摘要
本文深入探讨了人工智能(AI),特别是大语言模型(LLM)与自主智能体(Agentic Agent),在网络安全领域的革命性应用。文章首先剖析了AI技术替代传统规则检测的根本优势,并系统性地阐述了模型微调、提示词工程等核心使能技术。通过对AI在安全运营中心(SOC)多个核心场景中的应用进行分析,本文展示了其在威胁检测、事件响应、威胁狩猎及漏洞管理等方面的实践价值。在此基础上,文章进一步展望了以自主智能体为核心的下一代安全范式,探讨了其架构、实现路径与实践前景。最后,文章总结了当前技术落地面临的挑战,并对未来人机协同、自主进化的发展趋势进行了预测。
1.0 导论:网络安全的新范式——从规则到智能
随着网络攻击的复杂性与自动化程度不断升级,依赖静态规则和签名的传统安全防御体系正面临前所未有的挑战。人工智能技术的崛起,正推动网络安全从被动的“规则驱动”向主动的“智能驱动”进行范式转移。
1.1 传统规则检测的困境
传统的安全工具,如入侵检测系统(IDS)和防火墙,长期依赖规则引擎这一核心机制。该引擎通过匹配预定义的攻击签名或行为模式来识别威胁。然而,在当今的威胁环境下,此模式的局限性愈发凸显[1]:
-
• 反应滞后:规则库的更新总是滞后于新威胁的出现,对于零日漏洞、变种恶意软件和高级持续性威胁(APT)的检测能力有限。 -
• 易于规避:攻击者可通过代码混淆、加密通信或微调攻击手法,轻松绕过僵化的规则匹配。 -
• “告警疲劳”:为追求覆盖率,规则往往设置得较为宽泛,导致产生海量误报,淹没真实的安全事件,极大消耗了安全分析师的精力。 -
• 维护成本高昂:规则库需要安全专家持续手动更新和优化,不仅成本高昂,且响应效率低下。
1.2 AI驱动检测的技术演进
人工智能,特别是机器学习与深度学习,为网络安全检测带来了根本性变革。AI驱动的检测系统不再依赖僵化的规则,而是通过从海量数据中学习,构建能够识别“异常”的动态模型。
其核心优势在于[1, 2]:
-
• 上下文感知与行为分析:AI能够分析网络流量、用户行为、系统日志等多元数据,建立“正常行为”的动态基线,并实时检测任何偏离基线的可疑活动。 -
• 持续学习与自适应:AI模型能从新的攻击案例和安全事件中持续学习,自动优化其检测能力,动态适应不断演变的威胁。 -
• 处理海量异构数据:AI能以超越人类的速度和规模处理、关联和分析来自不同来源的结构化与非结构化数据,发现隐藏在海量信息中的微妙攻击信号。
1.3 全面对比:规则引擎 vs. 智能大脑
为了更直观地展示AI驱动检测的代际优势,我们从多个维度对其与传统规则检测进行对比。

|
|
传统规则检测 | AI驱动检测 |
| 检测原理 |
|
|
| 威胁覆盖 |
|
|
| 响应速度 |
|
|
| 准确率 |
|
|
| 适应性 |
|
|
| 维护成本 |
|
|
2.0 核心使能技术:为网络安全量身打造AI能力
通用的大语言模型(LLM)如同一个拥有渊博知识但缺乏专业技能的“通才”。要使其成为网络安全领域的专家,必须借助微调(Fine-tuning)和提示词工程(Prompt Engineering)等核心技术,为其注入领域知识并引导其精确执行任务。
2.1 基石:作为安全智能引擎的大语言模型(LLM)
LLM,特别是基于Transformer架构的模型,构成了现代AI安全应用的技术基石。其核心的**自注意力机制(Self-Attention Mechanism)**使其能够高效处理序列数据,并捕捉数据点之间的长距离依赖关系。这一特性使其在处理网络安全领域的非结构化和半结构化数据时具有天然优势[2]:
-
• 日志分析:理解不同日志条目间的上下文关联,还原复杂的攻击序列。 -
• 代码审计:分析代码的语义和逻辑,而非仅仅是语法,从而发现深层次的逻辑漏洞。 -
• 威胁情报解读:从安全报告、技术文章和暗网论坛等海量文本中提取关键的威胁指标(IoCs)和攻击者战术、技术与规程(TTPs)。
2.2 关键步骤:模型微调,锻造领域专属技能
微调是将已在通用语料上预训练的LLM适配到网络安全这一特定领域的过程,是提升模型专业能力和任务性能的决定性步骤。
2.2.1 微调的必要性与数据构建
通用LLM缺乏对特定安全术语、攻击模式和工具的深入理解。通过在高质量的网络安全数据集上进行微调,可以向模型注入领域知识,使其分析更专业、结论更准确。构建微调数据集是成功的关键,其流程通常包括[3]:

-
1. 数据收集:从安全日志、CVE库、恶意软件样本、安全报告、攻防演练数据等多源渠道收集原始数据。 -
2. 数据清洗与预处理:去除无关信息和噪声,进行格式标准化。 -
3. 指令标注与质量控制:以“指令-响应”(Instruction-Response)对的形式构建监督学习样本。例如,将一条告警日志作为“指令”,其对应的分析结论作为“响应”。此步骤通常需安全专家参与以保证标注质量。 -
4. 数据增强:利用同义词替换、回译或LLM自身生成合成数据,扩充数据集规模和多样性。 -
5. 数据集划分与验证:将数据划分为训练集、验证集和测试集,并进行质量校验和迭代优化。
2.2.2 微调技术选型与对比
根据可用资源和性能要求,可以选择不同的微调技术[3]:
-
• 全量微调(Full Fine-tuning):更新模型的所有参数。此方法理论上性能最佳,但需要巨大的计算资源(GPU显存)和存储空间,对于参数量动辄数十亿的LLM而言成本极高。 -
• 参数高效微调(Parameter-Efficient Fine-tuning, PEFT):一种更具性价比的策略,它冻结大部分预训练模型参数,仅微调一小部分新增或指定的参数。 -
• LoRA (Low-Rank Adaptation):PEFT中最主流的技术之一。它通过在模型的权重矩阵旁增加两个低秩矩阵(Adapter)进行微调,可训练参数量通常不到总参数的1%。 -
• QLoRA (Quantized LoRA):LoRA的进一步优化,通过对模型权重进行4-bit量化,极大降低了显存占用,使得在消费级GPU上微调大型模型成为可能。
|
|
可训练参数量 | 计算/存储成本 | 性能表现 | 适用场景 |
| 全量微调 |
|
|
|
|
| LoRA/QLoRA |
|
|
|
|
2.3 交互技术:面向安全任务的提示词工程
如果说微调是为AI“植入知识”,那么提示词工程就是指导AI“如何运用知识”的艺术。一个精心设计的提示词能够显著提升LLM在特定安全任务上的表现。
2.3.1 高效安全提示词设计原则
设计高效的安全提示词需遵循以下原则[4]:
-
• 角色设定(Role-playing):为LLM分配一个明确的专家角色,如“你是一名资深的网络安全分析师”,这能引导模型调用相关的知识库和语言风格。 -
• 上下文与示例(Few-shot Learning):在提示词中提供清晰的背景信息和一到两个成功示例,帮助模型更好地理解任务要求。 -
• 思维链(Chain-of-Thought, CoT):引导模型分步骤思考,将复杂任务分解为一系列简单的子任务,从而提升复杂推理任务的准确性。例如:“请先分析此日志,然后识别攻击源IP,最后判断其攻击意图。” -
• 检索增强生成(Retrieval-Augmented Generation, RAG):将LLM与外部知识库(如最新的威胁情报、内部资产信息)连接,使其能够基于实时、准确的信息进行回答,有效缓解模型知识陈旧和“幻觉”问题。
2.3.2 提示词自身的安全攻防
当LLM被用于处理不可信的外部输入时,其提示词本身也可能成为攻击向量。防御这些攻击是实践中的关键环节[4]:
-
• 提示词注入(Prompt Injection):攻击者通过构造恶意输入,诱导LLM忽略原始指令,转而执行攻击者的命令。 -
• 越狱(Jailbreaking):通过角色扮演、情景模拟等方式,绕过模型的安全护栏,使其生成有害、非法或不道德的内容。
防御策略包括:
-
• 输入过滤与净化:对用户输入进行严格审查,过滤可疑指令和恶意字符。 -
• 输出内容审查:在将模型输出展示给用户或传递给其他系统前进行检查。 -
• 指令与数据分离:使用分隔符或特定格式,清晰地将系统指令与待处理的用户数据隔离开来。 -
• 权限最小化原则:若LLM需调用外部工具,应严格限制其权限,避免被恶意利用执行高风险操作。
3.0 深度应用场景:AI驱动的新一代安全运营
AI技术,特别是LLM,正在全面渗透安全运营中心(SOC)的各个环节,从被动的告警响应升级为主动、智能的威胁管理。
3.1 智能威胁检测与告警研判
传统SOC面临的最大痛点之一是海量告警和高误报率。AI通过深度分析和上下文关联,能够极大地提升检测的精准度和告警的有效性[1]。
-
• 基于行为的异常检测:利用用户和实体行为分析(UEBA)技术,AI能够学习个人、设备或服务器的正常活动模式,并实时标记任何偏离基线的可疑行为,如异常时间登录、异常数据访问等。 -
• 恶意软件与钓鱼邮件识别:LLM能深入分析文件、脚本和邮件内容的语义,识别传统基于签名的杀毒软件无法检测的变种恶意软件和精心伪装的鱼叉式钓鱼邮件。 -
• 自动化告警降噪与优先级排序:AI能够自动关联来自不同安全工具的告警,将多个相关告警聚合成一个高级别安全事件,并根据资产重要性、攻击阶段和潜在影响对事件进行智能评级,帮助分析师聚焦于真正的威胁。
3.2 自动化事件响应与溯源分析
在确认安全事件后,快速响应和精准溯源是控制损害的关键。AI在此环节扮演了“智能分析师”和“自动化执行者”的角色。
-
• 自动化日志分析与攻击链还原:LLM可以快速处理来自SIEM、EDR等系统的海量日志,自动识别攻击者的活动轨迹,并以MITRE ATT&CK®等框架为基础,还原出完整的攻击链。 -
• 生成结构化调查报告:AI能够将复杂的分析过程和发现,自动汇总成一份清晰、结构化的调查报告,包含事件摘要、影响范围、攻击手法和溯源结果,极大缩短报告撰写时间。 -
• 推荐并执行响应动作:基于对事件的分析,AI可以推荐最佳的遏制和根除策略,例如生成用于防火墙的封禁规则、编写用于隔离主机的脚本,甚至在授权下自动执行这些操作,显著缩短平均响应时间(MTTR)。
3.3 主动式威胁狩猎
威胁狩猎要求安全团队像攻击者一样思考,主动在网络中搜寻未知威胁的蛛丝马迹。AI使这一高级活动变得更加高效和可规模化[5]。
-
• 自动化狩猎假设生成:基于最新的威胁情报、行业攻击趋势或内部环境的异常变化,AI可以自动生成高价值的狩猎假设(Hypothesis)。 -
• 全域数据中的TTPs识别:威胁狩猎的核心是在海量数据中寻找攻击者的战术、技术和规程(TTPs)。AI能够在大规模日志和流量数据中,高效地搜索与特定TTPs相关的行为模式,如横向移动、权限提升、数据外泄等。
3.4 智能化漏洞管理与代码安全
AI正在推动安全能力“左移”,将安全检测和修复融入软件开发的早期阶段,从源头上减少漏洞[2]。
-
• 增强静态应用安全测试(SAST):LLM能够理解代码的上下文和逻辑,发现传统SAST工具难以识别的复杂漏洞,并提供具体的代码修复建议。 -
• 自动化漏洞报告分析:AI可以自动解析CVE漏洞公告、安全补丁说明等文档,快速评估漏洞对企业内部资产的实际影响,并对修复工作的优先级进行排序。 -
• 恶意代码分析辅助:对于恶意软件样本,AI可以辅助逆向工程师进行分析,例如解释混淆的代码片段、识别恶意代码家族、分类其行为等。
4.0 未来范式:迈向自主安全的Agentic Agent
如果说当前AI在安全领域的应用主要是作为人类分析师的“增强工具”,那么自主智能体(Agentic Agent)则预示着一个全新的“自主安全”范式。自主智能体不仅能执行指令,更能自主地感知环境、制定计划、调用工具并完成复杂目标。
4.1 从自动化到自主:Agentic AI概述
Agentic AI的核心特征在于其自主性(Autonomy)和能动性(Agency)。一个典型的自主智能体系统通过一个循环进行工作:感知(Perception)-> 规划(Planning)-> 行动(Action)-> 观察(Observation),并在此过程中不断学习和调整[5]。
-
• 核心能力: -
• 规划(Planning):将一个宏大目标(如“调查并处置一次安全事件”)分解为一系列可执行的子任务。 -
• 工具使用(Tool Use):理解并调用外部工具(API)来获取信息或执行操作,例如查询病毒库、运行扫描器或隔离一台主机。 -
• 反思(Reflection):对自身的行为和结果进行评估和批判,从中学习并优化未来的决策。 -
• 多智能体协作(Multi-Agent Collaboration):多个专职智能体(如“侦察Agent”、“分析Agent”、“响应Agent”)可以协同工作,共同完成复杂的安全任务。 -
• 主流框架:业界已涌现出多个用于构建自主智能体的开源框架,如LangChain Agents、AutoGen、CrewAI等,它们极大地降低了开发门槛。
4.2 核心架构:基于MCP的工具集成与协同
为使自主智能体能够与现实世界的安全工具进行交互,需要一个标准化的“连接层”。MCP(Model-Controller-Proxy或称模型-控制器-代理)服务应运而生,它充当了智能体与各类安全工具(SIEM, SOAR, EDR等)之间的桥梁和代理[6]。
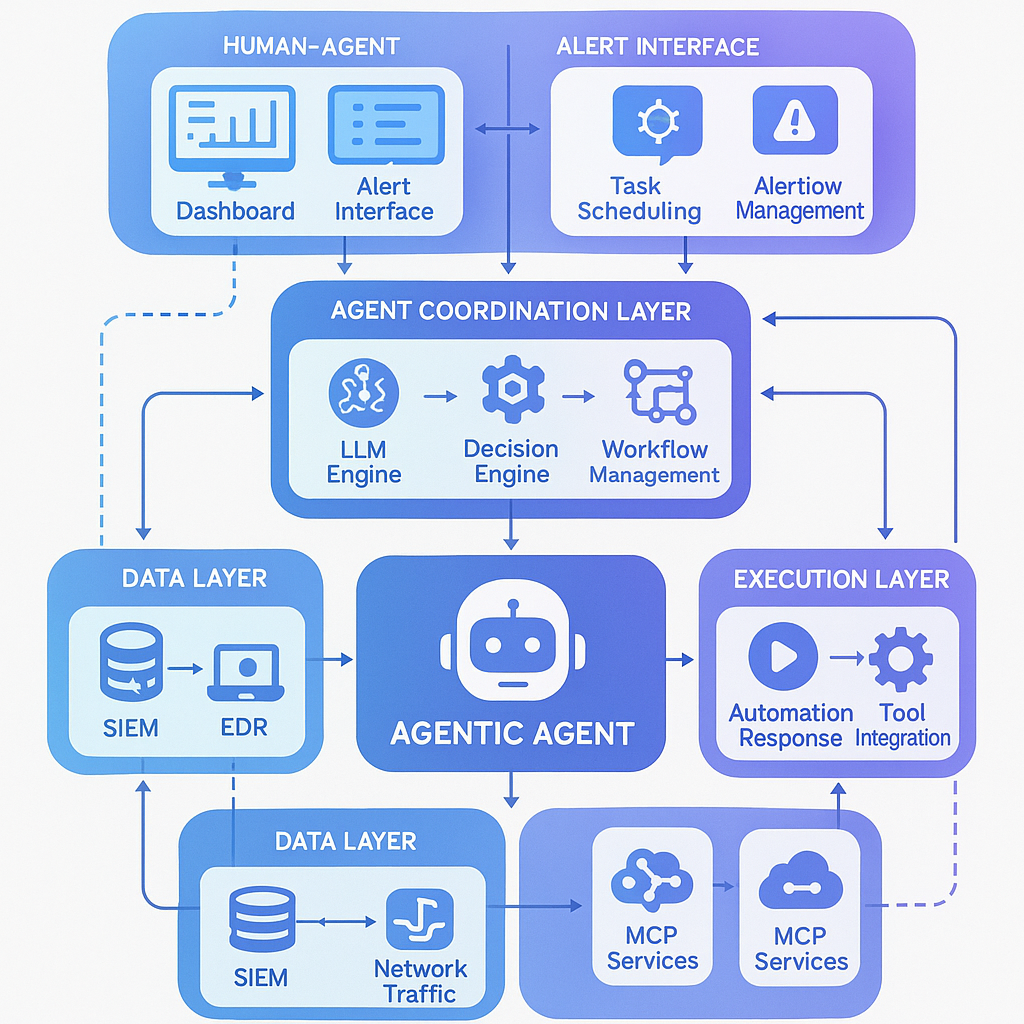
MCP的工作原理:
-
1. 工具注册:各种安全工具通过MCP服务将其能力(以API形式)注册给智能体。 -
2. 动态调用:智能体在规划任务时,可以查询MCP服务,了解有哪些可用工具,然后生成对这些工具API的调用请求。 -
3. 安全执行:MCP服务负责安全地执行这些调用,并将结果返回给智能体。 -
4. 统一编排:通过MCP,智能体可以无缝地编排多个不同厂商的安全工具,形成一个统一、协同的行动能力网络。
4.3 实践展望:自主安全运营场景
在自主智能体和MCP架构的支持下,未来的安全运营将呈现高度自主化的形态[7]:
-
• 自主风险评估:智能体可以7x24小时不间断地监控企业资产,主动发现配置错误、过期软件和潜在漏洞,并自动执行修复或创建工单。 -
• 自主事件响应:当检测到安全事件时,一个“事件响应总管Agent”可以被激活。它会自主协调“日志分析Agent”、“威胁情报Agent”和“端点响应Agent”,在无需或极少人工干预的情况下,完成从告警确认、溯源分析、威胁清除到事后报告的完整流程。 -
• 自主威胁狩猎:智能体可以基于对全球威胁态势的持续学习,自主地在企业内部网络中进行“狩猎”,动态生成并验证狩猎假设,寻找潜伏的高级威胁。
5.0 实施与评估:构建可信赖的AI安全体系
成功地将AI集成到网络安全体系中,不仅需要强大的技术,还需要科学的选型标准和严谨的评估框架,以确保其有效、可靠且安全。
5.1 AI模型选型标准
选择合适的LLM是构建AI安全应用的第一步。决策过程应综合考虑应用场景、性能要求和部署方式等多个因素[2]。
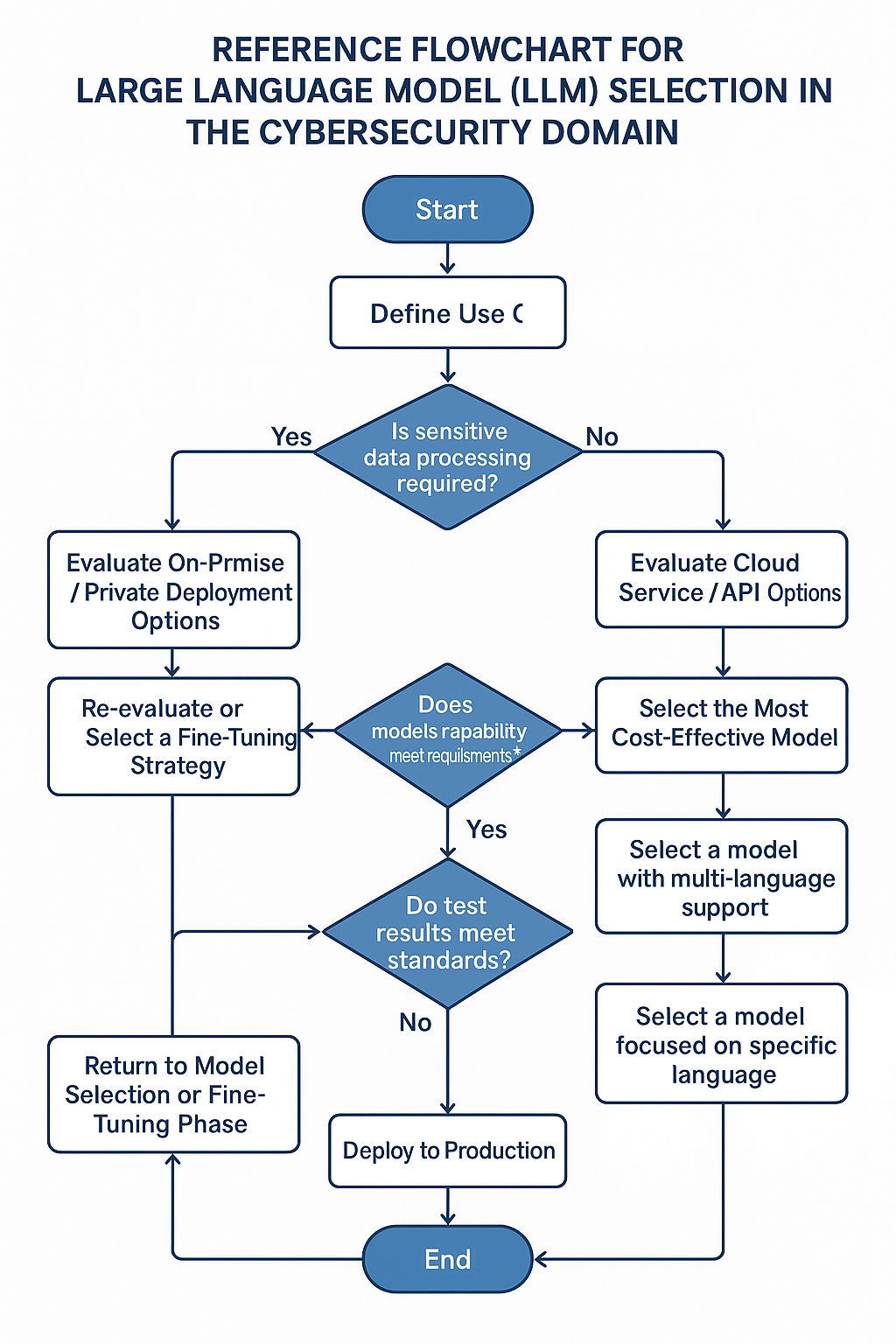
-
• 性能与能力: -
• 推理速度:对于实时检测等场景至关重要。 -
• 上下文长度:决定了模型一次性处理信息(如长篇日志或代码文件)的能力。 -
• 代码与多语言能力:对于代码审计和全球威胁情报分析等任务是必需的。 -
• 模型安全性: -
• 抗注入与抗越狱能力:模型抵御恶意提示攻击的能力。 -
• 数据隐私保护:模型在处理敏感数据时的保护机制,尤其在私有化部署时。 -
• 部署与成本: -
• 开源 vs. 闭源:开源模型灵活性高、可控性强,但需要自行部署维护;闭源模型通常性能更强、开箱即用,但有API成本和数据隐私顾虑。 -
• API成本:对于使用闭源模型的应用,API调用成本是重要的经济考量。
5.2 效果评估框架与指标
为科学地衡量AI安全应用的效果,需建立一个多维度的评估框架,涵盖模型的通用能力、特定任务表现以及安全可信度[2]。
-
• 评估框架: -
• 公开基准:可使用如SuperCLUE、OpenCompass等通用大模型评测平台,对模型的基础能力进行评估。 -
• 领域基准:针对网络安全领域,需要构建或使用特定的评测基准(如CyberMetric等),来评估模型在专业任务上的表现。 -
• 关键性能指标(KPIs): -
• 通用NLP指标: -
• BLEU/ROUGE:用于评估生成文本(如安全报告摘要)的质量。 -
• Perplexity:衡量模型语言建模能力的指标。 -
• 检测/分类任务指标: -
• 准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数:评估模型在恶意代码检测、钓鱼邮件识别等任务上的性能。 -
• RAG系统指标: -
• 相关性(Relevance)、忠实度(Faithfulness)、事实准确性(Factual Accuracy):评估模型在结合外部知识库回答问题时的表现。 -
• 安全与可信度指标: -
• OWASP LLM Top 10:基于此框架测试模型在提示注入、数据泄露、不安全输出等方面的鲁棒性。 -
• “LLM即评判”(LLM-as-a-judge):利用一个强大的LLM来评估另一个模型输出的质量和安全性,尤其适用于需要细致理解和复杂推理的任务。
6.0 挑战与展望:在智能时代中航行
尽管AI为网络安全带来了前所未有的机遇,但其深度应用之路并非坦途。我们必须清醒地认识到当前面临的挑战,并积极拥抱未来的发展趋势。
6.1 当前的挑战与风险
-
• 技术挑战: -
• 模型“幻觉”(Hallucination):LLM可能会生成看似合理但实际上错误或捏造的信息,这在要求高度严谨的安全决策中是不可接受的。 -
• 算法的“黑箱”问题:深度学习模型的决策过程往往缺乏透明度和可解释性,这使得在安全审计和事件复盘时难以追溯其判断依据。 -
• 安全风险: -
• 对抗性攻击(Adversarial Attacks):攻击者可通过对输入数据进行微小、人眼难以察觉的扰动,来欺骗AI模型做出错误的判断。 -
• 数据投毒(Data Poisoning):在模型训练阶段,向训练数据中注入恶意样本,从而在模型中植入“后门”或降低其准确性。 -
• 模型能力滥用:强大的AI能力也可能被攻击者利用,用于生成更逼真的钓鱼邮件、自动化漏洞挖掘或编写变种恶意软件。 -
• 资源与成本门槛: -
• 训练和部署先进的AI模型需要大量的计算资源(高端GPU)和高质量的标注数据,这对许多组织来说是一笔巨大的投资。 -
• 市场对兼具AI和网络安全知识的复合型人才需求巨大,人才短缺成为推广应用的一大瓶颈。
6.2 未来发展趋势
展望未来,网络安全将不再是人与工具的简单组合,而是一个由人、AI和智能体构成的、动态进化的智能生态系统[7]。
-
• 深度人机协同:AI将更多地作为安全分析师的“智能副驾”(Copilot)和“能力倍增器”。AI负责处理海量、重复性的数据分析工作,提供决策建议,而人类专家则专注于复杂威胁的研判、战略规划和最终决策,实现1+1>2的效果。 -
• 多智能体协作(Multi-Agent Systems):未来的安全防御可能由一个“智能体军团”来执行。通过Agentic Mesh等分布式协作架构,多个拥有不同专长的智能体将能够动态组队、自主分工、协同作战,以应对大规模、分布式的复杂攻击。 -
• 攻防的螺旋式升级:随着防御方越来越多地采用AI,攻击方也必将利用AI来升级其攻击手段。这将引发一场围绕AI的、更高维度的军备竞赛。防御体系必须具备持续学习和快速进化的能力,才能在这场对抗中保持优势。 -
• AI治理与可信AI:随着AI在安全决策中的权重日益增加,建立健全的AI治理框架至关重要。行业需要制定相应的标准和法规,确保AI系统的决策过程透明、可审计、公平且可控,构建真正“可信赖的AI”。
参考文献
[1] Husain, S., & Dehghantanha, A. (2021). "AI-Driven Security Operations Centers: A Survey and a Vision for the Future." IEEE Access, 9, 87654-87671.
[2] Ferrag, M. A., & Maglaras, L. (2023). "Large Language Models in Cybersecurity: A Comprehensive Survey and Evaluation." arXiv preprint arXiv:2310.02214.
[3] Dettmers, T., et al. (2023). "QLoRA: Efficient Finetuning of Quantized LLMs." arXiv preprint arXiv:2305.14314.
[4] Greshake, K., et al. (2023). "Not what you've signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection." Proceedings of the ACM Workshop on Artificial Intelligence and Security.
[5] Park, J. S., et al. (2023). "Generative Agents: Interactive Simulacra of Human Behavior." Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology.
[6] Microsoft Security. (2024). "Introducing Security Copilot and the Rise of Agentic AI in Cybersecurity." Microsoft Security Blog.
[7] National Institute of Standards and Technology (NIST). (2023). "AI Risk Management Framework (AI RMF 1.0)." NIST AI 100-1.
相关文章
