o1模型的关键阶段
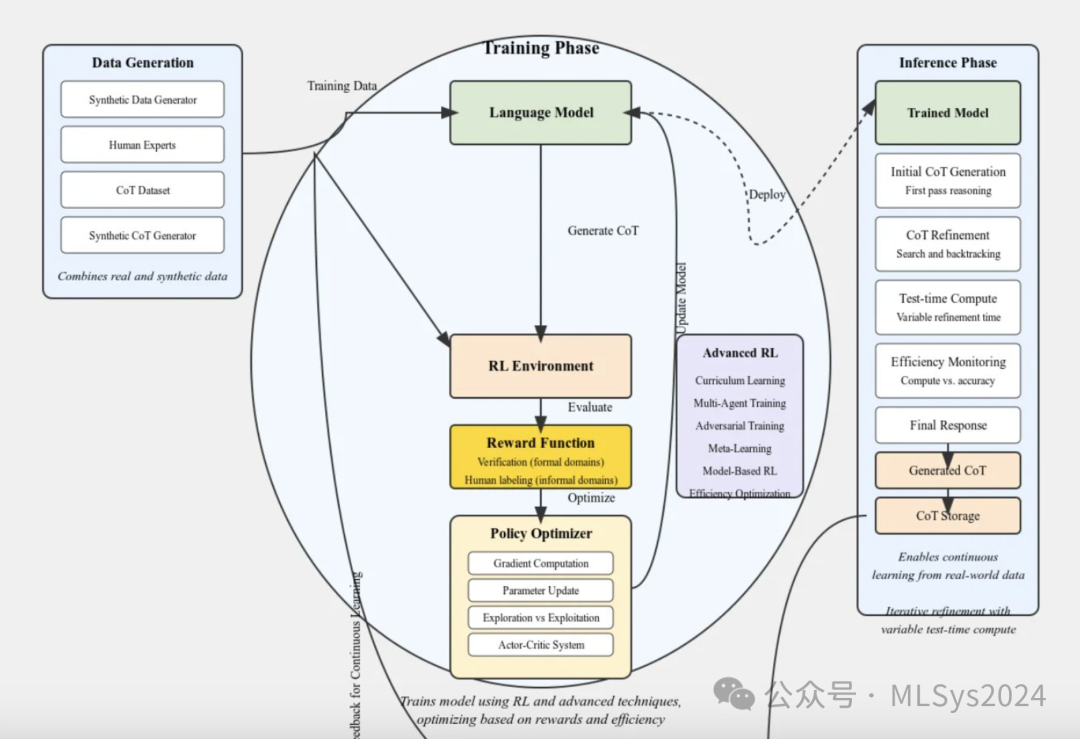
1. 数据生成
-
合成数据生成器:用于创建多种模型可能遇到的场景和环境。 -
人类专家:提供具有丰富细节和准确性的真实世界数据。 -
思维链(CoT)数据集:这是捕捉推理过程的重要组成部分,使模型能够发展强大的推理能力。 -
合成CoT生成器:生成额外的合成推理数据,确保数据集既包含真实世界的推理,也有合成生成的逻辑。
2. 训练阶段
-
语言模型:负责生成响应和推理,是训练中的核心组件。训练过程中,它生成思维链(CoT)输出,并通过反馈环进行评估和优化。 -
强化学习环境:评估模型的表现,并将结果反馈到训练过程中。这一部分融入了高级强化学习技术。 -
奖励函数:奖励函数在优化过程中至关重要,它基于形式验证(在结构化、正式领域)和人工标注(在非正式场景)来评估模型的输出。通过这些反馈回路进行优化,模型的表现不断提升。 -
策略优化器:负责梯度计算、参数更新以及探索与利用之间的平衡。这确保了模型不断调整其参数,在已知奖励优化和新可能性探索之间找到最佳平衡。
-
训练过程结合了诸如多智能体训练和对抗性训练等高级强化学习方法。这些方法通过促使模型考虑替代观点、竞争性想法和多种上下文,进一步优化模型。 -
技术如元学习和效率优化确保模型不仅学习得好,而且在计算成本和性能上也具有高效性和可扩展性。
-
初始CoT生成:模型接收到输入后进行第一次推理,生成思维链响应。 -
CoT优化:这是一个迭代的过程,模型通过搜索和回溯等技术优化其推理,以确保输出更准确和合理。 -
测试时计算:根据任务的复杂性,动态调整优化时间。一些查询可能需要更深入的推理,而另一些则不需要。 -
效率监控:平衡计算成本与响应准确性,确保模型在保持效率的同时提供高质量输出。 -
生成的CoT和CoT存储:最终输出生成,并存储这些推理响应以备后续优化,从而使模型能够通过实际数据实现持续学习。
连续学习的反馈循环
结论
相关文章
最实用、最热门的AI 工具大全AI 工具导航,帮助你在工作与学习上更轻松有效率。在网路上众多 AI 与 ChatGPT 工具中,我们亲自试用并挑选了最有有用的,分成 20多个大类别,让你轻松找到所需的 AI 工具。
