人们普遍认为Scaling Law(缩放定律)是一种通向 AGI 的可能的路径,即持续扩大数据规模和模型规模可以显著提升模型的智能水平。然而,无论是密集模型还是专家混合(MoE)模型,研究和工业界在有效扩展极大规模模型方面的经验有限。
关于这一扩展过程的许多关键细节,直到最近发布的DeepSeek V3、R1模型才得以披露,让大家了解到超大规模 MoE 模型的效果及实现方法(强化学习和知识蒸馏)。
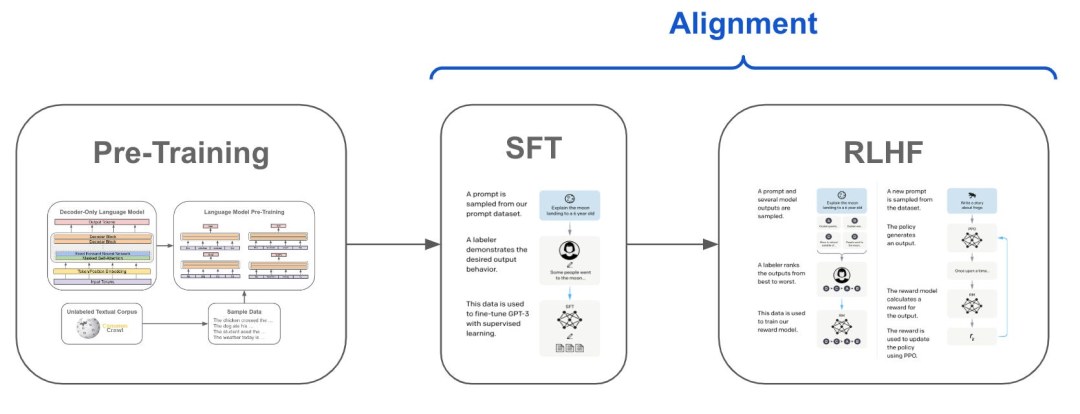
与此同时,阿里通义千问团队正在研发超大规模的 MoE 模型 Qwen2.5-Max,一个经过超过20万亿个标记的预训练,并进一步通过精心策划的监督微调(SFT)和基于人类反馈的强化学习(RLHF)方法进行后训练的大规模MoE模型。
Qwen2.5-Max全面拥抱DeepSeek技术路线。

一、稠密模型 or MoE模型
-
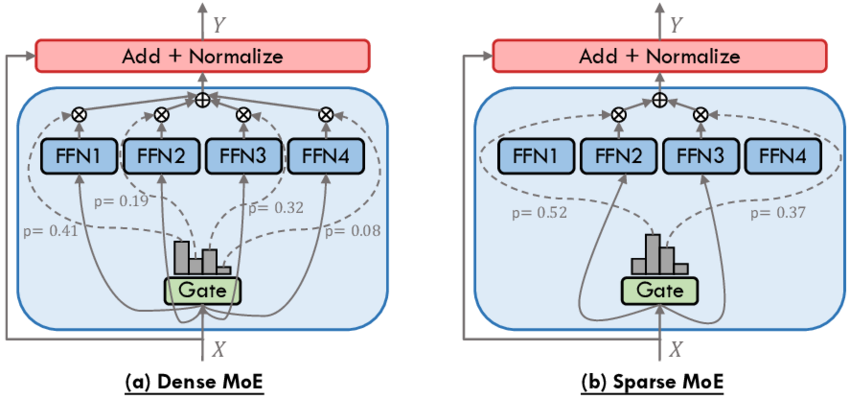
专家协同工作:MoE模型通过多个“专家”子模型协同工作,能够更有效地处理特定任务。这种分工合作的方式类似于一个团队中各个专家各司其职,共同完成复杂的项目,从而提高了整体效率和效果。
-
智能选择专家:MoE架构能够智能选择适当的“专家”模型来处理输入数据,从而优化计算资源的使用。这意味着在处理不同任务时,只有相关的专家子模型会被激活,降低了不必要的计算开销。
大模型厂商相继放弃Dense选择MoE,这就像当年移动互联网时代,选择水平复制的微服务架构,而不是继续垂直扩展单机性能。
在基座模型的对比中,将Qwen2.5-Max与领先的开源MoE模型DeepSeek V3、最大的开源稠密模型Llama-3.1-405B及开源稠密模型前列的Qwen2.5-72B进行了对比。结果显示,MoE模型(如Qwen2.5-Max和DeepSeek V3)得分高于Dense模型(如Llama-3.1-405B和Qwen2.5-72B),具体对比结果如下图所示。

二、预训练和后训练
-
监督微调(SFT):通过使用大量的人工标注数据对预训练模型进行微调的过程。
-
基于人类反馈的强化学习(RLHF):通过收集人类对模型输出的反馈,并使用强化学习算法对模型进行优化。Qwen2.5-Max结合了多阶段强化学习,包括离线学习DPO和在线学习GRPO。
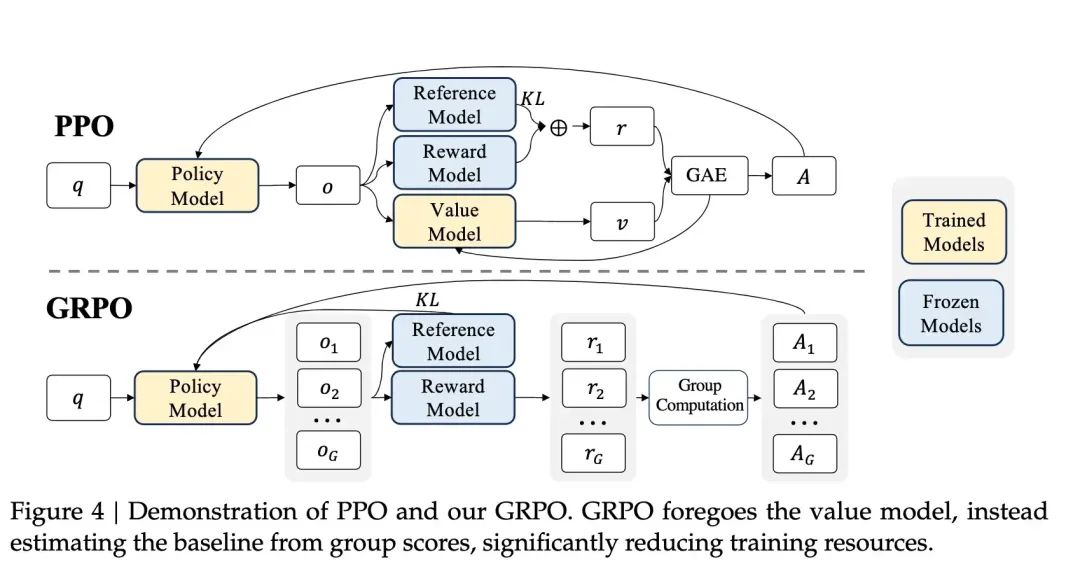
Qwen2.5-Max为什么拥抱DeepSeek技术路线?尽管Qwen2.5-Max的预训练及后训练流程与OpenAI相似,均基于大规模数据、先进架构及监督、强化学习,但其独特之处在于采用优化的GRPO强化学习算法,并通过知识蒸馏替代大规模SFT进行后训练,这些策略与DeepSeek在提升模型性能与效率上的探索相契合,因此被视为拥抱DeepSeek技术路线。
-
GRPO(群组相对策略优化):通过组内相对奖励来优化模型,而不需要额外的价值模型(critic model)。在传统的强化学习中,模型(称为“策略模型”)会根据环境给出的奖励信号来调整自己的行为,这通常涉及一个额外的模型(称为“价值模型”)来评估当前策略的好坏。GRPO简化了这个过程,它不需要价值模型,而是通过组内相对奖励来优化策略模型。
-
知识蒸馏(Distillation):一种模型压缩和知识迁移的方法,它通过将大型教师模型中的知识转移到小型学生模型中,从而提高学生模型的性能。这种方法通常用于减少模型的计算成本,同时保持或提升模型的性能。
一文搞懂DeepSeek - 强化学习和蒸馏
相关文章
