苦活累活才是AI Agent护城河-来自最近工作的感叹。
解决大模型在真实业务中胡编乱造的最好的方法就是使用高质量的上下文,而高质量的上下文就是一个苦活累活。上个月成功出圈的夸克填报志愿Agent就是一个典型的例子:

大模型为何会失灵?
一个未经外部信息增强的LLM,其知识和行为完全依赖于其训练数据,就会存在如下三个根本性的缺陷,进而导致了大模型的不可靠:
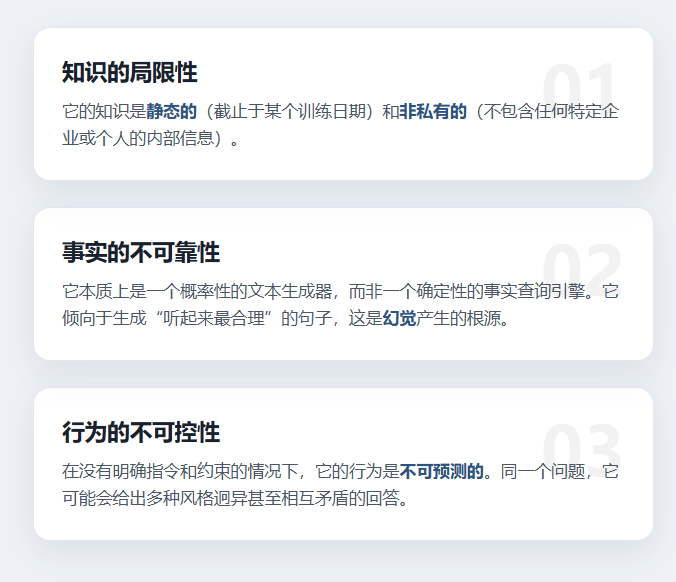
将一个未经优化和引入外部信息的大模型直接应用于严肃的业务场景,失败是必然的,即使换成是人,也依然如此。
什么是上下文工程?
上下文工程,就是为解决上述问题而生的一整套系统性方法。其定义是:
在用户与大模型交互的每一个环节,通过一系列精细化的技术和策略,为大模型动态构建一个最准确、最相关、最完整的信息环境(即上下文),从而引导、约束并增强其行为,使其能够生成可信、可控且有价值的输出。
这个信息环境并非单一的概念,而是由多个维度构成的立体结构。一个成熟的上下文工程体系,至少需要管理以下七个核心维度的信息:

上下文工程的“苦活累活”在哪里?
理解了“为什么”和“是什么”之后,我们需要深入“怎么做”。
1. 知识层:构建高质量的外部检索信息
这是整个体系的基石,也是最耗时的一环。其目标是将原始、混乱的数据,转化为AI可以信赖的知识资产。
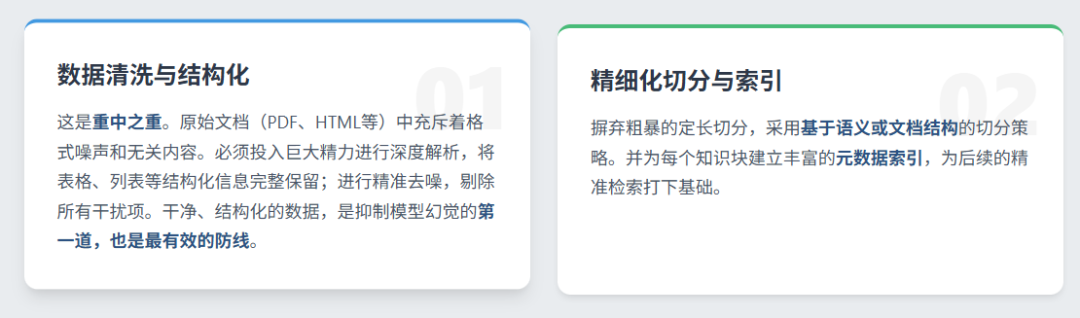
2. 检索层:从海量知识中精准取水
拥有高质量的知识库后,下一步是如何根据用户问题,精准地找到所需信息。

其实这个步骤就是来源于传统的搜索引擎的思路,从查询理解、检索、排名到结果呈现,几乎一致,只是细节不太相似。
3. 编排层:动态组织上下文
将所有信息维度整合起来。
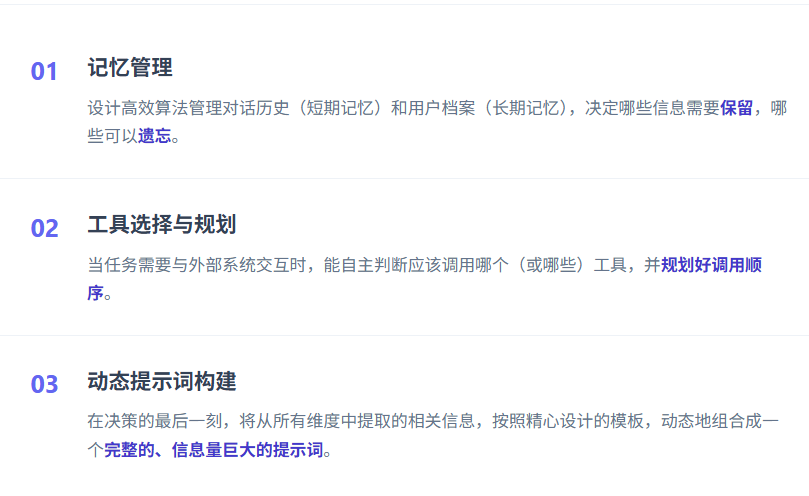
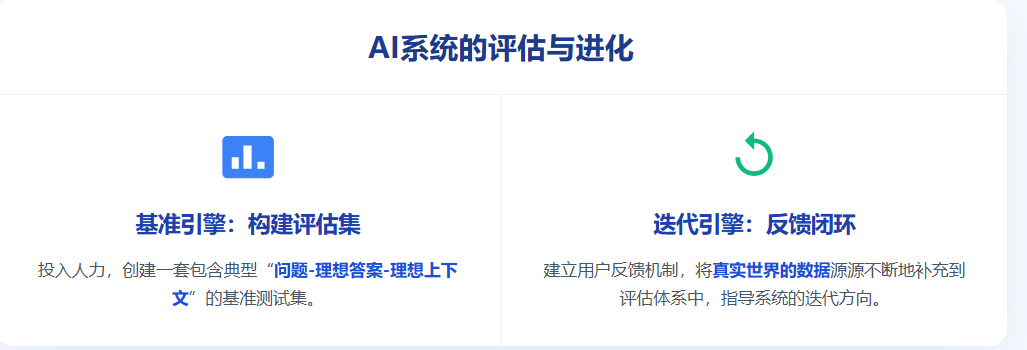
4. 评估与迭代层:没有度量,就没有优化
这个我觉得最有用的是两个:
结论:护城河并非模型,而是围绕模型的系统工程
通过以上的梳理,我们可以得出一个清晰的结论:
一个真正强大、可靠的AI应用,其核心竞争力并不在于它使用了哪个版本的LLM(因为各个大厂大模型的能力在拉齐,且调用API的价格在飞速下降),在于你围绕模型所构建的这套复杂的、精密的、且与你的业务数据和流程深度绑定的上下文工程体系。
相关文章
