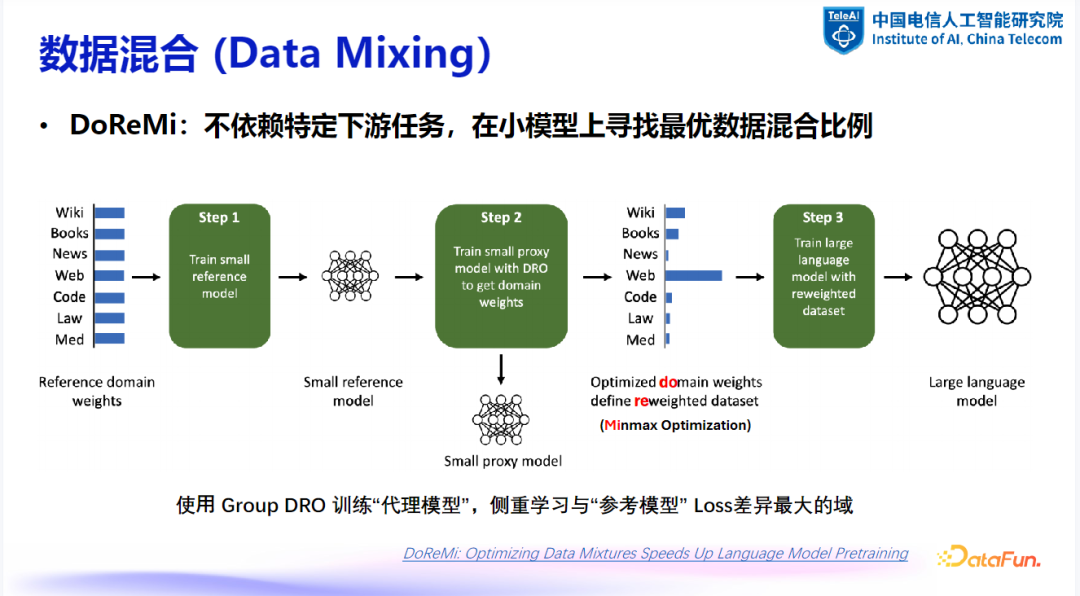
(1)DoReMi:一种经典的配比方法
-
训练参考模型:在数据的不同领域(domains)中设定一个归一化的初始权重,在上述权重下训练一个小的参考模型。 -
训练代理模型:利用 Group DRO 算法训练一个代理模型。在此过程中,代理模型与参考模型之间的损失(loss)在不同领域上存在差异。使用 Mini Max Optimization 算法来优化在代理模型与参考模型间差异最大的领域的权重。代理模型持续训练,而参考模型保持不变。通过代理模型与参考模型的交互过程,不断调整不同领域的权重。 -
大模型训练:获得优化后的权重后,用于训练最终的大模型。
(2)DoGE:双层优化算法

(3)ODM:在线领域采样权重调整
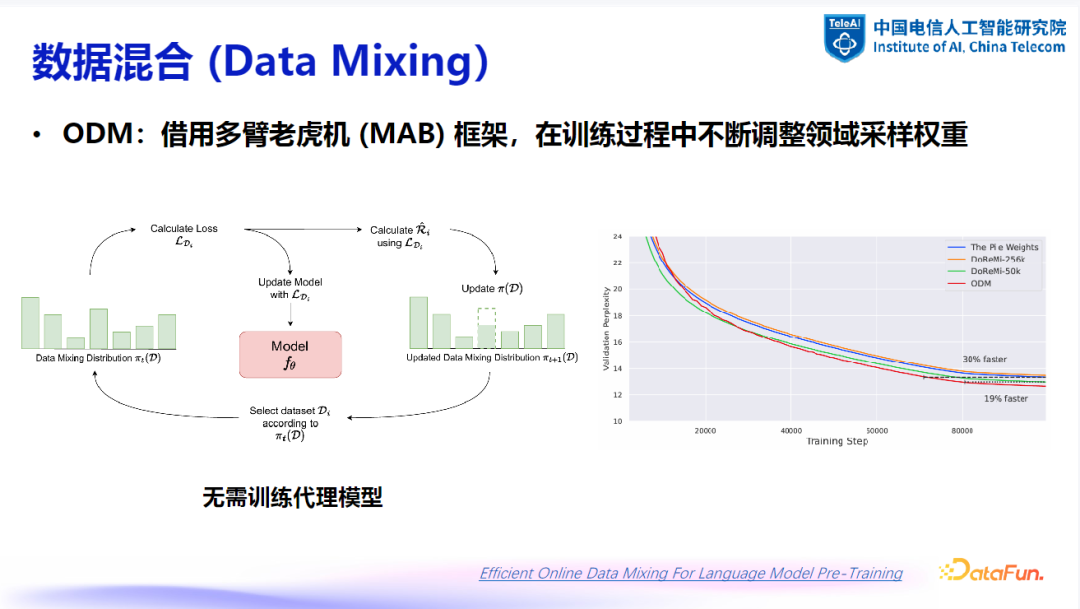
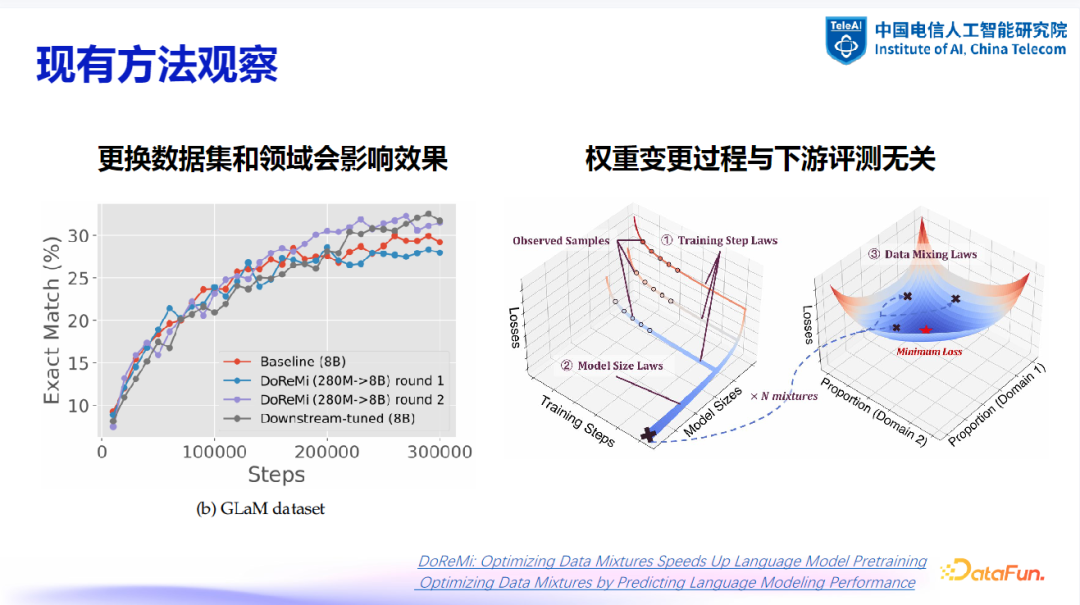
2. 现有方法特点与局限
-
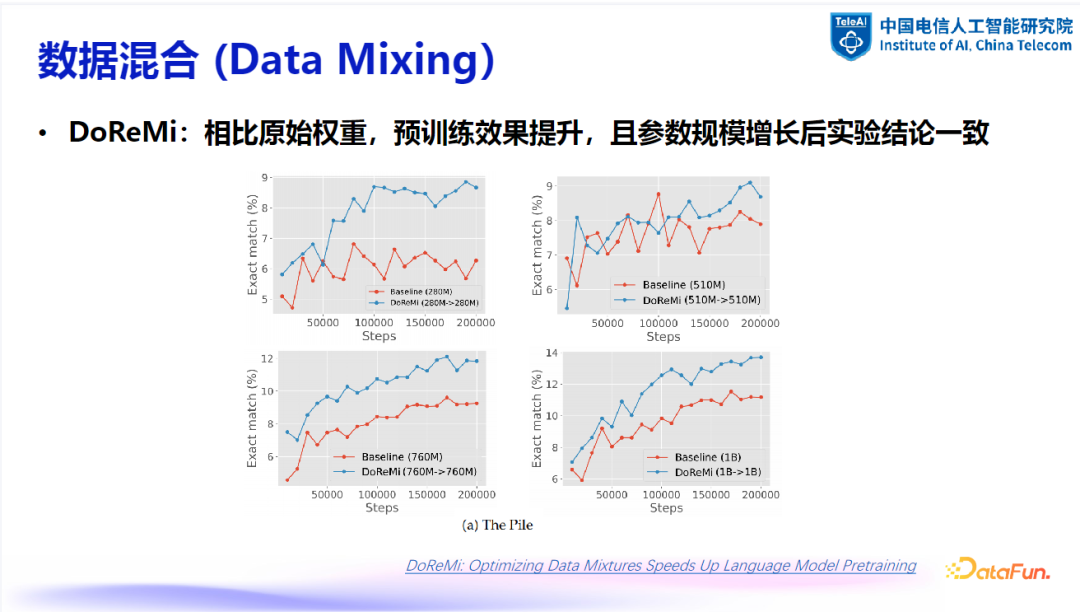
更换数据集和领域会影响效果:不同的数据集和领域会对参数更新效果产生显著影响。例如,DoReMi 方法在不同数据集上的效果差异较大,这表明数据集的多样性对训练效果至关重要。 -
权重变更过程与下游评测无关:权重变更过程通常不考虑下游任务的评测结果,而是侧重于寻找最优化的训练过程。这可能导致模型在某些特定任务上的表现不如预期。
3. 工程化实践中的数据配比调整
-
主动触发配比调整:在模型训练初期和中期,根据评测指标主动触发配比调整。 -
先导模型辅助:使用先导模型(如 DoReMi 方法)来优化数据配比。 -
避免直接应用算法:随着模型训练进展,避免直接应用高成本的算法。

4. 经验总结
-
中文数据的重要性:增加中文数据比例可以显著提高模型在文本理解、推理等方面的性能。例如,一些主流开源数据集中,中文数据比例较低,但在国内应用中,增加中文数据比例至 40% 左右,可以使模型在英文评测集上取得优于纯英文数据配比的效果。
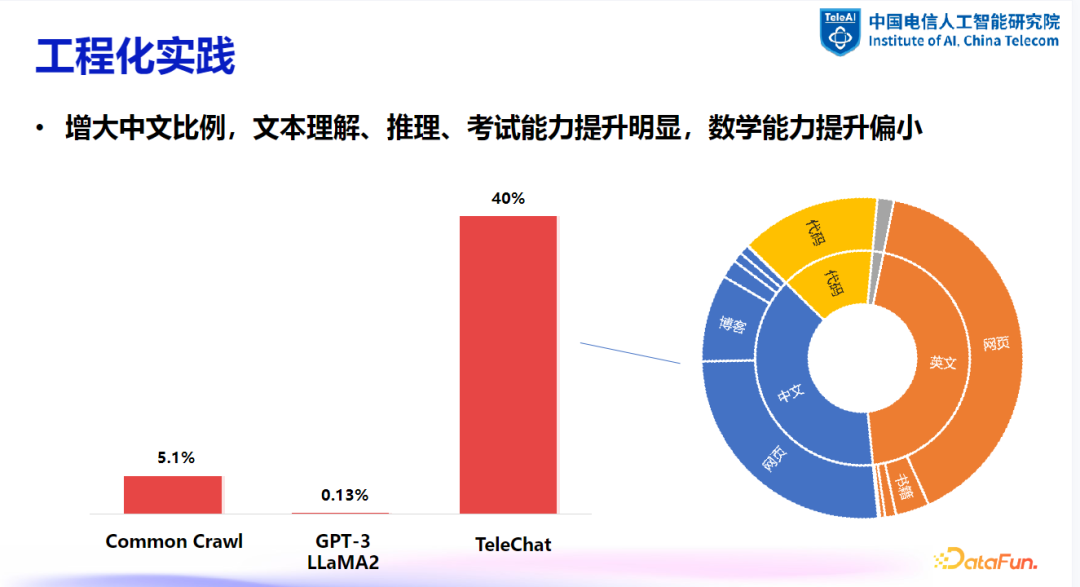
-
数学与题库数据的重要性:增大数学与题库数据的比例有助于提高考试与代码评测指标的提升速率。例如,最新的 LLaMA3 模型中,数学占比达到 25%,代码占比达到 17%,这表明在训练数据中加入更多数学和编程内容有助于提高模型在这些领域的表现。
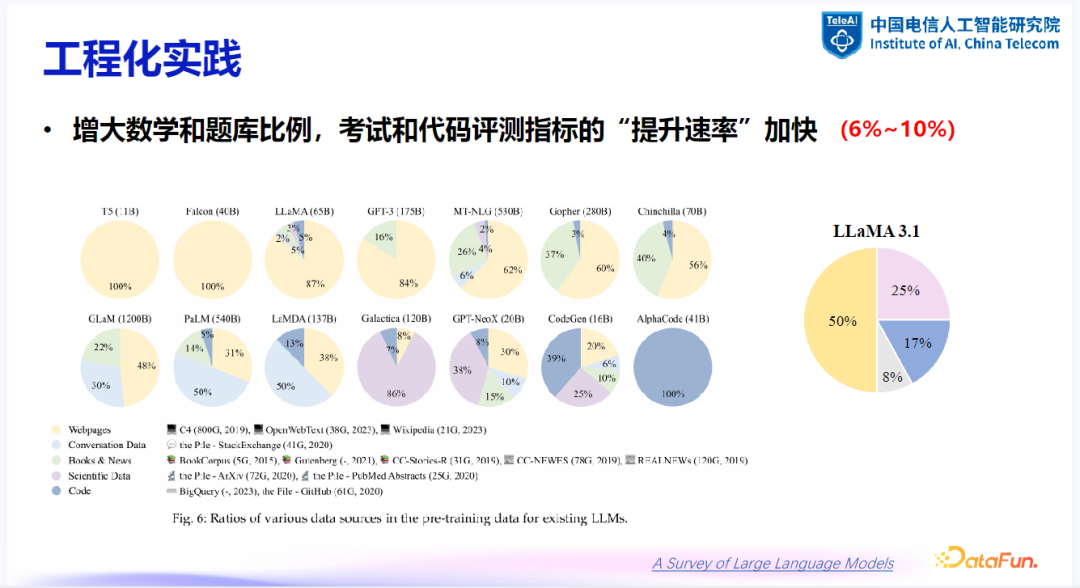
-
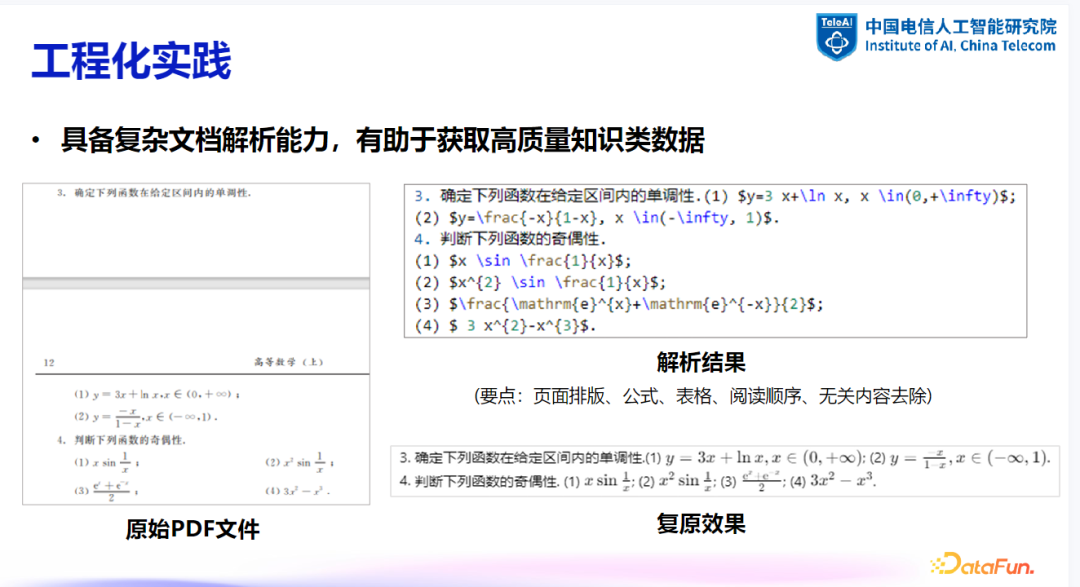
数据处理与解析:在公众化实验中,处理特定类型的数据(如数学题目)时,需要专门的文档解析技术或多模态大模型来提取文本内容。例如,从 PDF 文件中提取公式和表格,需要使用能够处理这些元素的解析器。
03
后训练数据的质量筛选
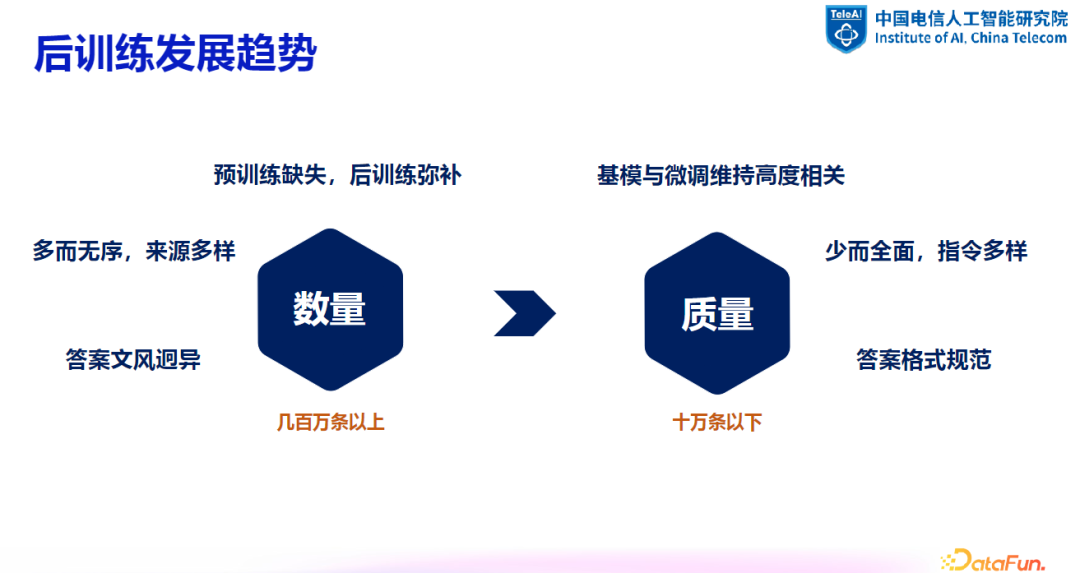
1. 发展趋势
2. 数据筛选方法
(1)CherryLLM
-
基本思想:通过少量数据训练出一个初步模型,利用该模型评估数据的指令追随难度,以此作为筛选依据。(指令追随难度用于衡量答案与指令的匹配程度,包括直接答案得分和条件答案得分) -
筛选流程:从全量数据中选取样例训练经验模型;利用该模型筛选出指令追随难度高的数据进行后续训练。

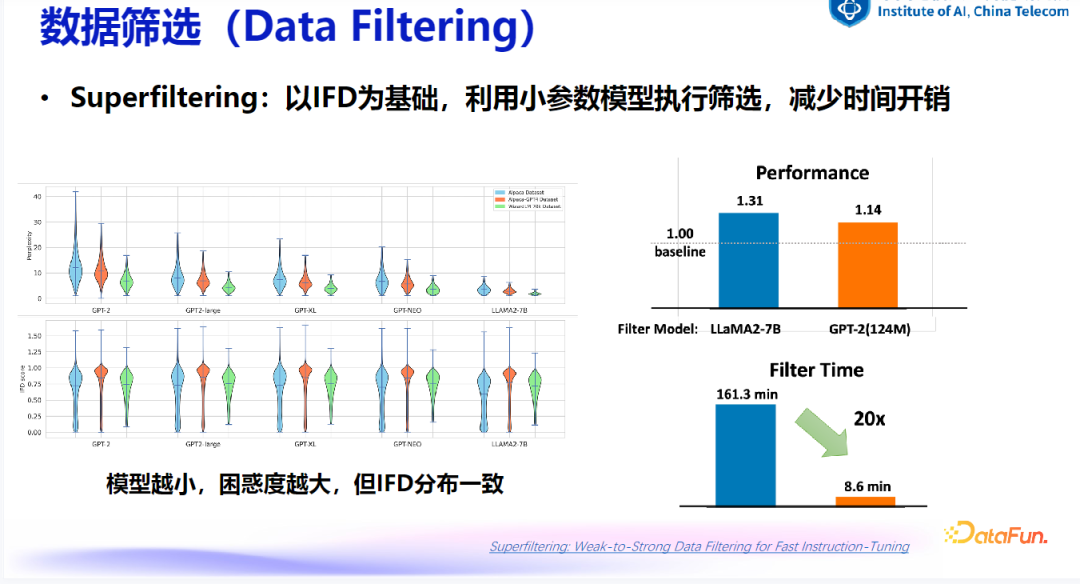
(2)Superfiltering
-
基本思想:利用较小的模型进行筛选减少时间开销,尽管其困惑度较高,但指令追随难度分布与大参数量模型结果类似,因此仍具有参考价值。
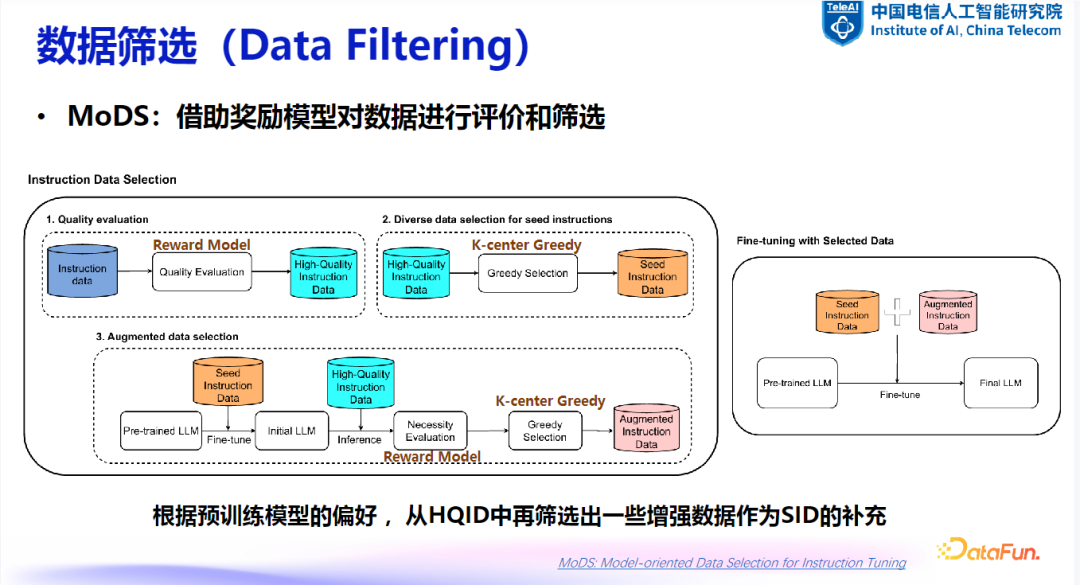
(3)MoDS
-
基本思想:利用奖励模型对数据进行评分,通过多层次筛选进一步提升数据质量。 -
流程:从高质量数据中选取种子样本训练初始模型,使用模型推理结果再次筛选并增强数据集。
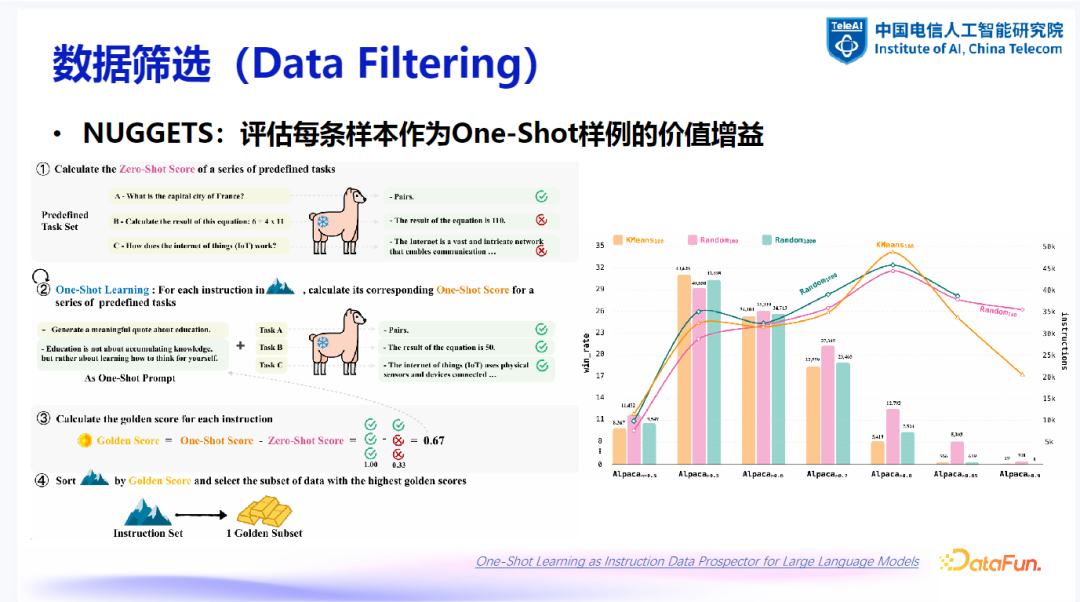
(4)NUGGETS
-
基本思想:评估每条样本作为 One-Shot 示例的价值增益。 -
优点:能够量化样本对训练过程的价值,并可通过聚类等手段进一步优化。
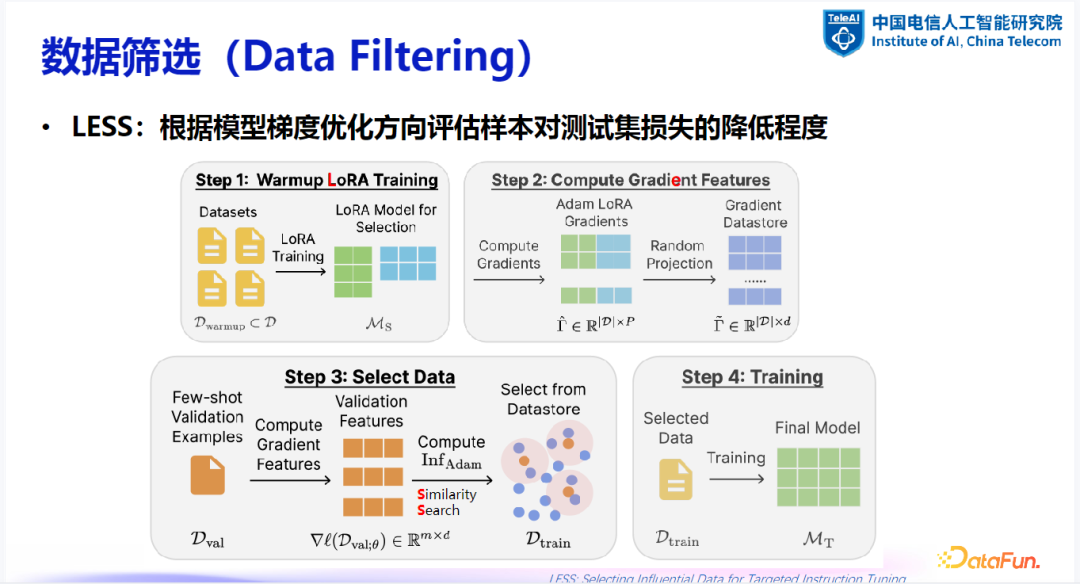
(5)LESS
-
基本思想:利用模型梯度评估样本对测试集损失降低的程度,从而筛选出最有价值的数据。 -
方法:
-
使用 LoRA 训练并保存样本梯度。 -
从训练数据中挑选出与示例数据集样本梯度相似度最高的部分。
3. 现有方法分类与特点
-
模型类方法:依赖外部模型能力,计算开销大。 -
指标类方法:计算效率高,潜在误差大。

4. 理想指标的探索
-
精确性与确定性:既能准确匹配答案,又能反映模型对生成内容的不确定程度。 -
动态变化:随着模型训练的深入,符合条件的数据量逐渐减少。

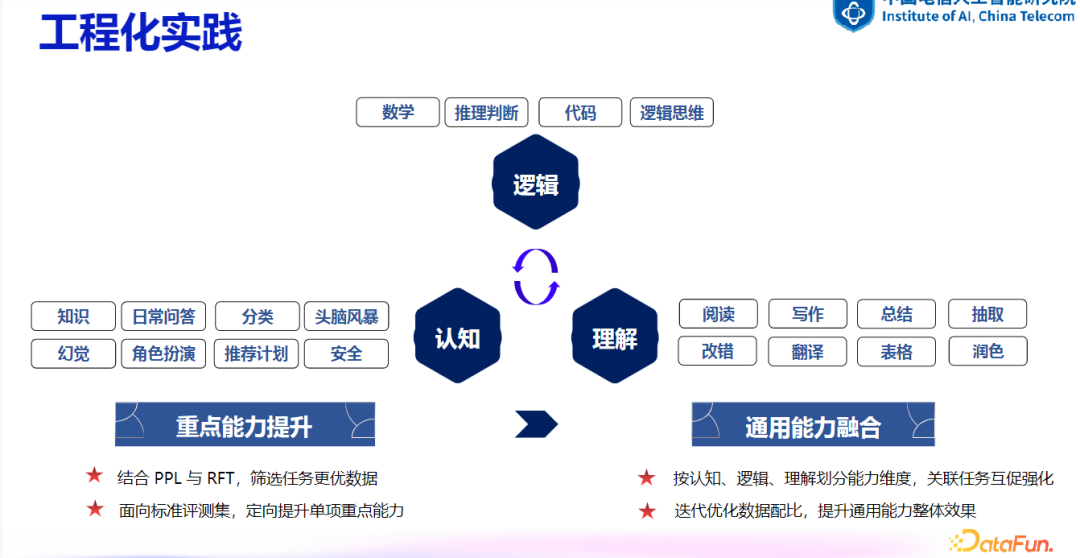
5. 工程化实践
-
数据分类:将数据按逻辑、认知、理解等多个层次分类。 -
能力提升:针对单项能力进行优化,随后进行跨类别的综合优化,以实现能力融合。 -
迭代优化:通过多轮迭代优化数据配比,逐步提升模型的整体性能。
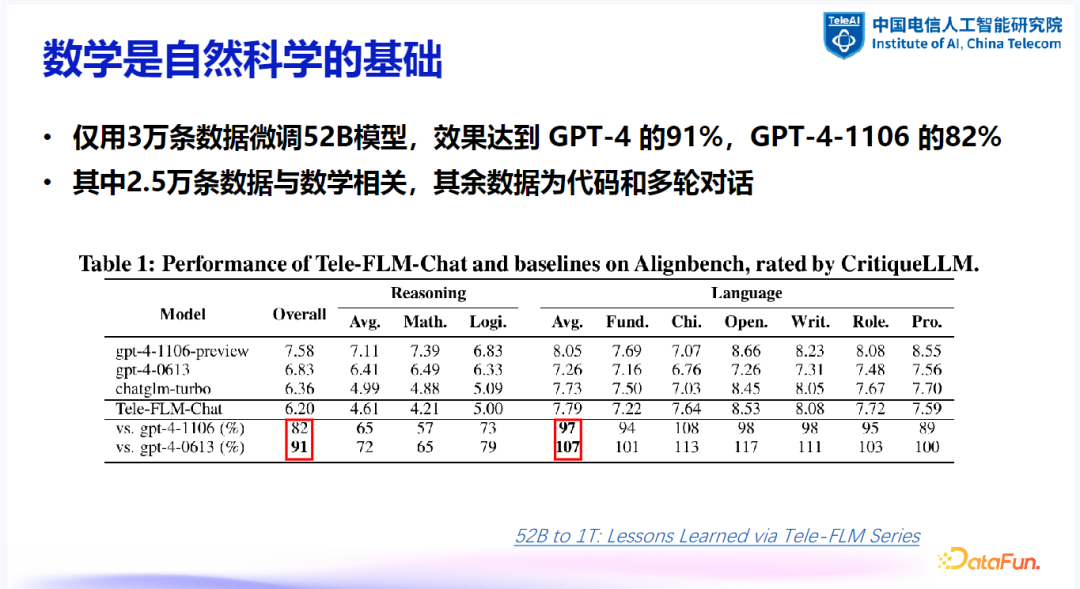
6. 数学数据的重要性
04
问答环节
Q1:是否存在数据量维度的 scaling law,即数据量越大,模型效果越好?
Q2:数学数据的来源主要是什么?
Q3:不同领域的数据进入模型训练的顺序是否影响模型效果?
Q4:先导模型与主模型在结构上需要怎样的关联?
Q5:PDF 文件处理有哪些难点?在选择或开发 PDF 处理工具时应注意什么?
相关文章
最实用、最热门的AI 工具大全AI 工具导航,帮助你在工作与学习上更轻松有效率。在网路上众多 AI 与 ChatGPT 工具中,我们亲自试用并挑选了最有有用的,分成 20多个大类别,让你轻松找到所需的 AI 工具。
