OpenAI的一个员工连续发了11个帖子,称他们的内部实验模型已经可以拿到国际数学奥赛金牌,真是这样吗?这款模型实力到底如何?
要回答这个问题,我们首先要确定一个共识:那就是像OpenAI这样的公司不管是CEO奥特曼,还是任意员工在公开社交媒体发布信息,都肯定是精心策划的具有明确目的性的商业行为。
说白了,他们说话,绝不可能像普通人发个朋友圈一样,而是想要达到类似于Marketing营销的效果。
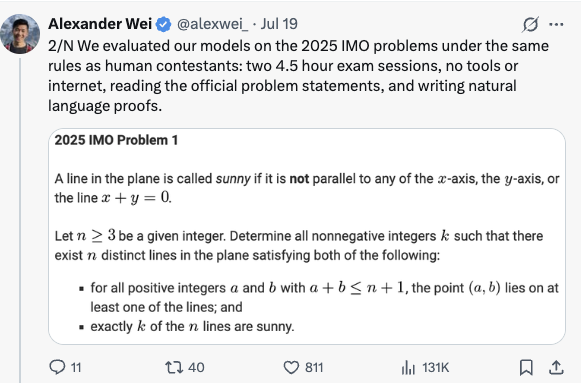
第一个帖子就很讲究,直接1/N开头,表明还有更多信息,但具体不知道多少,给人期待值。另外直接说了OpenAI一个实验中的模型达到了世界上最著名的数学竞赛IMO金牌水平。

IMO就是数学竞赛中的奥林匹克比赛,能拿到金牌的都是能力万中无一的人,图中可以看到这些人后来成就都远超普通人。
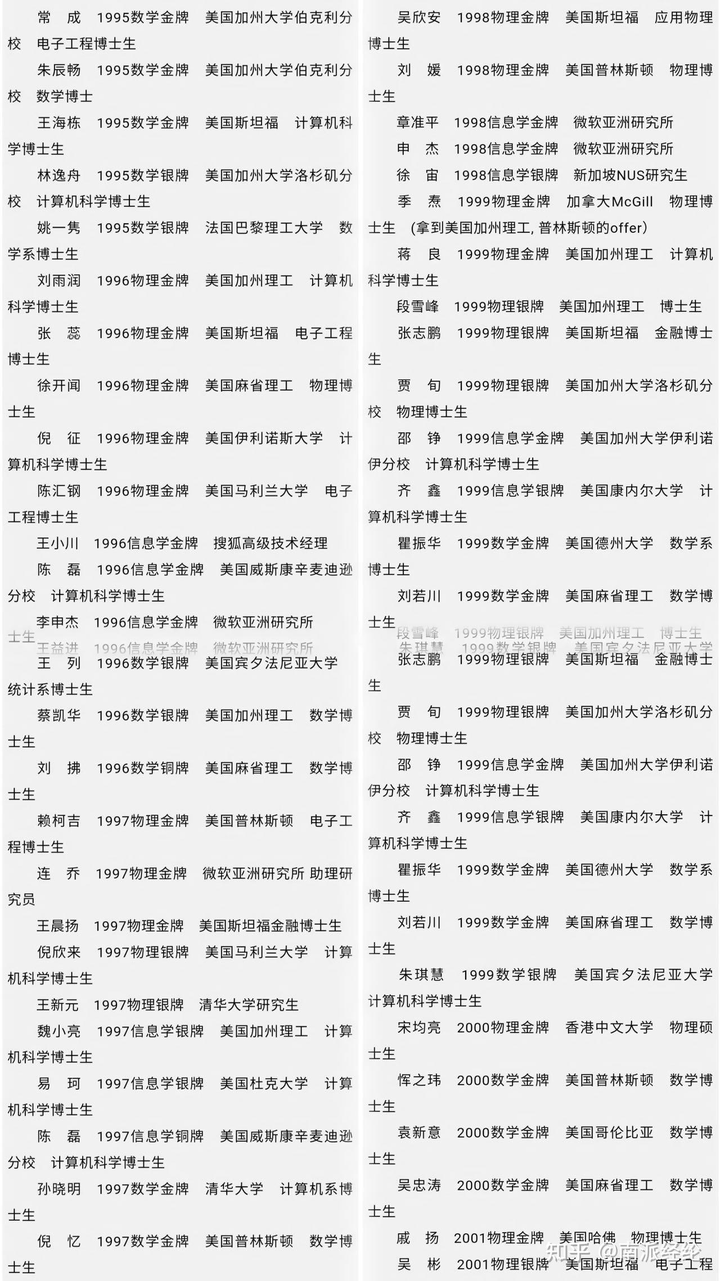
而AI能拿到这个级别的分数,其实OpenAI就在这里埋下一个“隐喻”,那就是OpenAI的模型依旧冠绝全世界。
配图也暗示了这一点儿,它用的是草莓+金牌。

草莓的单词是strawberry,不知道大家记不记得,去年年底有一个巨大的hype,就是OpenAI在秘密的训练名叫Q和Strawberry的模型,现在我觉得GPT5的代号就是Strawberry。
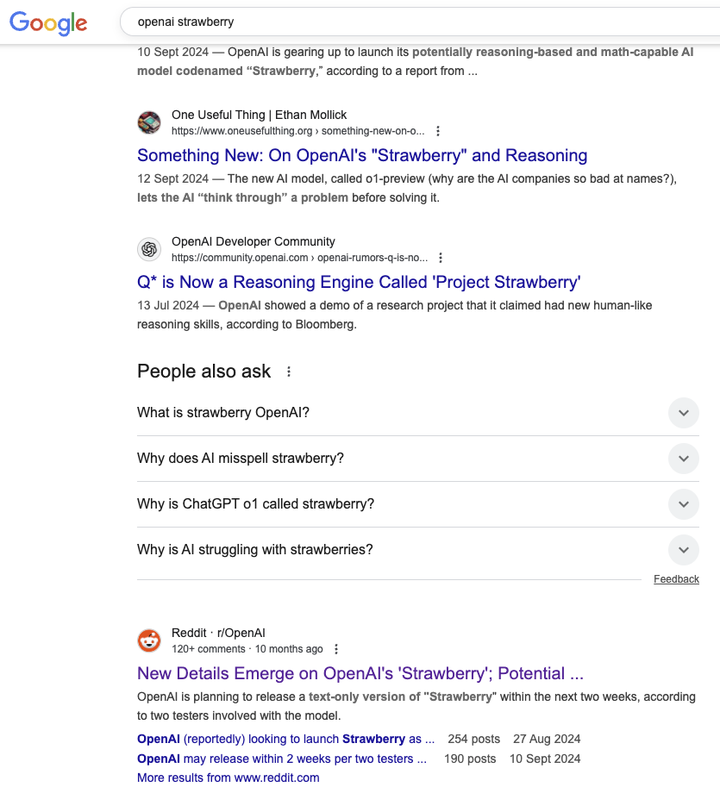
我的假设基于8/N条推,发帖人说了,GPT5马上要发布,因为他是代表OpenAI发的这个帖子,并且没有删除或者其他争议,那说明这个信息就是OpenAI公关部门或者市场营销部门共同参与编写的,所以真实度很高
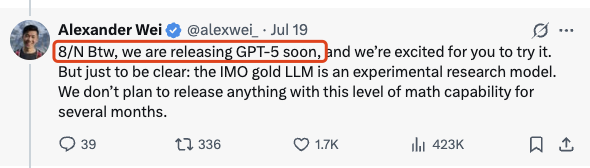
同时他还说,拿到IMO金牌的模型是一个实验性质的模型,近几个月内不准备发布。
那说明了什么,这个实验模型大概率是基于GPT5做的post-training,极有可能是o系列的,甚至有尽可能就叫o4-ultra或者o4-heavy之类的名字。
我的想法基于第3和4条twitter,作者说了,IMO题目的难度必须要经过超长时间的思考,所以大模型LLM reasoning的时间就得从几秒延长到100mins,这个数据远超市面上的reasoning LLM的时间,特别是过长的reasoning会被认为是死锁被强制的切断。
那么这个reasoning时间>=10 mins的实验版,一定是基于GPT5,做的超长reasoning frame的超重型模型,专门用来做超级复杂问题的推理模型。
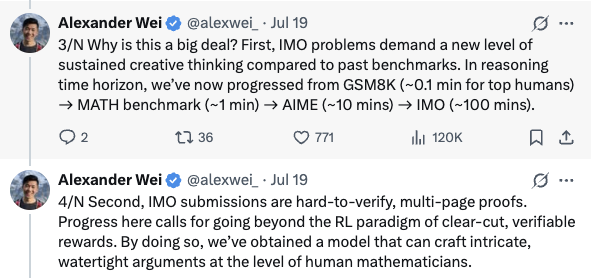
结合第二个帖子看,他宣称实验模型和人类一样的规则,2个4.5小时的时间,不用工具或者网络,单纯凭借模型本身的能力。
这就也变相的印证了第五个帖子的核心信息,这也是OpenAI想要秀的肌肉。
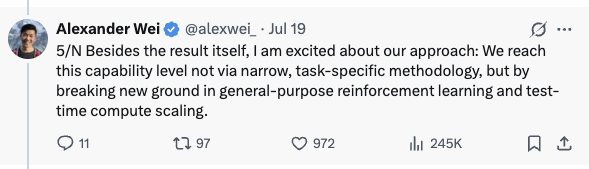
他强调,这一成就并非通过“狭隘的、针对特定任务的方法论”实现的。简单来说,他们没有为IMO问题专门设计一个“数学求解器”,而是通过改进通用强化学习(general-purpose reinforcement learning)和测试时计算扩展(test-time compute scaling)这两个基础方法论。
这就是秀肌肉,他想要说的就是GPT5以及基于GPT5做的post-training得到的模型就是世界级的,同时它也是通用型大模型。
所谓的general-purpose,其实就跟AGI中的General异曲同工,还是告诉大家,OpenAI还是朝着AGI的方向在走,同时依旧最前沿SOTA。
这里面的两个核心词汇,都在暗示他们的技术先进性。
-
通用强化学习(general-purpose reinforcement learning): 这意味着他们很可能解决了“奖励稀疏”和“信用分配”等在复杂任务中的核心RL难题。特别是帖子4中提到的,IMO证明这种难以验证、没有明确奖励的场景,他们成功“超越了传统RL范式”,这对于所有需要复杂规划和创造性的任务(如科学发现、写小说、制定商业策略)都有着巨大的借鉴意义。
-
测试时计算扩展(test-time compute scaling) 这暗示了模型在推理(inference)阶段使用了大量的计算资源进行类似“深度思考”或“搜索”的过程(可能类似于思维树/Tree of Thoughts的复杂版本)。模型不是“一蹴而就”给出答案,而是可以花时间去探索、验证和构建一个复杂的论证。这是一种让模型能力在不重新训练的情况下大幅提升的有效路径。
此外他还提到了一些测试时候的方法论,尽量让大家觉得他们的模型测试是公平合理的,这里不展开说,陶哲轩也评价了这件事,他的主要观点就是OpenAI做IMO题目的过程并不公开,所以他不予置评。

最后,作者还说了一个比较私人的事情,让整个thread显得不那么营销。做法是作者用自己2021年对2025年的预测(MATH达到30%)与现实(IMO金牌)进行对比,展示了AI发展的超指数级速度。
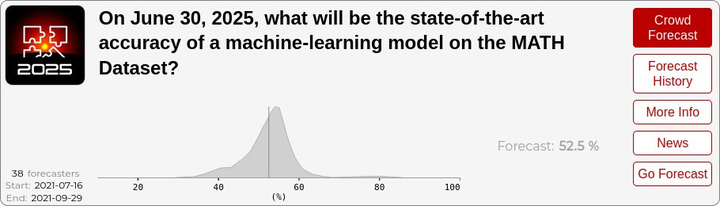
怎么说呢,对于整个AI环境来说肯定是有好处的,毕竟大家都推举,才有可能让整个行业获得大量关注,以及大量金钱,但OpenAI的目的明显不止于此,他们可能一直想做的是AI寡头。

END
往期推荐
告别死磕源码!这套AI阅读法,让你从宏观到微观彻底看透
DeepSeek为什么不能处理音频、视频、图像信息?
在 AI 的加持下,现在读博是不是比以前容易很多?
相关文章
