解密AI黑箱:深入Anthropic开源电路追踪工具,看见语言模型的“思考”过程
图片来源:Anthropic
作为AI爱好者,我们总是对那些驱动着大型语言模型(LLM)的神秘力量充满好奇。它们如何写出诗歌?如何进行推理?当我们在屏幕上看到一个完美的答案时,其背后庞大的神经网络中究竟发生了什么?长期以来,这就像一个密不透风的“黑箱”。
然而,就在2025年5月29日,AI安全和研究领域的领军者Anthropic,联合Decode Research与Neuronpedia,投下了一颗重磅炸弹:他们开源了其内部的“电路追踪”(Circuit Tracing)工具。这不仅仅是又一个开源项目,它更像是一把递到我们手中的钥匙,让我们有机会亲自打开那个黑箱,一窥LLM“思维”的究竟。
Anthropic的CEO Dario Amodei曾警示:“我们对AI内部运作的理解,远远落后于其能力的发展。” 这个开源工具,正是为了缩小这一差距而迈出的关键一步。今天,让我们深入这份详尽的技术材料,看看它到底为我们揭示了什么。
核心利器:归因图(Attribution Graphs)与“超级节点”(Supernodes)
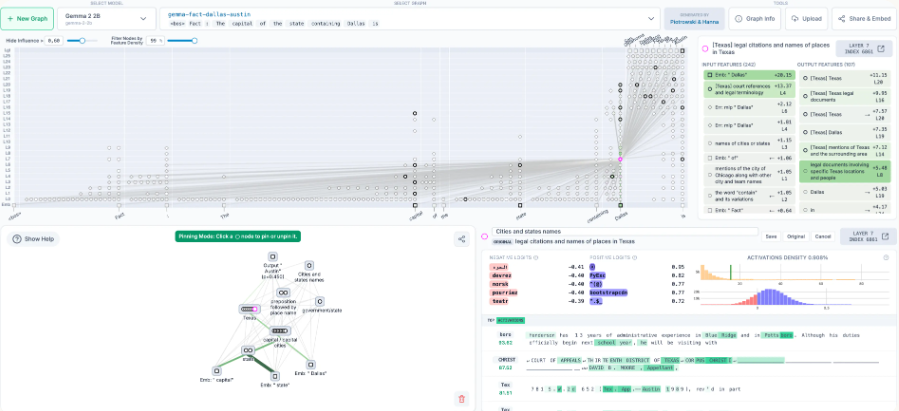
想象一下,要理解一个复杂的电子设备,最好的方式就是拿出一张电路图,看看电流如何从输入流向输出,途经哪些元器件。Anthropic的工具做的就是类似的事情,但对象是神经网络。
它生成一种名为**归因图(Attribution Graph)**的可视化图表,揭示了模型为了生成特定输出,其内部信息流动的因果路径。图中的每一个节点,都可能是一个或多个神经元。
但面对数以亿计的神经元,直接分析无异于大海捞针。这里的点睛之笔,是引入了**“超级节点”(Supernodes)**的概念。研究人员通过分析,将成百上千个功能相似的神经元“打包”成一个具有明确语义概念的超级节点。例如,一个超级节点可能代表了“德克萨斯州”这个地理概念,另一个则代表了“说出一个首都城市”的指令。
这使得原本混乱的神经元激活图,变成了一张清晰、可被人类理解的“思维导图”。而这次开源的真正魅力在于,它不仅让我们能“看”到这张图,更能通过代码**直接干预(Intervene)**这些节点,像做科学实验一样验证我们的假设。
实战演练一:当模型进行“两步推理”
让我们来看一个经典案例,这也是Anthropic在教程中展示的第一个例子。
提问: Fact: The capital of the state containing Dallas is (包含达拉斯的州的首都是)
模型回答: Austin (奥斯汀)
这是一个简单的两步推理题:
-
1. 达拉斯(Dallas)在哪个州? -> 德克萨斯州(Texas)。 -
2. 德克萨斯州的首都是哪里? -> 奥斯汀(Austin)。
归因图清晰地展示了这个过程:
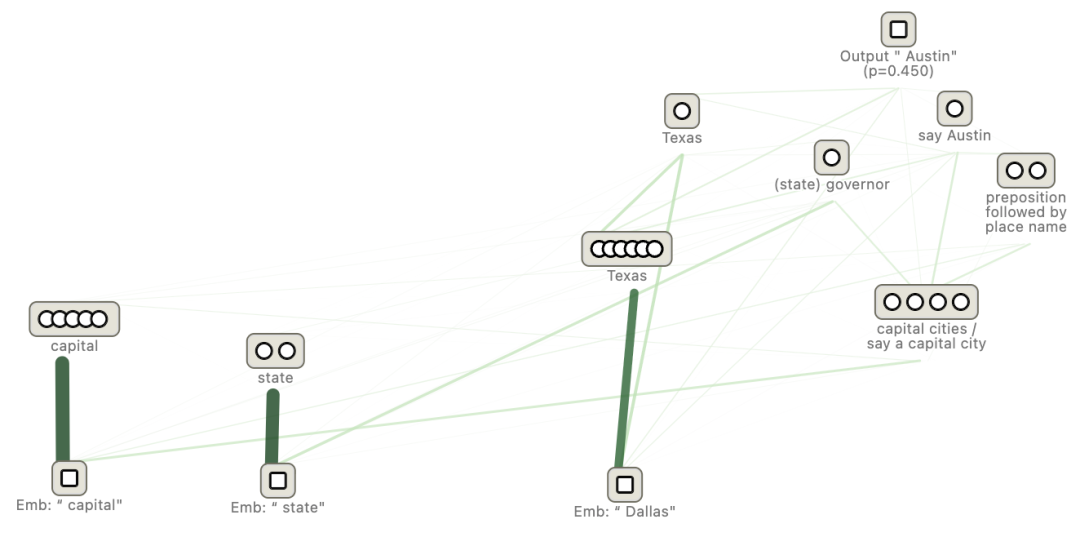
从图中我们可以看到,输入中的“Dallas”激活了一个代表“Texas”的超级节点,同时“capital”(首都)和“state”(州)这两个词也激活了相应的概念节点。这些信息最终汇集,共同激活了输出“Austin”的神经元。
真正的魔法发生在干预实验中:
-
1. 关闭“首都”概念:研究人员通过代码,强行抑制了图中代表“说出一个首都”的超级节点。结果如何?模型的输出不再是“Austin”,而变成了“Texas”!这证明了模型确实先“想”到了德州,只是因为“回答首都”的指令被屏蔽了,才把中间步骤吐了出来。 -
2. 关闭“德州”概念:当我们关闭“Texas”这个超级节点时,“Say Austin”节点也随之关闭。模型变得困惑,开始输出其他州的首府,比如萨克拉门托(加州首府)。 -
3. “思维”劫持——最令人惊叹的实验:
-
• 研究人员在保持原提问不变的情况下,关闭了“Texas”节点。 -
• 同时,他们从另一个提问(“...containing Oakland is...”)中提取了代表**“California”(加利福尼亚州)**概念的超级节点的激活值,并将其“注入”到当前模型中。 -
• 结果,模型的输出神奇地变成了“Sacramento”(萨克拉门托)——加州的首府! -
• 他们甚至更进一步,注入了**“China”(中国)的概念,模型的输出随之变为“Beijing”(北京)**。
这个实验雄辩地证明了:这些“概念”在模型内部是模块化、可插拔的!模型并非死记硬背,而是真的在学习和运用这些抽象概念,并遵循着一套可被我们理解和操纵的逻辑链路。
实战演练二:跨越语言的共享“大脑”
另一个引人深思的案例是多语言处理。
提问(三语):
-
• 英语: The opposite of "small" is "->big -
• 法语: Le contraire de "petit" est "->grand -
• 中文: "小"的反义词是"->大
模型是如何做到这一点的?它为每种语言都学习了一套独立的“反义词”电路吗?
归因图揭示了更深层的秘密:
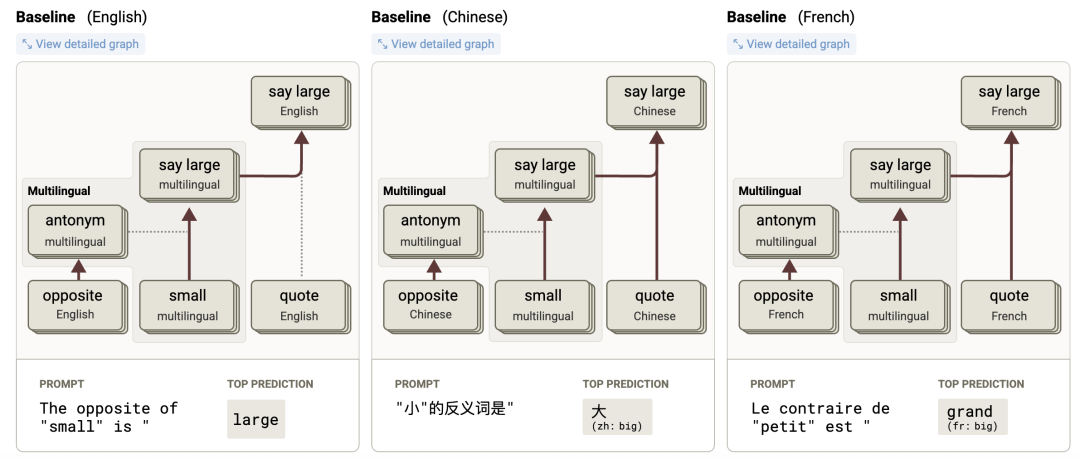
模型内部存在一个语言无关的、共享的核心电路。这个电路理解了“small”和“opposite”这两个抽象概念,并得出了一个同样抽象的“big/large”概念。
然后,存在一些特定于语言的“开关”节点。
-
• 当输入是法语时,一个“French”超级节点会被激活,它会将抽象的“big”概念“翻译”成法语中的“grand”。 -
• 当输入是中文时,一个“Chinese”节点则负责将其引导至“大”。
干预实验再次证实了这一点:
-
• 在处理法语提问时,如果研究人员强行关闭“French”节点,模型的输出立刻从“grand”变回了英语的“big”! -
• 更绝的是,在处理法语提问时,关闭“French”节点,同时注入“Chinese”节点的激活值,模型的输出直接变成了中文的“大”!
这表明,至少在这个任务上,Gemma模型的核心逻辑是跨语言共享的,只是在最后输出时由特定语言的“模块”进行调整。这为我们理解AI如何形成跨文化、跨语言的通用表征提供了宝贵的线索。
不只是成功:局限性与未来的方向
当然,电路追踪并非万能灵药。在教程的最后,研究人员也展示了一个不那么成功的干预案例(将“反义词”替换为“同义词”),其效果并不理想。这提醒我们,AI的内部世界依然错综复杂,并非所有概念都能被干净利落地解构。
但无论如何,Anthropic的这次开源都是AI可解释性研究领域的一座灯塔。它为我们提供了:
-
1. 一个可视化的界面 (Neuronpedia),让更多人能直观探索模型。 -
2. 一个强大的代码库,让研究者可以进行严谨的因果干预实验。 -
3. 一套可复现的案例,展示了从多步推理到多语言表征等惊人发现。 -
4. 一个开放的平台,邀请全球的AI爱好者和研究者共同参与,去发现和标注更多未知的电路。
从“炼丹”到“工程”,这或许是对此次开源意义的最好概括。当我们能像工程师分析电路图一样分析AI模型时,我们距离构建更安全、更可靠、更可控的通用人工智能就更近了一步。AI的“黑箱”正在被撬开一条缝,而从这条缝里透出的光,足以照亮整个行业的未来。
附上开源地址:https://github.com/safety-research/circuit-tracer
相关文章
