
在数据驱动的时代,快速、准确地获取数据是企业决策和业务发展的基石。然而,对于许多技术团队而言,日常的取数工作往往充满了挑战,耗时耗力。
我们团队也曾深陷其中,直到开始探索 AI Agent 在这一领域的应用,特别是通过实践 Cursor-Agent,我们看到了一条从手动取数到自动化"数据大师"的进化之路。
1. 取数之痛与 LLM 的"未尽全功"?
1.1 取数需要排期?
-
需求评审前/产品功能上线后,看新功能影响面/使用量: "换货退款有大改动,看下储值支付的订单量: 拉下24年每个月包含储值支付的换货订单、GMV有多少? " -
运营数据统计:"商业化政策有调整,需要看下最近特定交易场景的使用量:2025年在使用某功能的商家名单,但需要剔除某时间之后新签并使用某功能的商家数据"
日常取数的问题
-
想要统计数据,需要编写SQL,非技术职能有编程学习成本; -
如果技术此前没有处理过这块业务,也得找人找文档明确需求口径,需要用到哪些库表和条件判断。 -
SQL 编写有一定困难,如果没有历史SQL的积累, 从头开始写 SQL 常常是按小时计算。 -
这也是为什么复杂点的产品取数需求要排期,因为不是简单几分钟就能搞定的。
1.2 LLM 提高了效率,但"最后一公里"仍是挑战
近年来,大型语言模型(LLM)如 ChatGPT、Claude 在 SQL 生成方面展现了惊人能力,确实在一定程度上提升了效率。比如,我们可以将需求"统计不同商家类目在新渠道订单量、GMV" 输入给LLM,它能快速给出一个SQL草稿。
然而,我们很快发现,LLM 距离真正的"全自动化"取数还有关键的"最后一公里":
-
缺乏执行能力:LLM 生成SQL后,我们依然需要技术人员手动复制这些SQL语句,粘贴到公司的数据平台或数据库客户端中才能执行,无法实现"一键直达"。 -
无法处理真实环境反馈:即使SQL在语法上是正确的,实际执行时可能会遇到各种问题,例如"权限不足,无法访问某张表"、"表A中不存在字段X"或者"日期格式不匹配导致查询失败"。LLM 本身无法感知这些运行时错误,更不用说自动修正了。 -
上下文理解与迭代割裂:当第一次取数结果不满足需求,需要调整时(比如,运营说"刚才忘了提,还需要排除内部测试账号"),简单地再次向LLM提问,它可能无法很好地理解前序操作和上下文,导致我们需要重新组织完整的提示词,迭代效率低下。 -
与数据环境隔离:LLM 对我们内部的数据库表结构、字段命名规范、枚举值的具体含义、业务特有的计算逻辑等领域知识一无所知。因此,生成的SQL质量高度依赖于我们提供提示信息的详尽和准确程度。
我们意识到,我们需要的不只是一个"SQL代码生成器",而是一个能够理解需求、规划步骤、与真实数据环境交互、处理反馈并自主完成任务的智能体 (Agent)。
2. 新思路:基于 Cursor-Agent 的端到端自动化实践
正是在这样的背景下,我们开始探索和实践 Cursor-Agent。基于 Cursor-Agent 构建了一套完整的 Agentic Workflow,旨在实现从需求输入到结果输出的端到端自动化。
2.1 视频演示 📢📢📢
这里使用 测试库表 演示 Agent 处理数据需求的能力
Agent 数据权限说明:
-
身份认证机制:基于开发者个人账号的严格身份验证,Agent 访问权限严格受限于用户授权范围 -
多层安全防护:数据平台完整的权限矩阵、实时监控、安全审计、敏感数据脱敏等防护体系全面生效 -
零特权原则:Agent 严格遵循最小权限原则,仅通过标准API接口访问,无任何权限提升或安全绕过能力 -
合规可追溯:所有数据访问操作均纳入安全审计日志,确保操作行为的完全可追溯性和合规性
2.2 核心优势
-
明确需求下的"零干预": 当业务方提供口语化的取数需求时(例如:统计25年多渠道的经营状况),Agent 能够自动完成需求分析、查找资料、编写SQL、使用工具访问数据库执行SQL,甚至在遇到一些简单执行问题(如轻微的SQL语法调整、字段格式不匹配时)时能自行修正,最终直接返回数据结果。整个过程几乎无需人工干预。
-
模糊需求下的"自主探索": 更令人印象深刻的是,即使面对相对原始和模糊的需求, Agent 也能展现出强大的自主探索能力。 如我们内部真实需求: "统计24年每月储值支付的换货订单", 在订单表数据中没有明确标记是否使用了储值支付,且领域知识文档没有支付方式的介绍, Agent 通过订单表中
pay_tool_id字段的备注 "支付方式参见pay_tool_table_name", 自动探索支付方式表,关联查询出储值支付方式。 这个重要技能在后续迭代中被补充进了提示案例中。 -
效率提升的惊人数据: 复杂取数需求 从传统的4-6小时,缩短到10-15分钟。 更重要的是,这种效率提升不仅仅是速度上的突破,更是让非技术人员也能直接进行数据探索,彻底打破了"取数需要排期"的传统协作模式。
3. 整体架构与核心组件
3.1 整体架构
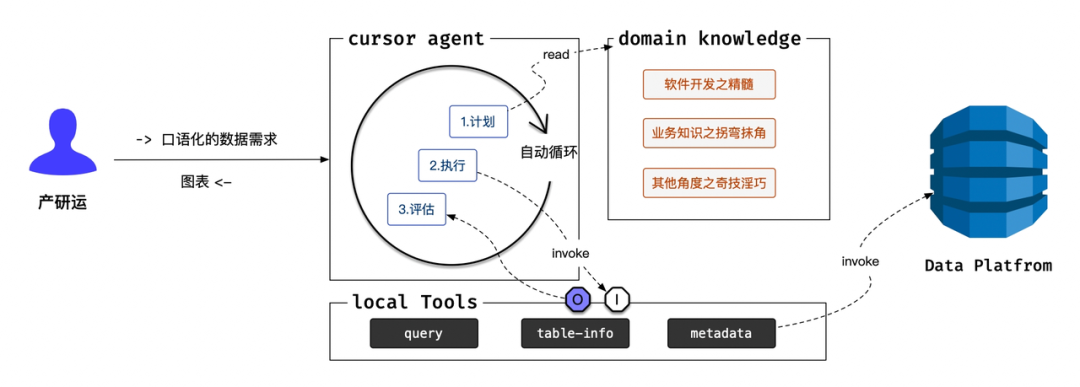
-
核心是高度集成 AI、 全自动化 -
Cursor-Agent的工作流程: 需求分析 -> 业务知识查找 -> 数据库表字段查找 -> 编写SQL -> 执行SQL -> 观察和处理执行结果 -> 继续编写SQL。 -
自动循环这个工作流程,直到满足需求。
3.2 Cursor-Agent 介绍
-
官方文档说:Cursor 开启 Agent 模式状态下,它会尽可能的使用所有工具,完成用户提出的复杂编程任务(需求)。 -
大致流程可以理解为: 分析需求、计划任务、执行任务、评估结果,继续计划和执行等。 -
Cursor 内置工具: 访问网络、执行命令(CLI)、读写文件、阅读当前代码仓库等等。
3.3 灵魂所在:.cursorrules (指令与流程引擎)
核心作用
.cursorrules 的内容是领域知识的重要组成部分, 是 Agent 的行动指南和思考框架,它包含了一系列预设的规则、指令、流程和技巧, 其中最重要的工作流部分是来自于编写SQL的真实流程和 最佳实践。
.cursorrules 核心结构
具体内容见底部附录
# role
# workflow
# instruction
# checkpoint-validation
# troubleshooting-guide
# performance-tips
# tool-use
# example
3.4 连接现实:本地工具 (Local Tools)
核心作用
作为 Agent 的"手脚",Local Tools (主要是 Node.js 脚本) 负责与真实数据环境交互。
-
query(sql_statement):接收一个SQL语句字符串,通过HTTP请求访问数据平台,并返回查询结果(如CSV格式数据或错误信息)。 -
table-info(table_name):接收一个表名,通过HTTP请求访问数据平台,返回该表的字段列表、数据类型、字段注释等。 -
metadata(keyword):接收一个业务关键词(如"店铺"、"交易"),使用数据平台元数据搜索功能, 搜索关键字关联的数据表。
3.5 快速索引:知识库
核心作用
由于数据平台的一些现存问题,导致 Agent 直接访问数据平台获取数据定义时,内容是有缺失的,从而导致查询效率非常低,甚至陷入死循环中。
所以知识库的出现是对数据平台数据定义的补充, 为 Agent 提供领域相关的知识, 加快 Agent 解决需求的速度
举例数据定义的一些缺陷
1. 字段值域定义的缺失
-
现实问题:数据库约束往往只定义数据类型,而不定义枚举值域,导致Agent无法准确筛选目标数据 -
数据库表定义: payment_method int- 只能看到是数字,不知道有哪些有效值, 具体的含义 -
知识库补充: payment_method字段值域:1=微信支付,2=支付宝,3=银行卡,4=余额支付,5=等等
2. JSON/TEXT字段内容结构缺失
-
现实问题:大量业务数据以JSON格式存储,但缺少结构化的字段说明文档 -
数据库表定义: order_extra text COMMENT '订单扩展信息'- 看不到JSON内部结构 -
知识库补充: order_extra字段结构:{"channel":"渠道来源","promotion_id":"活动ID","coupon_info":{"type":"优惠券类型","amount":"金额"}}
3. 表名、指标搜索能力不足
-
现实问题:数据平台无法通过中文业务词汇准确搜索到表名 -
数据库现状:表名如 dw_order dw_order_ext dw_trade_xx dw_trade_xx 等等,库表太多难以直接和销售、交易精确关联 -
知识库补充: #交易 ##订单 表名: dw_order(订单主表)、dw_order_ext(订单扩展表)、dw_refund(退款表)等
领域知识文档通过 Markdown 格式组织业务、技术知识, 目前来看,最重要内容是:
-
核心数据表用途:" dim_user_profile存储用户画像基础信息,fact_order_details存储订单明细。" -
字段业务含义:" orders.order_type字段,1=普通订单,2=拼团订单,3=秒杀订单。"
具体内容见底部附录
4. 我们的探索与进化
我们的 Agent 并非一蹴而就,而是经历了一个不断探索、试错和优化的迭代过程,每个版本都带来了能力的提升和体验的优化。
迭代花絮 (V0.1 -> V0.4)
v0.1
-
变更: Local Tools 增加了 query -
表现: 在提供具体库表和需求的情况下,Agent 可以完成简单的需求分析,编写SQL、执行SQL、自动解决执行问题。 -
缺陷: 满足 NL2SQL 功能,没有自主探索能力。
v0.2 顿悟时刻
-
变更: cursorrules 设置了一些指令和流程; Local Tools 增加 table-info、metadata -
表现: 直接输入原始需求,Agent 可以完成需求分析、编写SQL、执行SQL 的自动循环, 令人震惊的是整个过程完全自动化的。 -
主要缺陷: 运行时间非常长,如果不做人工干预,它可以和你聊几个小时
v0.3
-
变更: 引入知识库文件;优化cursorrule 中的指令和流程 -
表现: 执行效率有了很大的提升, 在需求明确的情况下,0干预 -
缺陷: Cursor Agent 的执行流程不完全按照预设指令执行, 有一定随机性,但大体用到了 cursorrule 中提到的规则和技巧。
v0.4 技术预览版
-
变更: 优化cursorrule, 增强了对 Agent 的整体控制 -
表现: Agent处理需求的稳定性大大增强, 可以公开给技术同学使用了 -
缺陷: 细枝末节难控制,比如,当出现表权限不足时,应终止执行,而不是尝试其他路径
迭代过程中最核心的问题
思前想后,最核心的问题应该是 Agent 行为可控性,它直接关乎项目能否成功。 而其他的也非常重要的问题, 业务理解能力、执行效率、性能等都可以根据工程经验优化,但这些优化生效的前提是Agent要"听话", 如果它不按照你精心设计的规则和策略执行,那么再好的优化策略也没用,再完善的知识库也发挥不了作用。
在 v0.3 时, Agent 的表现尽管已经非常智能, 可以0干预处理简单的查询需求,但是稍微复杂的需求,执行流程有很大随机性,它不完全按预设指令行动,可能导致最终结果有错误,甚至陷入逻辑死循环中,跑不出最终结果。
解决办法:cursorrules (workflow + example)
-
cursorrules本质是系统提示词 -
可以理解为, 通过系统提示词指定明确工作流程( workflow), 而工作流程是模拟一名技术处理真实取数需求的过程, 按流程执行大概率能得到最终结果。 -
同时,通过案例强化Agent对工作流程的理解( example), 案例中的执行过程应该和工作流中内容是对应起来的。
5. 展望:产品化的可能
通过在 Cursor-Agent 上的实践,我们坚信 AI Agent 将在数据处理领域扮演越来越重要的角色。特别是,与业务功能的深度融合方面,Agent 的角色将从单纯的取数工具,向更广泛的业务流程延伸,同时将突破现有的产品交互形式,迈向更智能、更自然的人机协作模式。
-
交互形式的根本转变:从UI操作到自然对话;告别复杂的下拉菜单和指标筛选,用户只需在客户端说"看下某商品在各渠道一个月的销售情况", -
图表解读的突破:任何图表都能继续追问和深度分析 针对近期的用户漏斗图,用户可以继续问"为什么第3天流失这么严重?" -
决策辅助升级:从数据展示到行动建议 不再只是告诉你"这周GMV下降了20%",而是直接给出建议:"主要因为A款T恤库存不足,检测到近3天有126人浏览但因缺货未下单,预计损失订单金额1.8万元。建议立即补货"。
如果要完成未来的产品化,肯定要脱离 Cursor-Agent,基于通用的 LLM API 或开源 Agent 框架进行二次开发,构建更开放、更易于集成的 Agent 服务。这无疑会带来更大的想象空间,但也需要攻克模型适配、提示词优化、上下文存储优化、垂直知识库高效集成等技术挑战。
6. 思考:技术变革的焦虑与兴奋
技术发展太快,早期积累的工程优势,在下一阶段变革到来时,往往顷刻化为乌有,甚至成为前进的桎梏。 LLM/Agent 领域的发展速度令人咋舌,技术项目的生命周期被极度压缩。
几周就是一个时代:
-
我们花费数月精心打造的技术驱动项目,可能在几周后就被一个新的开源项目轻易取代 -
昨天的最佳实践今天就可能过时 -
甚至 OpenAI、Anthropic 的一次模型更新,都可能让我们精心调试的 prompt 工程毫无用武之地
技术积累的脆弱性:
-
传统软件开发中,技术积累可以延续数年甚至十年 -
在 AI 时代,数周的工程努力可能因为一个新工具的出现而归零 -
"深耕细作"与"快速迭代"之间的平衡变得极其微妙
更深层的思考:
-
也许我们需要重新定义什么是 "有价值的积累" - 是具体的代码实现,还是对问题本质的理解? -
在技术快速变化的时代,保持"技术敏感度"和"快速学习能力"比任何具体的技术栈都更重要 -
或许,真正的护城河不在于掌握某种特定技术,而在于快速适应和整合新技术的能力
当我们还在为这个月的技术选择沾沾自喜时,下个月可能就需要完全推倒重来。这既让人焦虑,也让人兴奋 - 这就是我们所处的时代。
7. 附录
cursorrules 片段 - workflow

# workflow
必须严格按顺序执行以下步骤,不得跳过任何步骤:
1. 需求解构:
- 必须提取需求中的业务对象、筛选条件、时间范围、字段需求
- 必须使用表格形式列出提取的内容
- 必须标识哪些是已知概念,哪些是需要确认的概念
- 必须使用表格形式列出期望的结果
2. 业务知识搜索:
- 必须在领域知识文档(domain-knowledge.md)中搜索关键的表和字段 "关键词1|关键词2|关键词3"
- 必须记录相关的业务定义、业务表、判断条件
- 必须整理并输出所有找到的信息,表名加粗显示
3. 信息汇总与缺口识别:
- 必须列出:已知信息(表名、字段、条件)和未知信息(缺失表、缺失字段、未明确条件)
- 必须标记探索优先级:高(影响查询成败)、中(影响结果准确性)、低(可选)
4. 数据探索-表结构:
- 对每个相关表必须执行:`node index.js table-info "table_name"`
- 必须记录:主键、关键业务字段、索引字段、字段备注、表注释、表行数
- 如发现关键字段缺失,必须使用 metadata 搜索替代表:`node index.js metadata "业务"`
- 禁止使用 query 工具探索表结构
5. 数据探索-数据验证:
- 必须对每个关键表执行:`node index.js query "SELECT * FROM table_name WHERE 时间字段 >= '最近一天日期' AND 时间字段 < '最近一天日期+1' ORDER BY 主键字段 DESC LIMIT 3"`
- 必须验证关键字段值:`node index.js query "SELECT DISTINCT 关键字段 FROM table_name WHERE 时间字段 >= '最近一天日期' AND 时间字段 < '最近一天日期+1' LIMIT 10"`
- 必须检查日期格式:`node index.js query "SELECT DISTINCT DATE_FORMAT(时间字段, '%Y-%m-%d') FROM table_name WHERE 时间字段 >= '最近一天日期' AND 时间字段 < '最近三天日期' LIMIT 5"`
- 所有查询必须包含时间范围,从最小开始,如果没有数据,逐步放大:1天→1周→1个月
- 禁止在验证数据阶段使用聚合函数和GROUP BY、Order By语句
- 禁止执行无时间限制的查询
6. 查询构建-单表筛选:
- 只有在无数据时才扩大时间范围,有数据则继续添加其他筛选条件
- 必须逐个添加条件并验证:`node index.js query "SELECT * FROM table_name WHERE 条件1 AND 条件2 LIMIT 5"`
- 只在必要时使用COUNT:`node index.js query "SELECT COUNT(1) FROM table_name WHERE conditions"`
7. 查询构建-表关联:
- 必须在关联前记录各表行数:`node index.js table-info "table_name"`
- 只有在无数据或数据不足以验证关联正确性时才扩大时间范围
- 如关联后返回结果异常,必须立即停止并检查关联条件
- 必须确保:小表(行数少的表)在FROM,大表(行数多的表)在JOIN
8. 查询构建-聚合计算:
- 只有在无数据或数据不足以验证聚合结果正确性时才扩大时间范围
- 在添加GROUP BY前验证:`node index.js query "SELECT * FROM base_query LIMIT 5"`
- 验证聚合计算的合理性:`node index.js query "SELECT 维度字段, COUNT(1) FROM base_query GROUP BY 维度字段 LIMIT 10"`
9. 结果完整性验证:
- 必须检查结果是否涵盖所有需求维度
- 必须确认各维度汇总数据与总量的一致性
- 必须验证结果集中是否存在意外的空值或异常值
- 必须与原始需求进行对照,确保所有问题都已解答
10. 最终查询与验证:
- 必须为最终SQL添加注释:说明业务逻辑、特殊处理、预估结果集大小
cursorrules 片段 - example
# example
input: 统计2024年每月使用储值支付换货订单数量
## 1. 需求解构
|组成部分|内容|是否需要确认|
|-------|-------|-------|
|业务对象|换货订单|需要确认判断条件|
|筛选条件|储值支付|需要确认判断条件|
|时间范围|2024年每月|已知|
|需求指标|订单数量|已知|
期望的结果表格形式:
┌────────┬────────────┬────────────┬──────────┐
│ 月份 │ 网店换货数 │ 门店换货数 │ 总换货数 │
├────────┼────────────┼────────────┼──────────┤
│ 2024-01│ 123 │ 456 │ 789 │
└────────┴────────────┴────────────┴──────────┘
## 2. 业务知识搜索
执行: `grep -i "换货|储值|支付|订单" domain-knowledge.md`
结果整理:
- 换货订单:
* 门店: ods.exchange.order_no
* 网店: dw.refund.refund_demand=3
- 订单信息: dw.order
- 储值支付: 未找到直接定义,需进一步探索
## 3. 信息汇总与缺口识别d
已知信息:
- 换货订单判断方式(门店和网店不同)
- 订单主表: dw.order
- 时间范围: 2024年全年按月统计
未知信息(优先级):
- 储值支付的判断条件(高): 需要确定字段和值
- 订单表中的时间字段(高): 需确认用于按月统计的日期字段
- 不同订单表之间的关联关系(高): 如何关联门店和网店订单
## 4. 数据探索-表结构
执行: `node index.js table-info "dw.order"`
执行: `node index.js table-info "dw.refund"`
执行: `node index.js table-info "ods.exchange"`
关键发现:
- dw.order:
* 主键: order_id 订单id
* 时间字段: created_time 订单创建时间
* 支付相关字段:
字段名|备注|业务口径
tc_pay_tool_id|支付工具id|查看dw.pay_tool 维表 标记支付、储值支付等信息
payment_type|支付类型|
pay_type|支付方式|
order_extra|订单扩展信息|
- ods.exchange:
* 主键: id 数据库自增id
* 关联字段: order_no 订单id
* 时间字段: created_at 换货订单创建时间
关键字段备注了新表:
- dw.pay_tool 支付工具扩展表
执行: `node index.js table-info "dw.pay_tool"`
关键发现:
- 支付工具id: tc_pay_tool_id
- 支付工具名称: tc_pay_tool_name
## 5. 数据探索-数据验证
执行: `node index.js query "SELECT tc_pay_tool_id, tc_pay_tool_name FROM dw.pay_tool Where tc_pay_tool_name like '%储值%' limit 10"`
结果: 储值支付工具名称包含"储值" (根据实际情况)
---- 返回结果
tc_pay_tool_id|tc_pay_tool_name
1|储值支付
2|储值卡
3|赠送储值
4|会员储值
---
验证日期格式:
执行: `node index.js query "SELECT DISTINCT DATE_FORMAT(created_time, 'yyyy-MM-dd') FROM dw.order LIMIT 5"`
从最小时间范围开始查询:
执行: `node index.js query "SELECT * FROM dw.order WHERE created_time >= '2024-01-01' AND created_time < '2024-01-02' LIMIT 5"`
结果: 0条记录 - 没有数据,需要扩大时间范围
扩大时间范围:
执行: `node index.js query "SELECT * FROM dw.order WHERE created_time >= '2024-01-01' AND created_time < '2024-01-08' LIMIT 5"`
结果: 5条记录 - 找到数据,可以继续下一步
## 6. 查询构建-单表筛选
先用最小时间范围验证换货订单:
执行: `<<SQL>>`
结果: 2条记录 - 有数据,无需扩大时间范围
验证储值支付订单内容(同样使用小时间范围):
执行: `<<SQL>>`
结果: 5条记录 - 有数据,无需扩大时间范围
添加多个筛选条件:
执行: `<<SQL>>`
结果: 3条记录 - 条件筛选符合预期
## 7. 查询构建-表关联
使用最小时间范围验证表关联:
执行: `<<SQL>>`
结果: 3条记录 - 有足够数据验证关联正确性,关联没有产生笛卡尔积
验证关联结果与预期一致,无需扩大时间范围,可以继续下一步。
## 8. 查询构建-聚合计算
先用最小时间范围验证聚合:
执行: `<<SQL>>`
结果: 3条记录 - 有足够数据验证聚合计算,无需扩大时间范围
验证按月聚合的正确性(全期间):
执行: `<<SQL>>`
结果: 12条记录(1-12月),行数合理
## 9. 结果完整性验证
-- 2024年每月使用储值支付的换货订单数量统计
-- 业务定义: 换货订单(refund_demand=3)且使用储值支付(tc_pay_tool_id in (1,2,3,4))
<<SQL>>
action:
1. 维度缺失,没有统计门店渠道的换货订单
2. 回到数据探索-表结构步骤,增加门店渠道的统计。
## 10. 最终查询与验证
-- 最终查询SQL,需要使用中文列名展示,并分页拉取数据
-- 业务定义: 统计2024年每月使用储值支付的换货订单数量,区分网店和门店
<<SQL>>
cursorrules 片段 - tool-use
# tool-use
## query
> 执行SQL, 并保存结果到csv中, 所以不需要再导出数据了。
* base case ,SQL不允许包含换行符 `node index.js query "SELECT * FROM dw.orders LIMIT 10"`
* 执行带中文列名的SQL, 使用safe-alias选项 `node index.js query "SELECT field1 AS col1, field2 AS col2 FROM table" --safe-alias '{"col1":"中文名1","col2":"中文名2"}'`
* 执行key-set分页查询,SQL中需要添加占位符#{field},再指定排序字段和最大行数 `node index.js query "SELECT * FROM table WHERE id > #{id} ORDER BY id" --key-set-by 'id' --max-rows 3000`
## table-info
* 获取表结构 `node index.js table-info "dw.orders"`
## metadata
* 按业务分类搜索表名, 禁止连接head命令, `node index.js metadata "订单"`
## viz-sql
> 对SQL查询结果生成数据摘要并创建可视化图表,必须指定分组字段和度量字段
* 基本用法 `node index.js viz-sql <CSV文件路径> --group-by <分组字段> --measure <度量字段> --aggregation sum --type bar`
* 自定义图表 `node index.js viz-sql <CSV文件路径> --group-by <分组字段> --measure <度量字段> --aggregation avg --type line --title "标题" --x-axis-title "X轴" --y-axis-title "Y轴"`
* 支持的聚合方式: sum, avg, count, min, max
* 支持的图表类型: bar, line, pie, doughnut
领域知识.md 片段
<!--
- 文档规范
- 二级标题是业务域, 三级标题是子业务功能
- 参考现有格式增加新内容,主要描述这块业务的表和判断字段, 包括但不限于,文字描述、已有的SQL、代码片段。
-->
## 店铺
### 店铺知识
### 店铺表
### 渠道
## 交易
### 订单
#### 扩展字段 *extra*
#### 履约方式 (预订单)
#### 三方服务商配送方式
### 外卖通,三方订单
### 售后- END -
相关文章
