很值得仔细琢磨的一篇论文,58页,作者主要来自oppo,oppo最近还发了好几篇Agent的论文,都挺不错的~
这个工作讲的是如何沉淀Agent过去的执行经验,让Agent性能越来越好。
-
论文:https://arxiv.org/pdf/2507.06229 -
代码:https://github.com/OPPO-PersonalAI/Agent-KB
先看结果,提升很大。 分别在GAIA、SWE 上验证了。
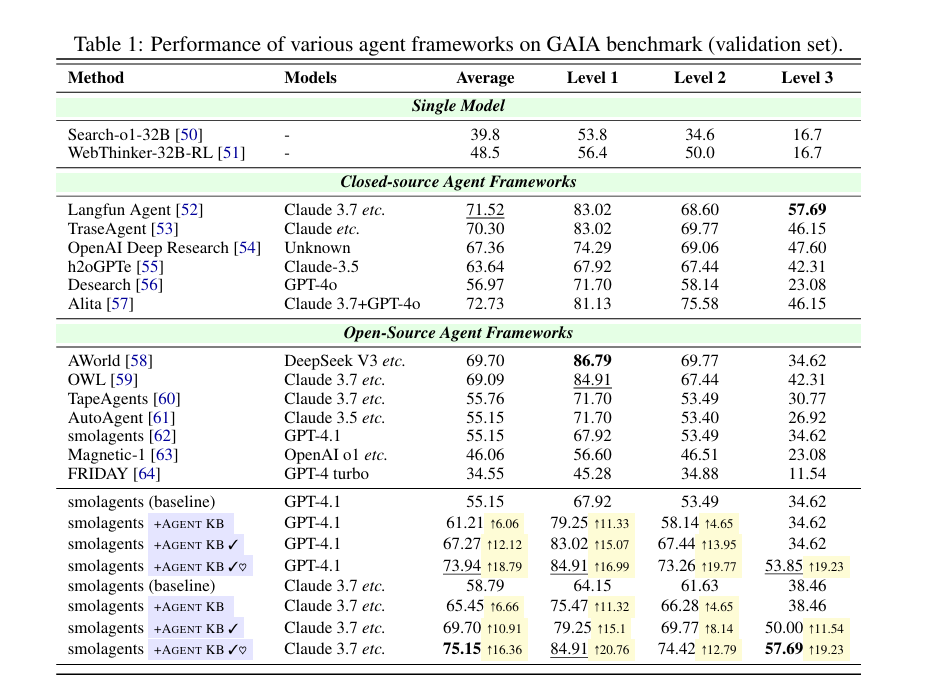
内容蛮简单,但是细节很多。
沉淀Agent过去的执行经验。 那首先得有个经验库把,经验库怎么构造,怎么召回。
有了经验库,他们又折腾了一个Multi-Agent的系统。然后每个Agent里边又有一个Reason-Retrieve-Refine的流程。
对应到下左图,构建经验库,右图如何解决问题。
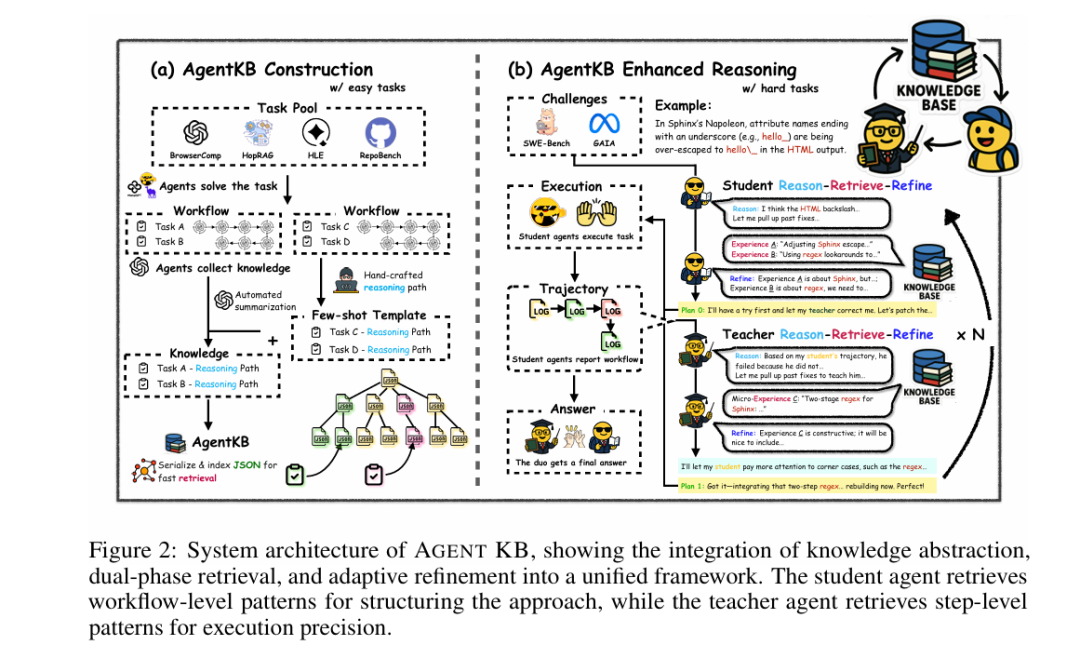
他们避开了Multi-Agent这个词,用teacher 、 student 代替了。 teacher Agent、Student Agent 分别什么意思呢? 就类似于学生写作业,老师评改作业,改完学生在修正这么个步骤。

Reason-Retrieve-Refine 这3个词就是字面意思。
虽然又是teacher Agent又是Student Agent,然后还 Reason-Retrieve-Refine 。但是其实挺workflow的(测试了很多,实验出这么个pipeline)。 原文有个消融实验,证明了每个部分都有必要。
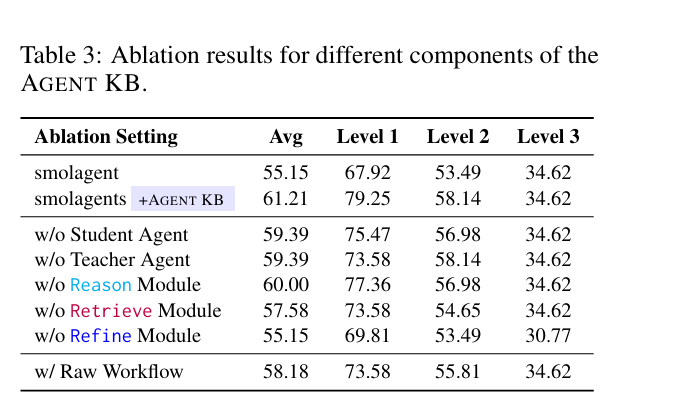
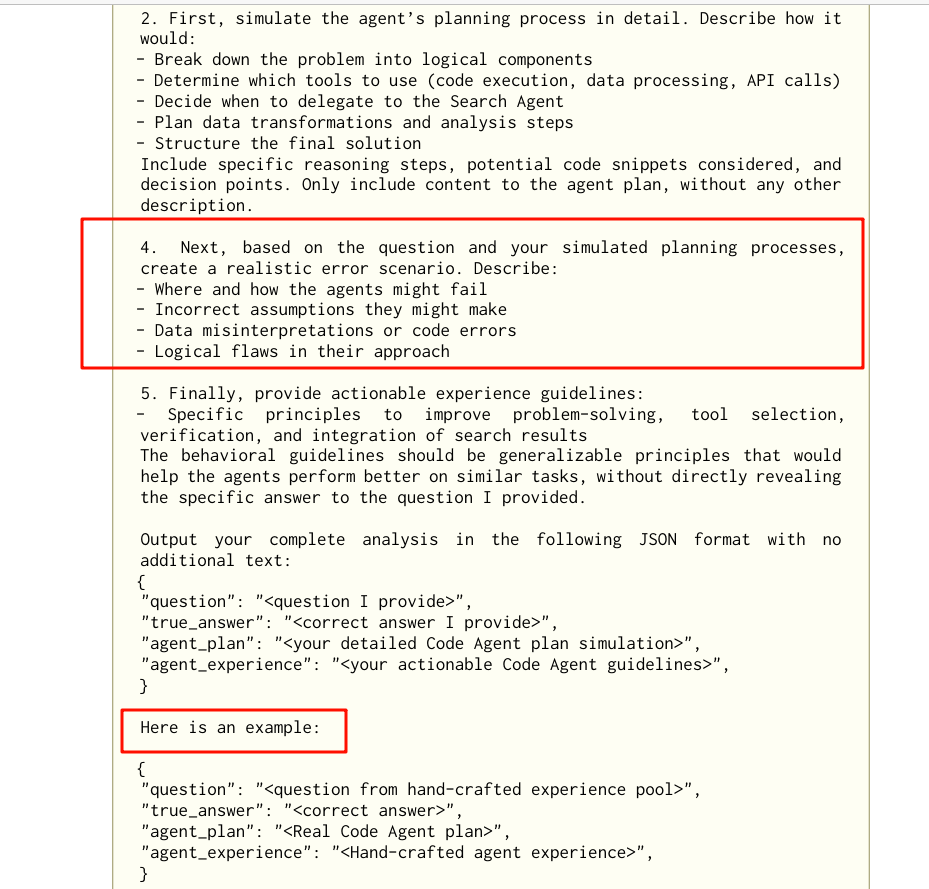
那到底要怎么去沉淀经验库呢?论文附录有很长的一节讲这个东西。

构造过程是一个结合了人工经验和自动化生成的流程:
第一阶段:人工制作高质量的“种子经验”
-
团队组建: 招募了三名熟悉GAIA基准和Agentic工作流的计算机专业的学生 。
-
日志分析: 他们审查了Agent在GAIA任务中成功和失败的日志,总结出高效的、符合逻辑的行动序列和通用模式 。
-
编写范例: 将这些成功的策略和对失败的反思,手动编写成高质量、标准化的自然语言指令式提示(Prompt) 。
-
测试和筛选: 通过测试,最终筛选出表现最好的80个手写经验作为种子。
第二阶段:利用“种子经验”进行自动化扩展
-
Few-shot 学习: 使用第一阶段产出的高质量“种子经验”作为范例(Few-shot Examples),去提示大语言模型 。
-
批量生成: 让大模型为来自多个不同数据集的大量新任务,自动生成格式统一的经验条目 。
数据来源:
为GAIA构造的经验库,经验来源于四个数据集:BrowseComp、HopRAG、HLE (text-based subset) 和 WebWalkerQA 。
为SWE-bench构造的知识库,经验则来源于三个数据集:RepoClassBench、SWE-Gym-Raw 和 RepoEval 。
经验库格式长什么样子? 论文有个例子,翻译了一下,放在下边。
{
"question": "有一个获得多项格莱美奖的知名人物……",
"true_answer": "St. John’s Health Center(圣约翰健康中心)",
"agent_planning": "1. 解析问题,提取所有关键约束条件:获得多项格莱美奖,第一张专辑发行于1969年之前,有药物依赖问题,20岁前被学校开除,第一位人生伴侣于1997年去世,曾作为军装人员服役,确定死亡地点/医院。n2. 概念性规划:n- 确定所有符合以上条件的艺人候选人。n- 对每位候选人:n a) 验证首张专辑发行时间(1969年之前)n b) 检查格莱美获奖历史n c) 检索传记资料,确认药物依赖与教育背景n d) 确认伴侣去世年份和军装服役信息n e) 锁定匹配人物的死亡日期和具体地点/医院。",
"search_agent_planning": "1. 从代码代理处获得精确的人物身份,或利用传记线索进行三角定位。n2. 制定搜索查询,确认人物身份及其具体去世医院。n3. 优先查找官方传记、权威新闻媒体、格莱美官方记录。n4. 交叉核查关键信息点,确保人物匹配。n5. 从讣告中提取死亡地点和医院信息。",
"agent_experience": [
"将复杂多条件问题拆分为小型约束检查",
"明确记录并多渠道验证传记约束条件",
"优先选用高可靠性传记和奖项数据来源",
"在早期将具体子查询委托给搜索代理",
"通过依次回链所有事实,最终验证答案"
],
"search_agent_experience": [
"将复杂查询分解为连续的搜索细化步骤",
"为模糊身份设计高度具体的检索关键词",
"优先使用权威信息源而非娱乐/八卦内容",
"从多方独立来源交叉验证信息",
"直接引用和明确来源,规范化结果格式"
]
}
相关文章
