GRPO 的数学原理其实就像一套高效的评分系统,它帮助 DeepSeek 模型在一组回答中迅速找到最佳答案。通过比较每个回答与其他回答的优劣,模型能清楚地知道哪些回答更准确、更符合要求,从而不断调整和优化自己的策略。
这样一来,就不需要额外的评估器,既节省了计算资源,又能在实际应用中不断提高推理能力。
一、GRPO 的基础
1. 什么是 GRPO?
Group Relative Policy Optimization(GRPO) 是一种专为提升大语言模型推理能力设计的强化学习(RL)算法。与传统方法不同,GRPO 不依赖外部评估器(critic)来指导学习,而是通过对比一组回答之间的相对优劣来优化模型。这种相对评估机制不仅简化了训练过程,还大幅提高了效率,特别适用于需要复杂问题求解和长推理链的任务。
2. 为什么需要 GRPO?
传统强化学习方法(如 Proximal Policy Optimization(PPO))在大语言模型推理任务中存在以下挑战:
依赖 Critic 模型
-
• PPO 需要一个额外的 critic 模型来估算每个回答的价值,这会使内存和计算成本翻倍。 -
• Critic 模型的训练过程复杂,容易出错,尤其是在涉及主观或细微评估的任务中。
高计算成本
-
• RL 训练通常需要大量计算资源来不断评估和优化模型的输出。 -
• 在大规模 LLM 上应用这些方法会进一步加剧计算成本。
可扩展性问题
-
• 绝对奖励评估在处理多样化任务时存在困难,导致泛化能力受限,难以适用于不同的推理场景。
GRPO 如何应对这些挑战?
-
1. 无需 Critic,降低成本 GRPO 通过组内回答比较消除了对独立评估器的依赖,从而大幅降低了计算资源的需求。 -
2. 相对评估机制 它通过对比同一组回答的表现来衡量质量,而非单独打绝对分,这使得模型能够更直观地识别哪些回答更优。 -
3. 高效训练,易于扩展 聚焦于组内优势的计算,使得奖励估计过程更简单,进而使训练过程既高效又便于扩展到大规模模型上。 -

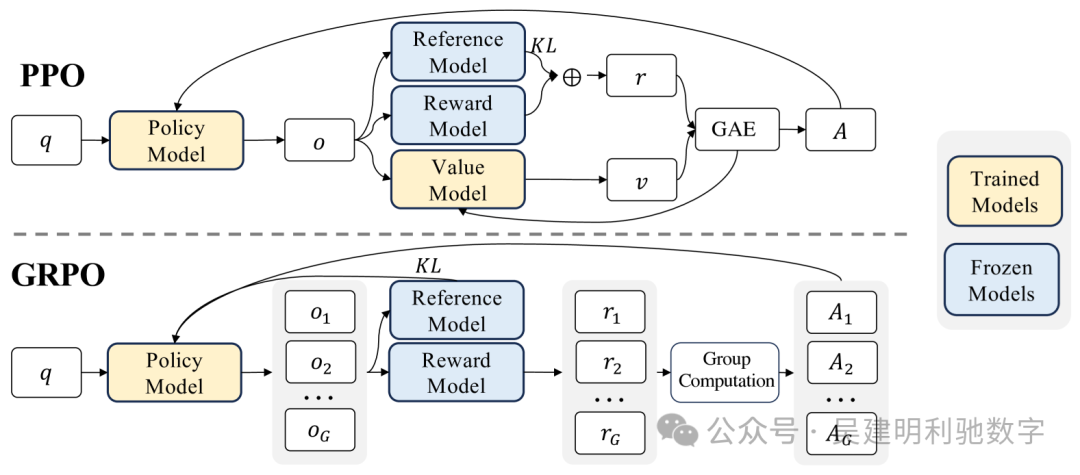
二、GRPO 的核心理念——相对评估
GRPO 的核心思想是 相对评估,具体而言:
-
• 每个输入,模型会生成一组可能的回答。 -
• 这些回答不会单独评估,而是通过相互比较来确定优劣。 -
• 奖励机制 基于回答相对于组内平均水平的优势或劣势,而非绝对得分。
这种方法不仅提升了训练效率,还通过组内竞争不断推动模型优化推理能力,进而赋能 DeepSeek 在复杂任务中取得卓越表现。
三、解读 GRPO 目标函数
在 GRPO 中,目标函数决定了模型如何更新策略以生成更高质量的回答。下面我们逐步解析这一过程。
1. GRPO 目标函数概览
我们可以直观了解 GRPO 的目标函数如何构建。



2. 用简单的方式理解 GRPO 目标函数
可以把 GRPO 的目标函数看作一份教学指南,指导模型通过对比自己的回答不断改进。
下面通过一个类比来说明其工作原理:
目标类比
想象你正在教一群学生解一道数学题。你不直接告诉他们谁对谁错,而是把所有学生的答案进行比较,找出谁做得最好(以及原因何在),然后通过奖励优秀解法、改进不足之处来帮助他们提升。这正是 GRPO 的工作方式,只不过它教的是 AI 模型而非学生。
逐步解析
步骤 1:从查询开始
从训练数据集 P(Q) 中选取一个查询 (q)。
例子:假设查询是 “8 + 5 的和是多少?”
步骤 2:生成一组回答
模型为该查询生成一组 GGG 的回答。
例子:模型生成以下几个回答:
o1: “答案是 13。”
o2: “十三。”
o3: “是 12。”
o4: “和是 13。”
步骤 3:计算每个回答的奖励
奖励是什么?
奖励通过量化回答的质量来引导模型的学习。
GRPO 中的奖励类型:
-
1. 准确性奖励: 基于回答的正确性(例如,解答数学问题)。 -
2. 格式奖励: 确保回答符合结构性指南(例如,推理部分用 标签包裹)。 -
3. 语言一致性奖励: 对语言混杂或格式不一致的回答进行惩罚。
为每个回答分配奖励(ri),根据其好坏。奖励可能依赖于:
-
• 准确性: 答案是否正确? -
• 格式: 回答是否结构良好?
示例:
-
• r1 = 1.0(正确且格式良好)。 -
• r2 = 0.9(正确但不够正式)。 -
• r3 = 0.0(错误的回答)。 -
• r4 = 1.0(正确且格式良好)。
步骤 4:比较回答(组内优势)
-
• 计算每个回答相对于组的优势(Ai)。

简单理解就是这样:

-
• 比组平均值更好的回答得到正分,表现差的回答得到负分。 -
• 这种方式促进了组内竞争,推动模型生成更好的回答。
步骤 5:使用剪枝更新策略

-
• 示例: 如果新策略开始过多地为 o1 分配概率,剪枝操作确保它不会过度强调这个回答。 -
• 这使得在复杂任务(如推理)中能够实现稳定、可靠的策略优化。
步骤 6:使用 KL 散度惩罚偏差

总结 GRPO 目标函数工作流程
-
1. 为查询生成一组回答 -
2. 基于准确性、格式等标准计算每个回答的奖励 -
3. 在组内比较回答,计算每个回答的相对优势(Ai) -
4. 更新策略,优先保留优势较高的回答,同时通过剪枝确保更新稳定 -
5. 通过 KL 正则化,防止模型策略偏离预设基线
四、GRPO 的优势所在
为什么 GRPO 更有效?
-
• 无需 Critic
GRPO 通过组内比较取代了独立评估器,从而大幅降低了计算成本。 -
• 稳定学习
结合剪枝和 KL 正则化,GRPO 保证了模型在更新过程中不会出现剧烈波动,使得学习过程更加稳健。 -
• 高效训练
针对推理任务的相对评分机制,使 GRPO 更适用于那些绝对评分难以实现的复杂任务,提升了训练效率。
现实生活中的类比
设想一群学生在解一道数学题:不是由老师单独评分,而是学生们相互比较答案,优秀者受到鼓励,落后者则从错误中学习。随着时间推移,全体学生水平逐步提高。这一过程正是 GRPO 训练 AI 模型的真实写照。
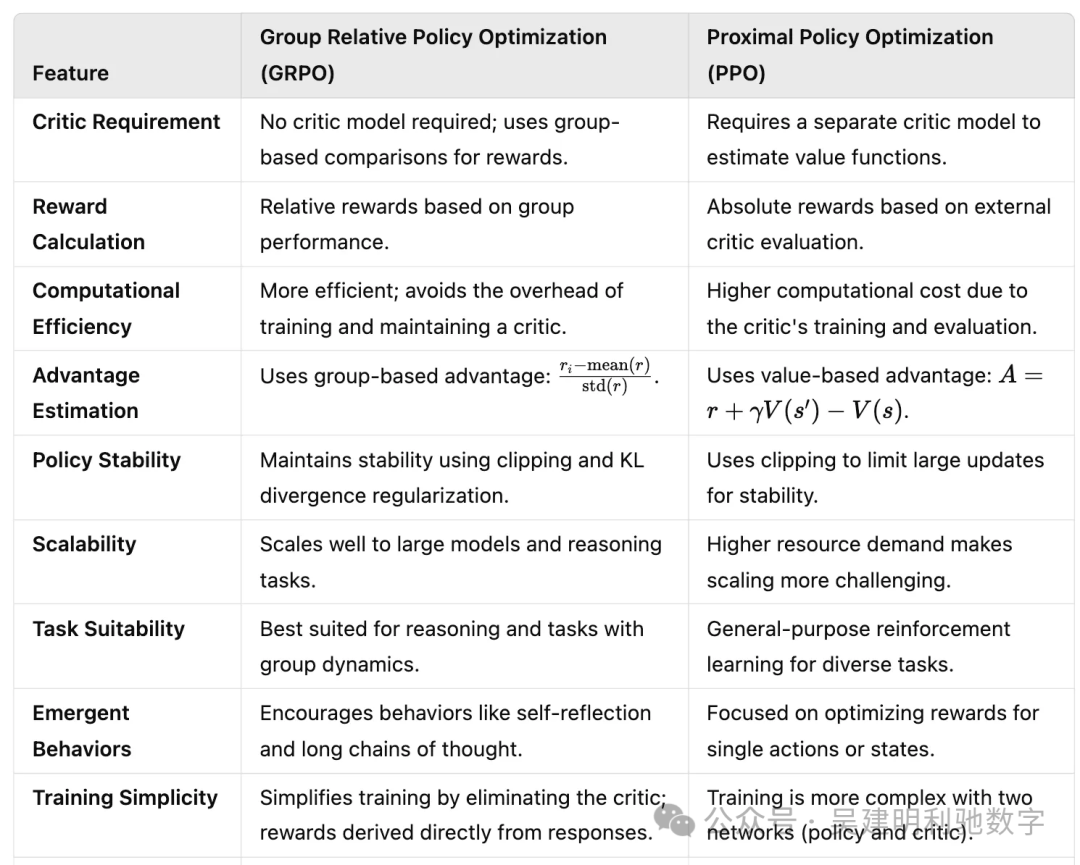
五、GRPO 与 PPO 的比较
下图展示了 GRPO 与传统 PPO 在不同维度上的对比,清晰地体现了 GRPO 在效率、稳定性和可扩展性上的优势。
六、DeepSeek 的成功实践
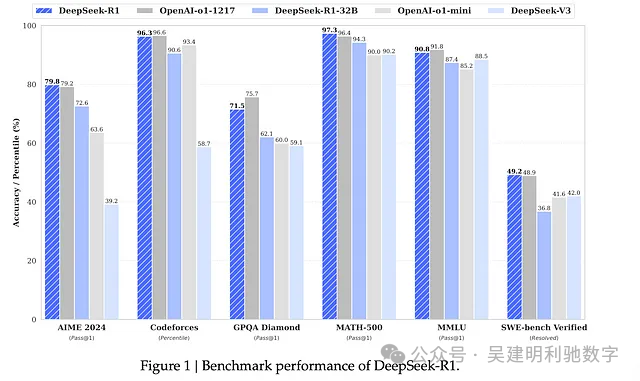
通过 GRPO,DeepSeek 在推理任务中取得了令人瞩目的成绩,具体体现在以下几个方面:
-
• 增强推理能力
DeepSeek-R1-Zero 在 AIME 2024 中获得了 71.0% 的 Pass@1 分数,通过多数投票提升至 86.7%,在数学和逻辑问题上与 OpenAI 等专有模型比肩。 -
• 新兴高级能力
通过 GRPO,DeepSeek 模型发展出自我验证、反思和长链思考等高级推理行为,这些能力对于解决复杂问题至关重要。 -
• 优异的可扩展性
GRPO 采用组内优化,去除了对评论者模型的需求,显著降低了计算开销,使得大规模训练成为可能。 -
• 成功的模型蒸馏
从 GRPO 训练的模型中提取出的较小模型依然保留了高水准的推理能力,为 AI 应用的普及和成本控制提供了保障。
通过聚焦组内相对表现,GRPO 不仅为 DeepSeek 设定了推理和长文理解的新标杆,同时在效率与可扩展性方面也展现出卓越优势。
参考文献:
1、https://arxiv.org/abs/2501.12948
2、https://medium.com/@sahin.samia/the-math-behind-deepseek-a-deep-dive-into-group-relative-policy-optimization-grpo-8a75007491ba
相关文章
