
模力方舟 Embedding 与 Reranker 模型现已全部开放免费使用,RAG 架构必备的检索向量和重排序能力,即刻零成本上手!
模力方舟现已正式上线来自 Jina AI 的新一代通用向量模型 ——Jina-Embeddings v4,访问链接即可在线体验:https://ai.gitee.com/serverless-api?model=jina-embeddings-v4。
作为 Jina 系列嵌入模型的第四代版本,Jina-Embeddings v4不仅支持文本、图像等多模态输入统一编码,更首次在图文场景下实现了多向量检索(Late Interaction)能力,在复杂视觉文档、多语言问答、代码搜索等多个关键任务中取得了全面领先的性能表现。
统一图文表示,模型架构全面进化
Jina-Embeddings v4构建于Qwen2.5-VL-3B-Instruct基座模型之上,在底层架构上实现了图文统一表示的闭环。与传统的 CLIP 双塔架构不同,v4 模型采用共享编码路径,图像先通过视觉编码器转化为 token 序列,与文本一起输入语言模型,进行上下文感知处理。这种方式显著缩小了图文语义空间中的模态差距(modality gap),同时具备更强的跨模态语义理解能力。
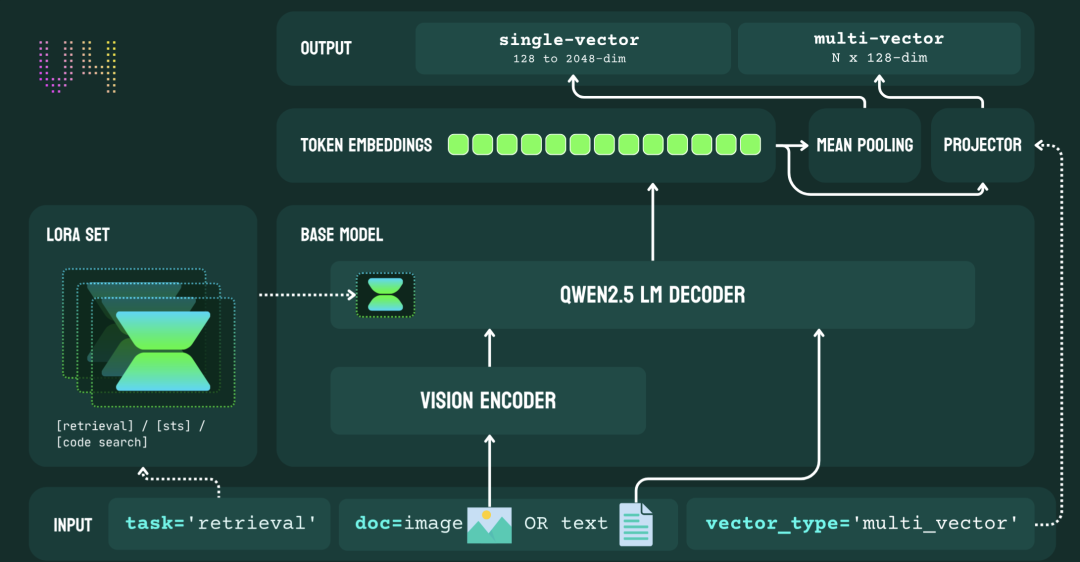
模型支持两种输出形式:
-
单向向量(dense embedding):默认输出 2048 维,可截断至 128 维以适配轻量部署需求; -
多向量(multi-vector embedding):每个 token 输出 128 维,可用于构建支持 Late Interaction 的高精度检索系统。
这两种模式均可在推理阶段灵活选择,便于适配不同的存储与算力环境。
三类任务适配器,覆盖更多应用场景
为了支持更复杂的应用需求,Jina-Embeddings v4内置三类基于 LoRA 微调的任务适配器(每类仅 60M 参数),可在推理阶段动态加载,分别针对:
-
异构检索(query-document retrieval):适合短查询与结构化文档检索; -
语义匹配(text matching):适合对称结构任务,如问答匹配、句子相似度; -
代码检索(code retrieval):支持自然语言与代码之间的双向语义理解。
这一设计不仅实现了「多任务共享主干 + 轻量化适配」的目标,也极大提升了模型在多样场景下的落地能力。
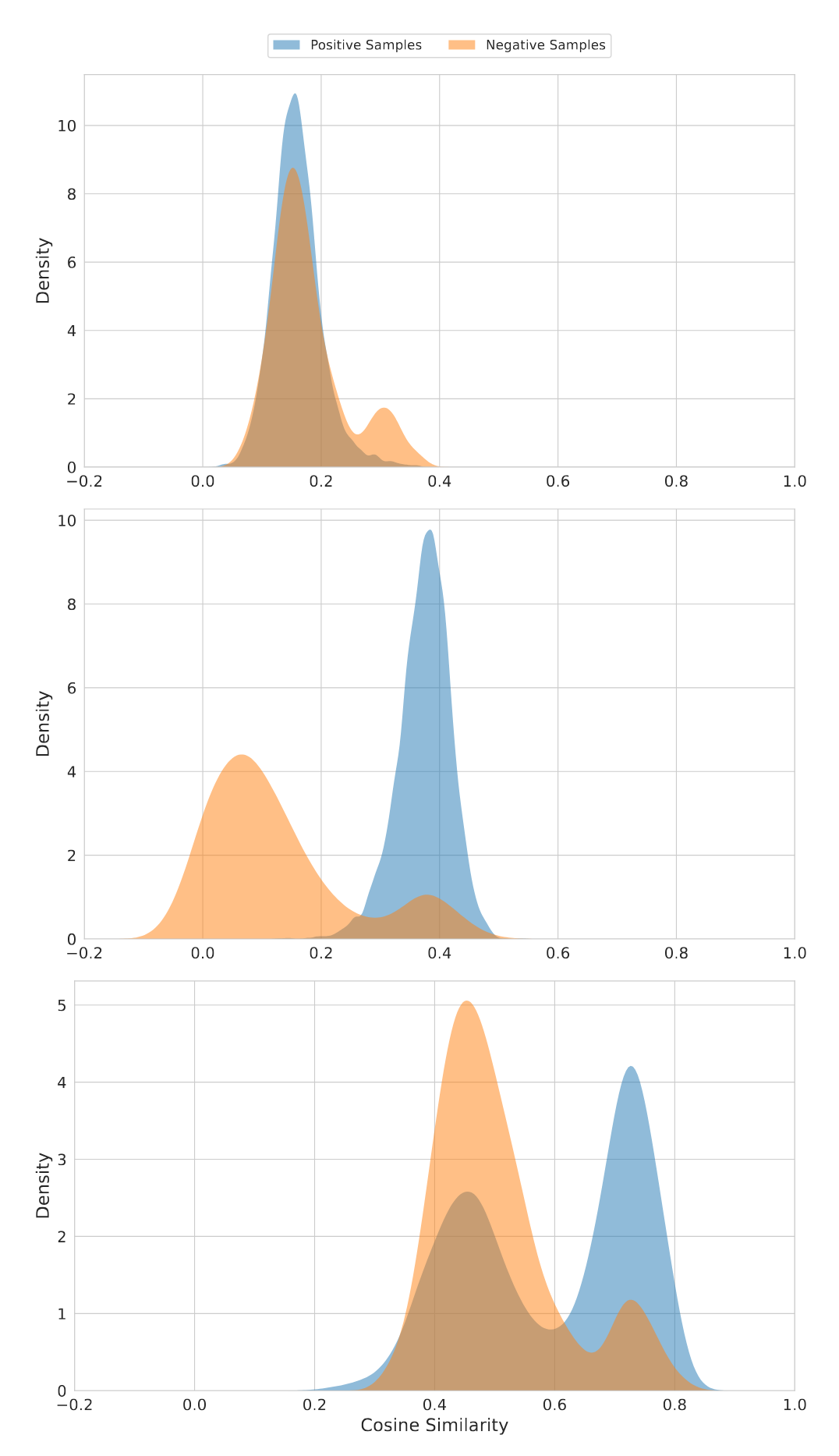
多项评测领先,特别优化视觉文档任务
Jina-Embeddings v4在多个标准评测中表现突出,尤其在图文匹配与视觉文档检索任务中大幅领先。
得益于共享编码器架构与多向量表示机制,v4 能够精准建模图表、表格、说明文档等复杂视觉内容,在新基准 Jina-VDR 和 ViDoRe 上显著优于 CLIP 与同类模型。
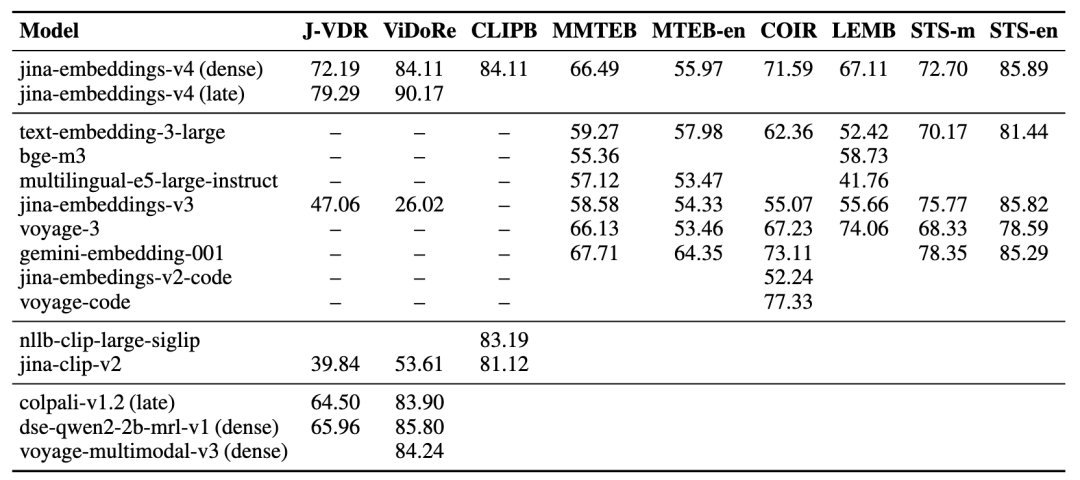
同时,Jina-Embeddings v4在 MTEB 多语言语义匹配、长文本检索与代码搜索等任务中也保持强劲性能,展现出良好的通用性与扩展性。
Jina-Embeddings v4现已在模力方舟正式上线,点击文末阅读原文,即可在线体验图文检索模型的新突破:https://ai.gitee.com/serverless-api?model=jina-embeddings-v4
模力方舟携手国产 GPU 伙伴,已将模型广场中 Embedding 与 Reranker 模型全部开放免费使用——其中包括今天介绍的Jina-Embeddings v4 和 4096 维的 Qwen3-Embedding-8B。
RAG 架构必备的检索向量和重排序能力,即刻零成本上手!

相关文章
