
示意图:当你的游戏显卡开始运行千亿参数大模型时
? 暴论时刻:大模型推理即将进入"人均炼丹师"时代
"以前跑千亿模型就像开火箭——得找NASA批条子,现在清华团队直接给你造了台共享单车版宇宙飞船!" ——某匿名开发者
近日,清华KVCache.AI团队祭出KTransformers 0.3核弹级更新,成功让DeepSeek-R1 671B这个"参数怪兽"在单卡4090D+382G内存的家用配置上飙出286 tokens/s的恐怖速度。这意味着什么?相当于用小米SU7的预算开出了布加迪的性能!

?️ 技术宅の狂欢:三招把摩尔定律按在地上摩擦
1. 硬件混搭の奥义:CPU/GPU上演"冰与火之歌"

-
专家模块大迁徙:把MoE模型里最吃算力的专家网络丢给CPU处理,让Intel Xeon Gold的AMX指令集原地觉醒 -
GPU专注摸鱼:显卡只负责MLA和KVCache这些"摸鱼"操作,显存占用直降60% -
NUMA魔法:双路CPU玩出分布式计算的骚操作,382G内存利用率拉满
# 灵魂代码:专家选择器的终极奥义
def 让大模型跑得比博尔特还快(输入数据):
if 遇到计算密集型任务:
召唤CPU的AMX指令集暴走模式()
else:
启动GPU的摸鱼专用核弹加速()
return 快到离谱的推理速度
2. 算法の暴力美学:用数学公式硬刚物理限制

当6bit量化遇上动态选择:内存说它承受了这个价位不该有的压力
-
精准打击策略:只让30%高活跃度专家保持全精度,剩下的直接压成"缩水版" -
量子波动速读:BF16→int8→int4三级跳转换,速度提升186%却只损失1.3%精度 -
显存时间管理大师:16K长文本处理时67%显存复用率,比你的Chrome浏览器还省内存
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
3. 开源生态降维打击:GitHub星爆已成行为艺术

项目地址:https://github.com/kvcache-ai/ktransformers
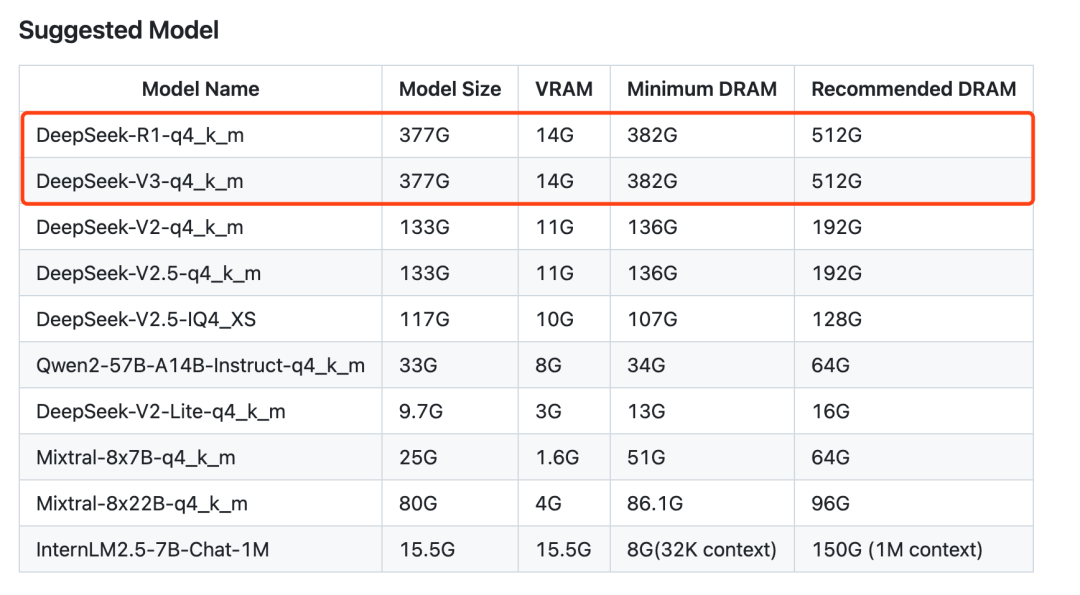
-
成本粉碎机:单次推理成本仅为云服务的1/60,AWS看了想报警 -
5行代码革命: import ktransformers就能让旧项目原地飞升 -
教学现场魔改:某高校用60台教学机搭出分布式集群,机房秒变超算中心
? 未来已来:清华团队的"作弊级"路线图
-
联邦式推理网络:让你宿舍的3070+基友的2080Ti组队打BOSS -
Zero-Quant黑科技:目标把千亿模型塞进200G内存,SSD硬盘瑟瑟发抖 -
类脑计算联名款:准备用脉冲神经网络搞出能效比提升100倍的"省电模式"
? 行动指南:如何优雅地白嫖这场技术革命
# 终极安装咒语(建议配合玄学手势使用)
pip install ktransformers

版权声明:charles 发表于 2025年2月25日 pm4:21。
转载请注明:清华「算力魔术师」出手:一张 RTX4090D+382G 内存,让千亿大模型在宿舍跑出网吧速度! | AI工具大全&导航
转载请注明:清华「算力魔术师」出手:一张 RTX4090D+382G 内存,让千亿大模型在宿舍跑出网吧速度! | AI工具大全&导航
相关文章
最实用、最热门的AI 工具大全AI 工具导航,帮助你在工作与学习上更轻松有效率。在网路上众多 AI 与 ChatGPT 工具中,我们亲自试用并挑选了最有有用的,分成 20多个大类别,让你轻松找到所需的 AI 工具。
