0 引言
大语言模型(LLMs)的迅猛发展彻底革新了人工智能领域,极大地拓展了机器对语言的理解与生成能力。然而,将这些复杂模型部署并管理于生产环境中,面临着诸多传统机器学习运维(MLOps)方法难以全面应对的独特挑战,由此催生了专门的学科领域——LLMOps。
1 LLMOps的“缘起”:一种专业化的应对之道
尽管MLOps为机器学习模型的全生命周期管理提供了坚实框架,但大语言模型所具有的独特复杂性,使其亟需一种量身定制的解决方案。正如谷歌云所指出的,LLMOps是MLOps的一个“专业子集……专注于管理大语言模型的挑战和需求”。这些根本差异主要体现在:
- 数据量与多样性
大语言模型的训练依赖于海量且极具多样性的数据集,其规模远远超出了典型机器学习模型。这就需要专门的数据策划和准备流程。 - 计算资源
大语言模型的训练与推理过程计算密集度极高,需要大量的GPU资源以及优化后的基础设施支持。 - 评估指标
传统的准确率或精确率等评估指标,对于生成式模型来说远远不够。大语言模型需要对事实准确性、连贯性、创造性、安全性以及偏见等多方面进行细致评估。 - 部署考量
诸如提示工程、管理上下文窗口以及高效部署大型模型等独特方面,为部署环节增添了复杂性。
LLMOps正是填补了这一空白,提供了确保大语言模型在生产环境中得以有效、合乎伦理地开发、部署、监控和维护的方法论、工具以及最佳实践。
2 LLMOps生命周期剖析
精通LLMOps需要驾驭一个全面的生命周期,每个阶段都有其独特的考量因素:
1. 大语言模型的数据策划与准备。任何强大的大语言模型,其根基都在于数据。对于大语言模型而言,这包括为预训练、微调以及提示工程准备庞大且多样化的数据集。这一阶段对于确保模型质量以及减少偏见至关重要。最佳实践包括使用高质量、干净且相关性强的数据,并且实施稳健的数据治理政策。伦理考量,例如识别并减轻训练数据中存在的有害偏见,是至关重要的。
2. 模型微调与适应。预训练的大语言模型虽然功能强大,但往往需要针对特定的下游任务或领域进行微调。像低秩适应(LoRA)以及量化低秩适应(QLoRA)这类参数高效微调(PEFT)家族中的技术,能够在显著减少计算资源和数据的情况下,对超大型模型进行适应性调整。有效的LLMOps要求对微调后的模型进行细致的版本管理,并且全面跟踪实验过程,以确保可复现性以及性能对比。
3. 提示工程与管理。提示工程是精心构思有效输入(提示),以引导大语言模型朝着期望输出方向发展的艺术与科学。这涉及理解模型的能力与局限性,尝试不同的措辞,并且提供充足的上下文信息。在生产环境中,管理提示变得至关重要。这包括对提示进行版本管理,对不同提示变体进行A/B测试以优化性能,以及建立清晰的提示创作指南。
4. 大语言模型的部署策略。部署大语言模型的范围可以从利用云供应商提供的基于API的服务(例如谷歌云的Vertex AI)到搭建本地推理解决方案。关键考量因素包括可扩展性,以应对不同用户负载;对于实时应用,最小化延迟;以及优化计算成本。正如Matoffo所讨论的,组织在选择部署工具时,应考虑基础设施兼容性、现有技术栈以及安全需求等因素。
5. 大语言模型的监控与可观测性。部署后,持续监控对于确保大语言模型按预期运行至关重要。除了典型的机器学习模型监控(输入/输出跟踪、延迟、资源利用)之外,大语言模型还需要特别关注以下方面:
- 模型漂移
检测因输入数据分布变化或现实世界动态变化而导致模型性能下降的情况。 - 事实准确性与连贯性
确保生成的文本在事实和逻辑上都是正确的。 - 安全性和偏见
监控是否生成有害、偏见或不当内容。 - Token使用量
跟踪Token消耗情况,以便进行成本管理。
实施实时监控系统并定期分析监控数据是LLMOps的最佳实践,有助于及时发现并解决问题,正如谷歌云所概述的那样。
6. 持续改进与反馈循环。大语言模型并非一成不变。建立来自最终用户、领域专家以及自动化评估系统的强大反馈机制对于持续改进至关重要。这些反馈信息为模型重新训练、微调、提示优化以及数据策划工作提供依据,确保大语言模型始终保持相关性并且在长期内保持最佳性能。
3 LLMOps的关键工具与生态系统
LLMOps生态系统正在迅速扩展,专门针对大语言模型独特需求的工具不断涌现。
- 实验跟踪
像MLflow、Weights & Biases以及Comet ML这类工具对于记录大语言模型实验至关重要,包括不同的微调运行、提示变体以及评估指标。 - 向量数据库
在检索增强生成(RAG)架构中,这些数据库发挥着关键作用,使大语言模型能够访问并整合外部、最新的信息,从而减少幻觉现象,提高事实准确性。 - 编排与部署
像Kubeflow、Ray以及BentoML这类平台有助于编排复杂的大语言模型工作流程,并且提供强大的服务功能。像FastAPI这类框架通常用于构建高效的大语言模型推理端点。 - 提示管理平台
正在出现专门的工具来帮助对提示进行版本管理、测试以及部署,简化提示工程的生命周期。 - 评估框架
无论是自动化评估框架还是人工参与的评估框架,对于根据各种标准(包括质量、安全性和偏见)评估大语言模型输出都至关重要。
4 代码示例
4.1 使用Hugging Face Transformers和PEFT微调预训练大语言模型(概念性示例)
虽然完整的微调示例较为复杂,但核心思路是加载Hugging Face上的预训练模型和分词器,定义一个PEFT(例如LoRA)配置,然后在特定的数据集上进行训练。
# 使用Hugging Face和PEFT进行微调的概念性示例from transformers import AutoModelForCausalLM, AutoTokenizerfrom peft import LoraConfig, get_peft_model, TaskTypeimport torch# 1.加载预训练模型和分词器# model_name = "mistralai/Mistral-7B-v0.1"# tokenizer = AutoTokenizer.from_pretrained(model_name)# model = AutoModelForCausalLM.from_pretrained(model_name)# 2.定义PEFT(LoRA)配置# lora_config = LoraConfig(# r=8, # LoRA的秩# lora_alpha=16, # LoRA的缩放因子# target_modules=["q_proj", "v_proj"], # 目标模块# lora_dropout=0.05, # LoRA的dropout概率# bias="none", # 偏置项处理方式# task_type=TaskType.CAUSAL_LM # 任务类型# )# 3.获取PEFT模型# model = get_peft_model(model, lora_config)# model.print_trainable_parameters()# 4.准备数据集并训练模型(使用Trainer或自定义循环)# 这包括对数据进行分词处理、创建DataLoaders以及运行训练循环。
4.2 使用FastAPI搭建基础的大语言模型推理端点
此示例展示了如何使用流行的Python网络框架FastAPI创建一个简单的大语言模型推理API端点。
# 使用FastAPI进行基础大语言模型推理的示例from fastapi import FastAPIfrom pydantic import BaseModel# 这里是你的加载好的大语言模型# from transformers import pipeline# llm_pipeline = pipeline("text-generation", model="distilgpt2")app = FastAPI()class PromptRequest(BaseModel): prompt: str@app.post("/generate/")async def generate_text(request: PromptRequest): # 在实际场景中,你会在这里使用你的大语言模型 # response = llm_pipeline(request.prompt, max_length=50, num_return_sequences=1) # generated_text = response[0]['generated_text'] generated_text = f"大语言模型对 {request.prompt} 的回应" return {"generated_text": generated_text}# 运行此代码通常使用:uvicorn your_file_name:app --reload
4.3 实现一个简单的提示版本控制系统(概念性示例)
一个基础的提示版本控制系统可以涉及将提示以结构化格式(例如JSON、YAML)存储,并带有版本号和元数据,通过Git等版本控制系统进行管理。
# 简单提示版本控制示例(概念性)# prompts = {# "v1.0": {# "name": "summarization_v1",# "text": "Summarize the following text concisely: {text}",# "description": "Initial summarization prompt"# },# "v1.1": {# "name": "summarization_v1",# "text": "Provide a brief summary of the following document: {text}",# "description": "Improved summarization prompt for documents"# }# }# def get_prompt(version, name):# return prompts.get(version, {}).get(name)# current_prompt = get_prompt("v1.1", "summarization_v1")# print(current_prompt["text"])
4.4 使用日志库进行基础的大语言模型监控(概念性示例)
基础监控可以涉及将输入、输出、延迟以及可能的Token使用情况记录到一个集中的日志系统中。
# 使用日志库进行基础大语言模型监控的示例(概念性)import loggingimport timelogging.basicConfig(level=logging.INFO, format='%(asctime)s * %(levelname)s * %(message)s')def log_llm_interaction(prompt, generated_text, latency, tokens_used): logging.info(f"大语言模型交互:Prompt='{prompt}', Response='{generated_text}', Latency={latency:.2f}s, Tokens={tokens_used}")# 模拟一次大语言模型调用# start_time = time.time()# simulated_response = "This is a simulated LLM response."# end_time = time.time()# log_llm_interaction("Tell me about LLMOps.", simulated_response, end_time * start_time, 15)
5 企业落地LLMOps的挑战与解决方案
5.1 LLMOps落地挑战
企业在落地LLMOps时主要面临以下挑战:
1)基础设施与资源挑战
- 巨额计算成本
训练千亿级参数的LLM需分布式GPU集群支撑,单次预训练成本可达数百万美元;推理阶段需持续优化Token消耗与动态批处理以降低成本。解决方案: -
分布式推理调度:采用vLLM引擎实现PagedAttention技术,GPU利用率提升80%,单卡支持千级并发。 -
混合云弹性架构:高频任务本地部署7B量化模型(如LLaMA-2-7B-INT4),复杂场景调用云端13B+模型,API成本显著降低。 - 异构环境适配
混合部署场景(云API+本地推理)要求兼容不同硬件架构(如GPU/TPU),并解决容器化模型的跨平台移植问题。解决方案: -
容器化标准:基于NVIDIA Triton统一推理服务框架,支持GPU/TPU异构硬件自动调度。 -
跨平台移植层:通过ONNX Runtime实现模型格式标准化,消除环境依赖差异。
2)技术栈成熟度挑战
- 工具链碎片化
关键环节工具尚未统一,微调框架(Hugging Face PEFT)、部署引擎(TensorRT-LLM)、监控平台(Weights & Biases)分属不同生态,集成复杂度高。 - 解决方案:构建API网关统一管理工具链,可部分减少集成的复杂度。
- 评估体系缺失
传统指标(如准确率)不适用生成任务,需构建覆盖事实性(Factuality)、毒性(Toxicity)、逻辑连贯性的多维评估矩阵,且缺乏标准化测试集。解决方案: -
多维度指标库:融合FactScore(事实性)、ToxiGen(毒性)、BERTScore(连贯性)构建三位一体评估矩阵。 -
领域测试集:金融/医疗行业建立专属测试用例(如MedMCQA医疗问答集)。 - 提示工程工业化
提示版本管理、A/B测试工具尚未形成企业级解决方案,人工调试效率低下。解决方案: -
版本控制:Git-LFS管理提示模板版本,支持diff比对与回滚。 -
A/B测试平台:动态分流用户请求,自动统计不同提示的转化率/满意度。
3)数据与合规风险
- 数据治理瓶颈
TB级训练数据的去偏见清洗与合规审核依赖大量人工,自动化工具对多语言、多领域语料的处理能力不足。解决方案:(自动化治理流水线) -
偏见清洗:集成Hugging Face的BiasBench工具链,自动检测107类社会偏见。 -
合规审核:规则引擎(正则+敏感词库)+AI审核(微调RoBERTa分类器)双重过滤。 - 实时监控盲区
生成内容的安全审计需嵌入实时检测模块(如敏感词过滤、事实核查),但动态语义理解仍存在误判风险。解决方案:(实时监控增强) -
动态语义审计:Bonree ONE平台嵌入DeepSeek大模型,实时解析生成文本潜在风险。 -
双校验机制:RAG知识库比对确保事实准确性,敏感词扫描拦截率>99.97%。 - 隐私保护困境
差分隐私、联邦学习等技术与LLM训练的结合尚不成熟,易引发用户数据泄露争议。解决方案:(隐私保护技术) -
联邦微调:采用LoRA在客户端本地更新适配层,原始数据不出域。 -
差分隐私:训练过程注入可控噪声(ε=3~8),平衡效果与隐私强度。
4)组织协同障碍
- 技能断层
传统ML团队缺乏提示工程、RAG系统优化等LLM专属技能,需重新组建跨语言模型专家、伦理学家、运维工程师的复合团队。 - 流程再造阻力
MLOps流程无法直接复用:实验跟踪需增加提示变体管理,CI/CD需支持百GB级模型版本的回滚。解决方案:(LLMOps专用流水线) -
实验管理:Weights & Biases跟踪微调参数+提示变体组合。 -
模型版本控制:DVC管理百GB级模型文件,支持秒级回滚。 -
CI/CD扩展:Jenkins插件支持多节点推理服务灰度发布。
5)大语言模型本身也存在问题
- 幻觉现象
大语言模型可能会生成错误或荒谬的信息。 - 解决方案:实施检索增强生成(RAG)架构、强大的评估框架(包括人工参与和自动化的评估)以及使用事实性数据集进行微调。
- 偏见问题
:大语言模型可能会延续并放大其训练数据中存在的偏见。 - 解决方案
:在数据策划过程中采用偏见检测技术,在微调时使用去偏策略,并且实施伦理AI准则进行监控。 - 成本管理
大语言模型的计算费用可能会相当可观。 - 解决方案:优化模型大小(例如使用更小、更专业的模型)、利用PEFT技术、实施高效的模型服务基础设施以及监控Token使用情况。
- 数据隐私
使用大语言模型处理敏感用户数据时,需要严格遵守隐私法规。 - 解决方案:采用匿名化、差分隐私以及整个LLMOps流程中的安全数据处理实践。
企业破局需分阶段实施:短期优先构建成本可控的推理管线(如量化压缩+API网关),中期建立领域专属评估基准与提示工厂,长期推动跨平台LLMOps框架标准化。
6 企业LLMOps落地实施步骤框架
第一阶段:架构设计与资源准备
1)混合架构搭建
-
本地化部署7B参数量级基础模型处理高频敏感任务,云端部署13B+模型应对复杂场景,实现成本与性能平衡(API调用成本可降低42%)。 -
向量数据库(如Chroma/Pinecone)构建企业知识库,提升语义检索准确率至93%以上。
2)硬件配置标准
-
GPU集群支持分布式训练(推荐NVIDIA Tesla系列) -
内存≥32GB,SSD存储≥500GB,满足模型加载需求
3)安全防护层级
-
API网关流量控制+敏感词过滤+操作日志审计三重防护(违规输出拦截率>99.97%)
第二阶段:开发与调优
1)三层环境隔离

通过云平台密钥管理服务(如AWS Secrets Manager)注入生产环境敏感数据。
2)提示工程工业化
-
结构化提示模板管理:定义system_prompt/few_shot/constraints字段 -
动态变量注入用户画像与会话历史(客服场景转化率提升22%)
3)参数高效微调
-
采用LoRA/QLoRA技术,仅增加0.1%参数量达85%全参微调效果。 -
法律/医疗领域微调后F1值提升40%以上。
第三阶段:部署与监控
1)推理优化策略
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
2)监控矩阵构建
-
事实准确性:RAG验证模块实时比对知识库 -
成本控制:Token消耗追踪与动态批处理 -
安全审计:多维度扫描偏见/毒性内容
第四阶段:持续迭代
1)反馈驱动机制
-
用户侧:埋点收集拒绝率/满意度数据 -
系统侧:自动化评估生成质量(连贯性/事实性评分)
2)增量更新流程
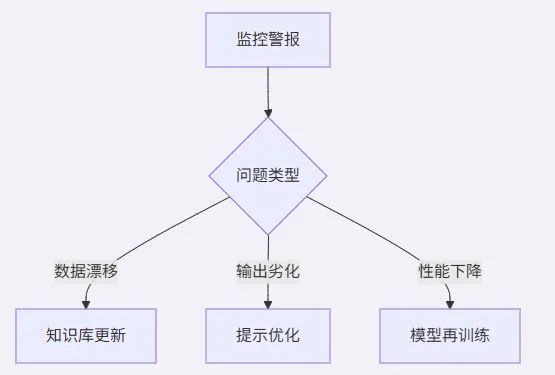
采用金丝雀发布策略控制版本风险。
实施周期参考:概念验证阶段2~4周 → 最小可行产品8~12周 → 全系统落地6~9个月。一些强监管领域需增加合规性验证环节,耗时延长30%。
7 未来展望
LLMOps的格局在持续演变,新兴趋势包括更高的自动化程度以及AI驱动运维的整合。我们可以预见:
- 多模态模型的兴起
LLMOps将扩展到管理能够处理和生成文本、图像、音频等多种模态的模型。 - 边缘大语言模型
在边缘设备上部署更小、更优化的大语言模型,用于低延迟、保护隐私的应用。 - 融入复杂AI系统
大语言模型将成为更大、更复杂AI系统的重要组成部分,这要求实现无缝整合和编排。
随着大语言模型的广泛应用,对于MLOps从业者以及希望在生产环境中充分利用这些变革性模型的组织来说,掌握LLMOps将成为不可或缺的技能。
相关文章
