这个男人叫小帅。
拎着半杯冰美式晃进工位,键盘还残留着上周五的瓜子碎。他优雅地按下开机键,正准备点开《程序员养生指南》。
有个声音不合时宜的响起:"你的地址解析又双叒叕崩了!"
这个女人叫小美。
踩着红色高跟鞋由远及近,混有YSL黑鸦片香水与瑞幸椰云拿铁的硝烟味破门而入时,隔壁大壮默默扣上了防噪耳机。
"三里屯能识别成三亚度假村"
小帅戳着空格键上瓜子壳:"万一是用户想去海边收快递..."
"海你大爷!"
"想啥呢,今天 xx 股票又跌了",隔壁大壮的喋喋不休,把小帅拉回现实。
"上周上线的智能地址识别优化效果不错,写个文档沉淀沉淀,你要知道,你是组里的老大哥,光做完手上的事情是不行的,你要..."
这个男人叫小帅。翻开电脑,要开始沉淀了。
什么是智能地址识别
通过对非结构化文本进行语义解析,自动提取收件人、联系方式、省市区及详细地址等关键字段,并将其转化为结构化数据。例如:
"张三 13800138000 北京市海淀区中关村大街27号"↓↓↓{userName: "张三",tel: "13800138000",province: "北京市",city: "北京市",county: "海淀区",addressDetail: "中关村大街27号"}
在我们实际的业务场景中,地址解析虽非高频需求,但作为收银环节的终端触点,其准确率直接影响用户支付体验和物流履约效率,具有较高的业务价值权重。
业务实际场景
在服务的特产商家,节日高峰期间,店内客流激增,购买特产后的履约方式基本上都是通过快递邮寄到家,这就需要能确保每位消费者的快递地址能快速、准确地识别。
我们碰到的问题
最初,我们采用的方式是:三方地址识别API。该服务提供了以下功能:
-
省市区详细解析 -
邮编识别 -
经纬度信息提供
但在过程中我们发现,每周持续产生800+次识别异常
主要失败原因:
-
地址格式多样性(如"浙江省/杭州市/余杭区..."与"杭州余杭五常街道..."混用) -
非标准表述(用户输入"杭城西湖区文三路"),例如:杭州市上城区丁兰街道湖境天辰里 x 幢 xxx -
三方API服务中断(额度耗尽或计费异常)
系统缺陷:
-
无有效兜底机制 -
异常处理完全依赖人工介入
中间我们也通过前置利用正则对输入信息做处理,来提升成功率,逻辑处理繁琐不说,收效甚微,而且还影响了一部分能被三方识别成功的地址。
这些问题直接影响了业务的稳定性和用户体验,亟需一个更可靠的解决方案。
AI 切入的场景
结合前面几篇AI探索实践的主题相关的文章所述,我们迅速识别到这个是比较好的AI切入点,文字的智能识别以及结构化处理,不正好是 AI 擅长的场景吗? 通过对比,我们发现传统API方案存在两个刚性瓶颈恰好与LLM核心能力形成互补:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
但同时,我们也综合分析了一下使用AI可能存在的问题
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
综合考虑后,我们决定以三方API识别为主,AI识别为辅,如果三方API识别成功,则用三方的识别结果,反之用AI识别的结果。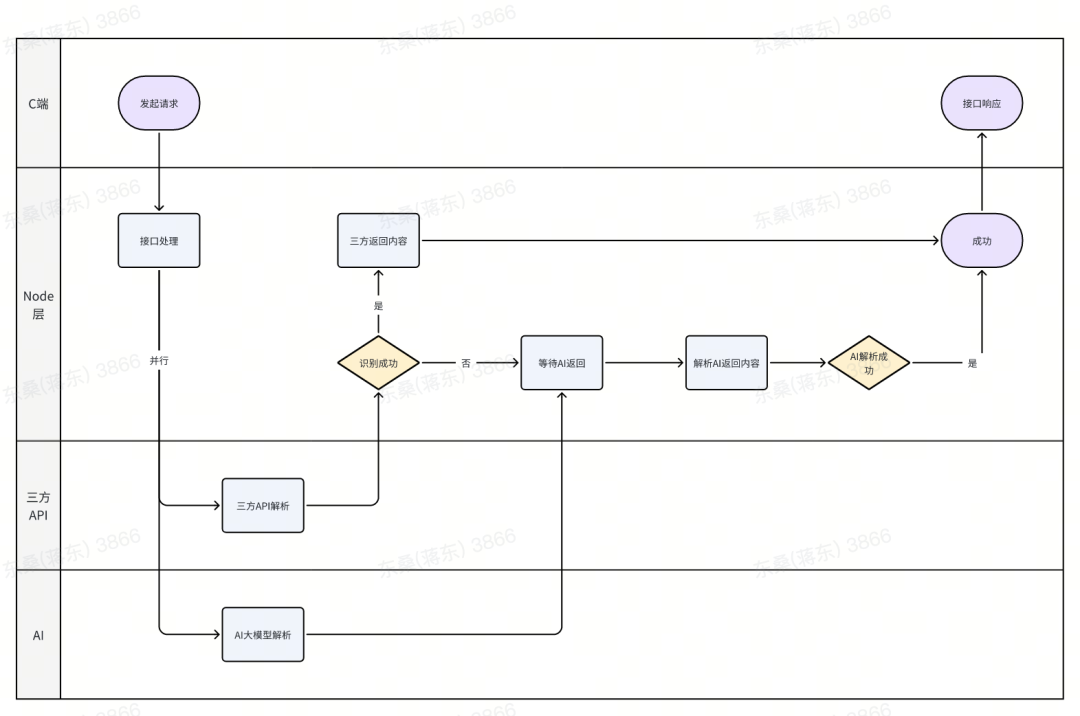
模型选择的考量
基于业务核心需求,我们对主流模型进行以下方面的考量:
-
AI识别字段的完整性。业务需要模型能够完整、准确地返回所有关键字段(如userName、tel、addressDetail、province、city、county、areaCode),以满足后续流程的结构化需求。 -
响应速度。线下收银场景对速度有严格要求,模型的平均响应速度必须在可接受范围内。 -
成本效益。需要在保证效果的前提下,兼顾调用成本,确保大规模业务场景下的经济性。 -
AI服务的稳定性。我们优先选择了官方API服务,确保模型能力的持续更新和服务的稳定可靠。 最终选型:综合考虑成本、性能和准确率,选择千问-plus作为主要模型。
伟大的提示词调试工程
基于选定的模型,我们设定了一版 提示词,来验证效果。
给你一段地址内容,按如下格式提取出以下字段:{userName: 收件人名字,tel: 手机号,addressDetail: 含乡镇街道的详细地址province: 省/直辖市/港澳台,city: 地级市/省、自治区管辖的地区/省直辖县/自治州/盟等地级行政区,county: 市辖区、县级市、县、自治县、旗、自治旗、特区、林区等县级行政区,areaCode: 地区代码}要求:1. 以JSON格式返回(非代码块),不要返回多余的内容(解释、说明等),未提取到的字段默认给空字符串。2. 字段 province/city/county,如果为空,自动根据中国完整的行政区划和详细地址准确推导出来。3. 如果是香港、澳门、直辖市,city 直接和 province 一样。4. areaCode 需要根据获取到的省、市、区、详细地址进行推导地址内容如下:${rawAddress}
从结果上来看,准确率基本符合预期,但是响应时间普遍在 3-5s,如上所说我们的使用场景是在收银场景,时间就是效率。
通过 LLM,由原来的1s-2s -> 3-5s,响应上直接翻倍,这在交付上是不能接受的。
说来也巧,在翻阅解决方案的时候,我们注意到,LLM的响应速度与返回内容的token数量密切相关。JSON格式由于包含大量结构性字符(如括号、引号、字段名等),在大模型生成和传输时会消耗更多token,导致响应变慢。偶然间,我们尝试将返回格式改为TSV(Tab Separated Values,制表符分隔值)——只需一行数据,字段之间用制表符分隔,无需多余结构。比如:
张三 13800138000 中关村大街27号 北京市 北京市 海淀区这种格式极大地减少了token数量,模型生成速度显著提升。我们将提示词调整为:
将以下地址解析为TSV格式,仅返回一行数据,字段之间用制表符(t)分隔,按照以下固定顺序输出,不要返回多余的内容(解释、说明等),未提取到的字段给空字符串:userName tel addressDetail province city county解析规则:1. userName: 收件人名字,2. tel: 手机号,3. addressDetail: 含乡镇街道的详细地址(不用包含省市区)4. province: 省/直辖市/港澳台,5. city: 地级市/省、自治区管辖的地区/省直辖县/自治州/盟等地级行政区,6. county: 市辖区、县级市、县、自治县、旗、自治旗、特区、林区等县级行政区,7. 字段 province/city/county,如果为空,自动根据中国完整的行政区划和详细地址准确推导出来。8. 如果是香港、澳门、直辖市,city 直接和 province 一样。地址内容如下:${rawAddress}
平均响应时间控制在 2-3s,跟原来 API 调用接近。 当然这种方案并不适用于别的场景,JSON 稳定、好解析,TSV 只是比较适用于我们这个业务场景,结构简单,希望响应更快。
数据成效(近30天)
|
|
|
|
|---|---|---|
|
|
|
|
其中AI兜底成功:占三方失败量的81.31%
后续优化
在前文中我们提到,AI方案虽然具备强大的文本理解能力,但其返回内容并不总是完全可控。通过埋点分析AI识别失败的场景,我们发现有相当一部分失败案例,是因为模型将返回内容包裹在代码块标记内,导致后续解析流程无法正确提取所需字段。例如:
```plaintextn张三 t电话t详细地址t湖南省t长沙市t望城区n``````ntuserNametttelttaddressDetailttprovincetcitytcountyntttt详细地址t天津市t天津市t滨海新区n```
为此,我们在后续优化中采取了两方面措施:
-
提示词优化:在提示词中明确要求“不要返回代码块、不要添加多余的格式说明”,并通过多轮调试提升模型输出的稳定性。 -
解析容错增强:在解析逻辑中增加对代码块包裹内容的兼容处理,自动去除首尾的```标记,提升整体识别成功率。
通过这两项优化,AI识别的可控性和健壮性得到了进一步提升。
经验的沉淀
-
通过构建"三方API为主,LLM兜底"的混合架构,实现1+1>2的效果。传统方案保障核心场景的稳定性,AI方案突破长尾问题的处理边界。 -
业务场景里,以往费尽心思优化的“算法”,有些在现在可以很容易被 LLM 代替或者加持,效果会好上很多。 -
从萌生AI替代方案的想法到产出可用原型,我们建立快速验证闭环并上线观察效果 -
重视提示词工程,将提示词调试视为精密仪器校准 -
TSV的引入,不仅解决了响应慢的问题,也让我们对“格式工程”有了更深刻的认知:在大模型应用中,合理设计输入输出格式,往往能带来意想不到的效率提升。
尾声
这个男人叫小帅,他合上了电脑。 "文章给你发过去了,原来TSV里藏着的不是数据,是认知升维!"
相关文章
