
前言
过去一个月,全球大模型圈最热的关键词,非MCP莫属。
模型侧,从Claude到Open AI,从Llama到DeepSeek、通义;
应用侧,从Figma到Unreal,从Milvus到高德地图,全球超过 8,000 个主流工具和软件支持MCP,适配 MCP Server已经成为行业标准动作;
可以说,模型与工具对接标准的大一统时代已经呼之欲出;而借助MCP,人人都是AI应用开发者的时代也正加速到来。
但MCP 是怎么爆红的?会彻底取代Function Calling 吗?MCP 离“事实标准”还有几步?如何使用mcp-server-milvus服务?
针对以上几个问题,我们将在本文中,作出重点解读。
01
为什么需要MCP:AI统治世界,还需突破两道墙
为什么在新闻报道中,AI上知天文下知地理无所不能,但是实际生活中,却总感觉差点意思?因为两堵墙的存在。
第一堵墙:信息孤岛
无论你的大模型多么聪明,它的知识都停留在训练结束的那一刻。而世界,是不停地变化的,比如,信息孤岛的最典型例子是大模型永远不知道现在几点。类似的案例还包括:
-
公司刚发布的年度战略,模型不知道;
-
某个内网数据库里的用户埋点数据,模型永远接触不到;
-
项目组昨天刚写完的新接口文档,它也不可能预见。
AI 一旦与现实脱钩,它的回答就注定带有幻觉、偏差,甚至风险。
第二堵墙:遗留系统
大模型只能负责更聪明的推理、计算,但问题是大模型在做完五一旅行规划之后,只有对接上我们的机票、酒店、打车软件,才能完成最终的执行;对企业场景同样如此,只有接入企业的财务、销售、数据库系统,才能真正发挥作用。但现实中
-
每一家公司的IT系统构成都不一样:MySQL、Oracle、Redis、自研 CRM、私有云部署…
-
就算有 API,OpenAI 和 Claude 的 Function 调用格式也各不相同,对接是个超级大工程。

02
搞定大模型困境的三条主流路径
大模型的落地困境说白了,其实就是不知道和干不了。
关于解决这两个问题,业内有以下三个解决思路:
1、RAG,解决不知道的信息孤岛。
其核心思路是让大模型实时检索外部知识库(比如公司文档、合规政策、技术资料),再生成回答,把"闭卷考"变成"开卷考"。
但RAG也有局限,那就是要想RAG的效果好或者模型表现稳定的话,对接的数据源需要结构化或至少格式统一,背后的工程投入不低;而且,RAG 本身不能“执行指令”或“调用工具”,这就导致其场景被限制在了IMA知识库的范围。
2、Function Calling,同时解决不知道与干不了。
Function Calling的核心思路是让大型语言模型(LLM)直接将用户请求转化为结构化的函数调用指令。模型根据预先定义的函数接口生成调用信息(通常为JSON格式),紧接着,外部应用读取并执行相应函数生成响应。让 AI 不仅能说,还能做。例如:
查天气 → 调用天气API;
开灯关灯 → 调用智能家居接口;
查数据库 → 执行SQL;
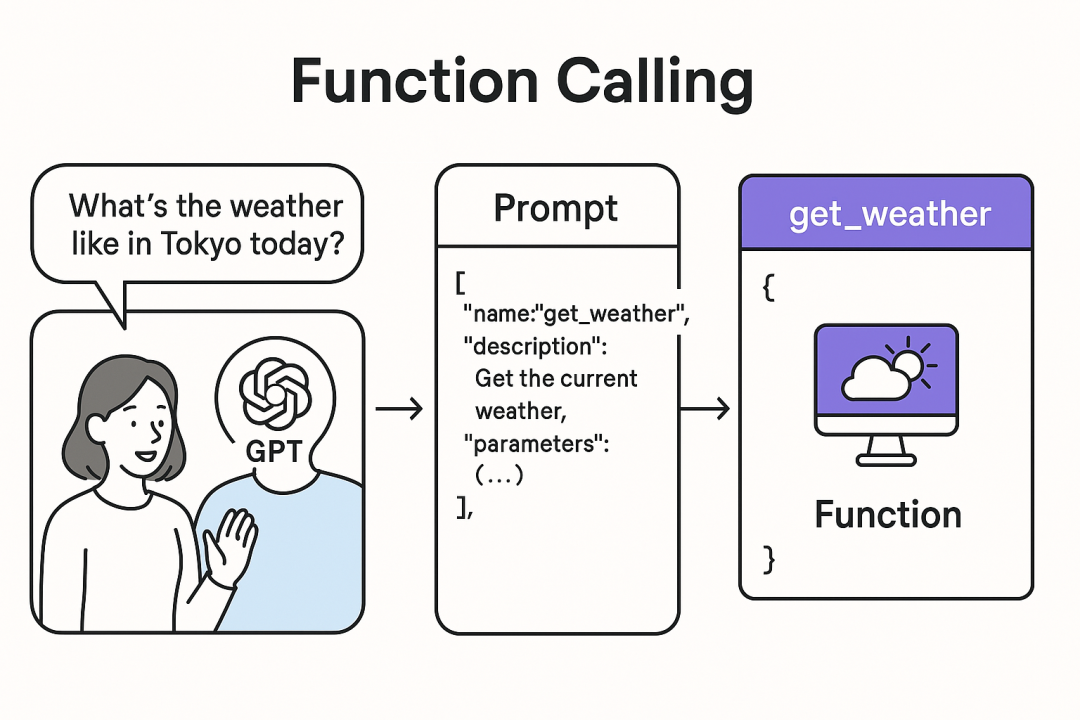
但Function Calling的问题也不小。
首先,函数定义与对话 Prompt 之间存在强耦合关系,这使得后期的修改和功能升级变得异常困难。开发者通常需要在应用代码中手动、静态地将函数定义嵌入到 Prompt 中,一旦注入聊天上下文,这些定义就“固化”下来,难以动态调整。若要新增或修改功能,只能回头修改代码或 Prompt,开发体验非常割裂。
其次,模型的上下文管理与函数调用逻辑往往在同一个进程中处理,一旦出现异常,轻则调用失败,重则可能导致整个服务崩溃,可靠性难以保障。
更棘手的是,不同大模型平台在函数接口的支持标准上并不统一。比如你想定义一个 search_weather(city) 的函数,放到 OpenAI、Claude 或 Gemini 中使用,就需要分别编写不同的 schema 和包装逻辑。最终的结果是:如果你有 M 个大模型应用、N 个工具或服务,理论上可能需要实现 M × N 套 Glue 代码,不仅开发效率低下,更会带来指数级增长的维护成本,严重制约了规模化落地的可能性。
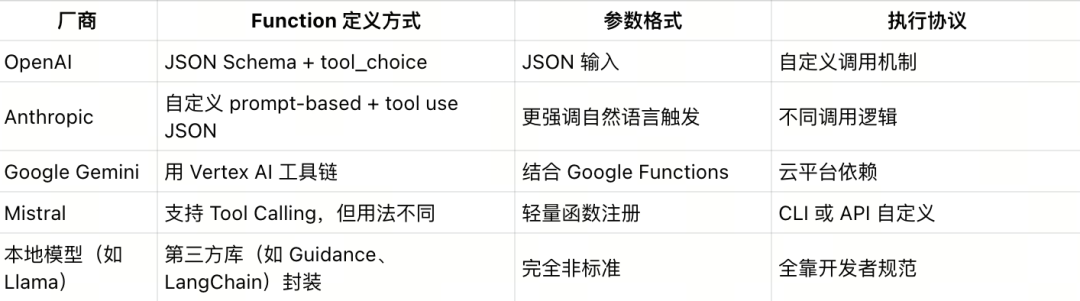
OpenAI Function Calling示例:
OpenAI GPT-4 会返回一个带有function_call字段的JSON对象
{"index": 0,"message": {"role": "assistant","content": null,"tool_calls": [{"name": "get_current_stock_price","arguments": "{n "company": "AAPL",n "format": "USD"n}"}]},"finish_reason": "tool_calls"}Claude Function Calling 示例:
Anthropic Claude则用内容类型标记
tool_use
{"role": "assistant","content": [{"type": "text","text": "<thinking>To answer this question, I will: …</thinking>"},{"type": "tool_use","id": "1xqaf90qw9g0","name": "get_current_stock_price","input": {"company": "AAPL", "format": "USD"}}]}Google Gemini Function Calling 示例
Google Gemini使用
functionCall键
{"functionCall": {"name": "get_current_stock_price","args": {"company": "AAPL","format": "USD"}}}LLAMA Function Calling 示例:
LLaMA采用类似JSON结构
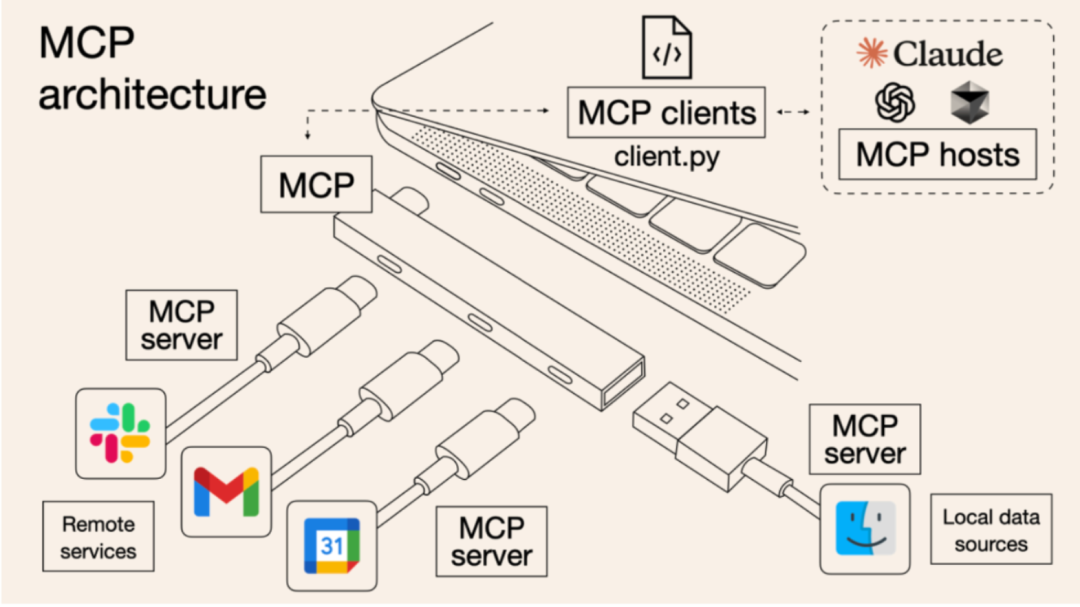
{"role": "assistant","content": null,"function_call": {"name": "get_current_stock_price","arguments": {"company": "AAPL","format": "USD"}}}建立Function Calling 的思路基础上,MCP 协议(Model Context Protocol,简称MCP)横空出世。
其核心思路是为模型上下文协议引入了一种客户端-服务器的开放架构。通过一套标准,兼容多个工具和数据系统,对模型可以调用和访问的外部能力进行了精细化的拆分,将过去N个模型,M个服务对接需要N*M次开发,简化成了整个系统只需要N+M次开发的数学题。
而从用户侧,通过丰富的工具接入,MCP真正实现了“对话即操作”。
面向普通人,你可以一句话让AI帮你整理电脑桌面,或者一句话打开你家的扫地机器人
面向专业人士,Blender MCP可以让你一句话就自动实现一个3D建模,过程中还能通过和AI聊天不断修改;Figma MCP可以让你一句话自动完成产品原型设计,结合cursor可以让AI直接交付一个网站或者一个app;Unity和虚幻引擎的MCP则可以让你用和AI对话的方式构建一个完整的游戏建模,独立游戏要变天了。
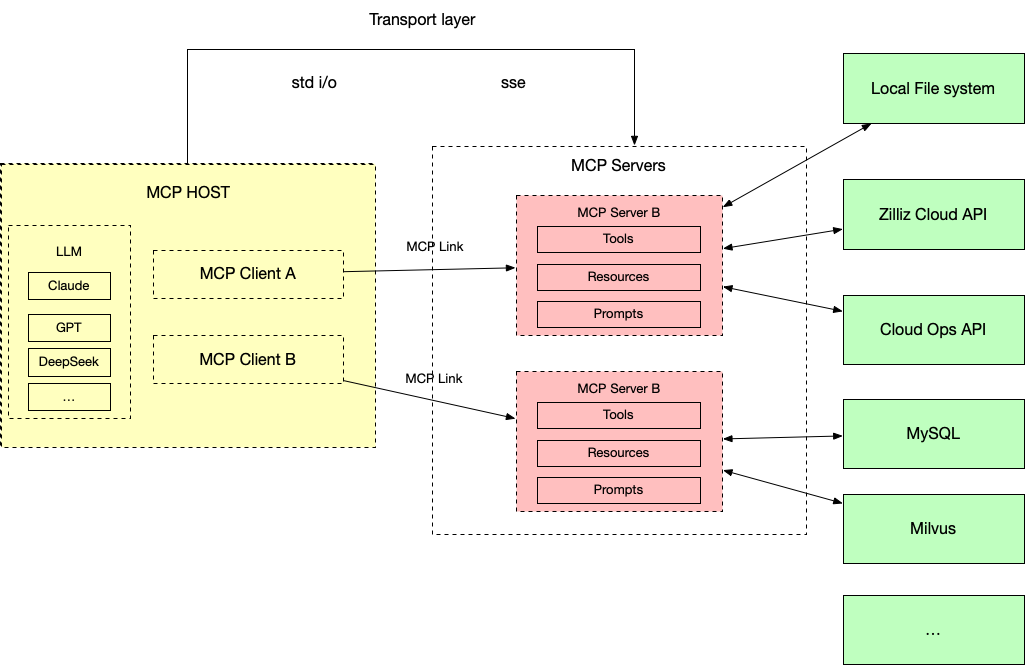
具体来说,MCP协议工作生命周期如下:
第一步,初始化:当宿主应用程序(MCP Host)启动时,它会创建N个MCP Client,这些MCP Client通过握手和对应的MCP Server交换有关功能和协议版本的信息。
第二步,发现:MCP Client请求MCP Server提供的能力(Tools、Resources、Prompts)。MCP Server以列表和描述进行响应。
第三步,上下文提供:宿主应用程序现在可以向用户提供Resources和Prompts,或者将Tools解析为LLM兼容的格式,例如JSON Function calling。
第四步,调用:如果LLM确定需要使用工具(例如,基于用户请求,如“Milvus实例in01-0bbd6d324ff055e现在处于什么状态?”),则Host会指示Client向相应的Server发送调用请求。
第五步,响应:MCP Server将结果发送回MCP Client。
第六步,整合输出:MCP Client将结果传递给MCP Host,主机将其纳入LLM的上下文,从而使LLM能够根据新鲜的外部信息为用户生成最终响应。
可以发现,通过统一的接口,MCP除了降低开发难度之外,还可以带来:
数据实时流动:相比传统 Function Calling 更像是“写死”的调用逻辑,而 MCP 支持动态的数据交互,工具状态和响应可以实时更新,交互更自然、更智能。
数据不出本地,隐私保护:一个被很多人忽视的点是,MCP 的工具执行并不依赖云端远程,很多时候可以在本地完成调用。这意味着数据不用上传,隐私风险也就降到最低。
完整的生态,灵活的工具选择: MCP 支持自动工具发现和上下文管理,模型可以根据对话内容自动判断该用哪个工具。
03
MCP很好,但并非全能
随着Claude、open AI、Llama、DeepSeek、通义先后官宣支持MCP,以及应用侧超过 8,000 个主流工具和软件支持MCP,模型与工具对接标准的大一统时代已经呼之欲出。
但MCP并非全能。
首先,对一些非常轻量级的高频任务,比如调用计算器、天气插件来说,能够快速响应的Function Call仍是更优解;MCP更适合相对复杂的任务编排。
其次,不同工具与软件对MCP的支持力度是不同的,MCP Server质量良莠不齐,对于小白用户而言,安全性也存在比较大的风险。目前市面上的主流实践方案,并没有完整实现MCP协议最初的设想,基本上都是在开发Tools,而Prompts和Resource这两层还没有很好的实践案例出来
https://modelcontextprotocol.io/llms-full.txt
最重要的是,当前MCP还缺乏大规模在线服务应用的验证
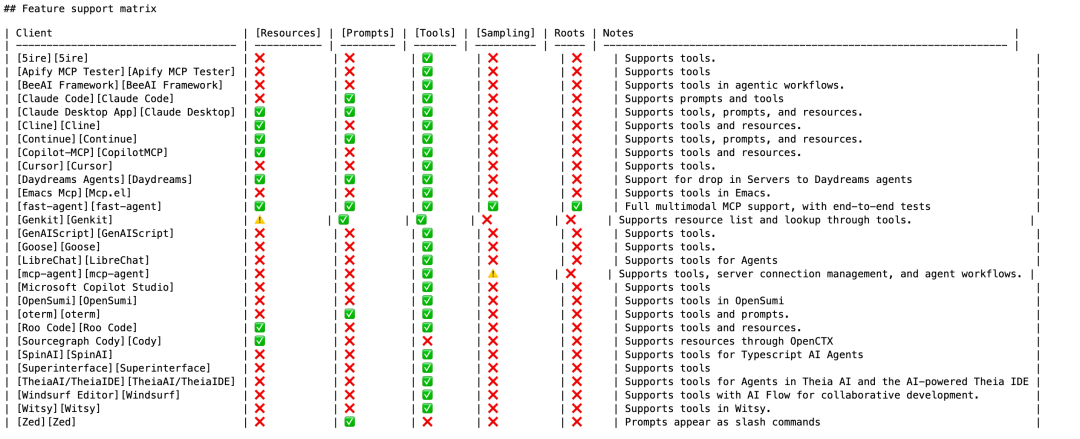
-
准备这次分享的过程中在Claude3.5和3.7模型下,我挂载30-50个Tool,Prompt驱动模型调用Tool成功率是100%(测试了几十次)但实际跑在线业务的时候,如果有成百上千个Tool,模型是否还能保持稳定?或者是否有更好的工程实践路线?
-
Claude3.5和3.7的token费用现在还是很贵,有没有可能通过混合模型架构来降低成本?
-
对于一些可能暴露敏感数据的Tool,有可能需要通过本地部署的大模型,例如DeepSeek来驱动,执行质量需要进一步验证(可能针对MCP的模型调优不如Claude)
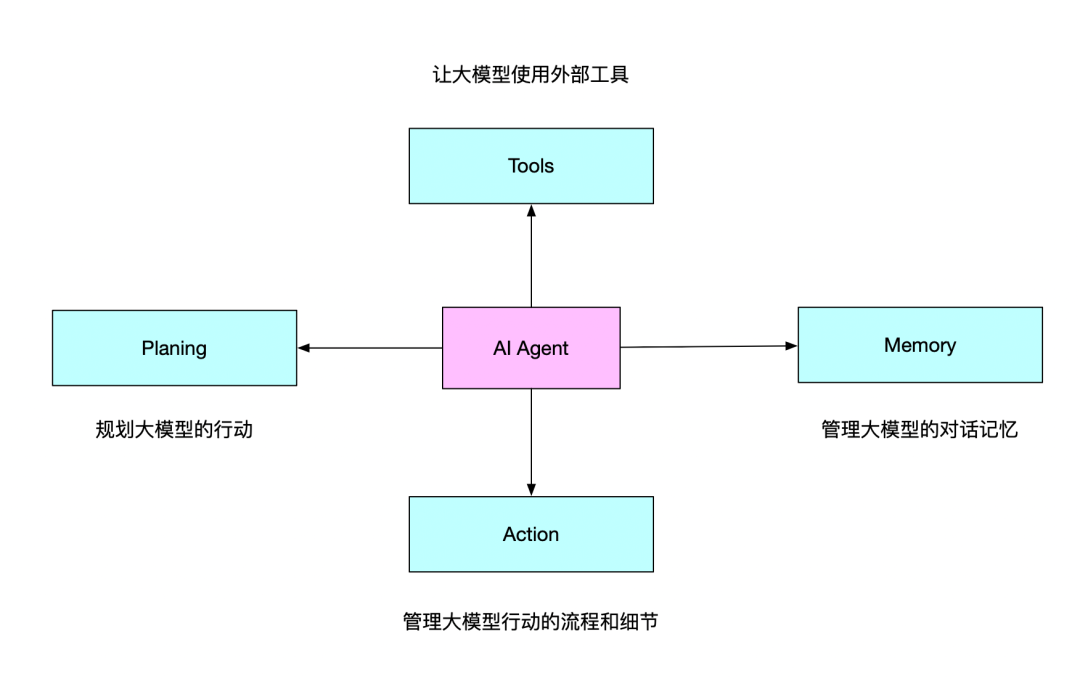
另外补充一句,MCP实际上只解决了AI Agent的一部分问题。比如,,MCP协议给Tools的使用提供了标准和稳定的解决方案,一定程度上优化了Action的实践路径。但对于Planing和Memory,还需要额外的工程设计和实现。
当前,Planing层面,可能的解决方案是dify这样的AI工作流编排;
Memory层面,则主要依靠Milvus + 关系型数据库 + Data Warehouse。
以下是mcp-server-milvus的最佳实践。
04
实战案例:mcp-server-milvus项目
背景:mcp-server-milvus项目介绍
该项目包含一个 MCP 服务器,可提供对Milvus向量数据库功能的访问。
项目地址:https://github.com/zilliztech/mcp-server-milvus
第一步:环境准备与配置
说明:本教程不含Python3和Nodejs安装展示,请自行按照官方手册进行配置。
Python3官网:https://www.python.org/
Nodejs官网:https://nodejs.org/zh-cn
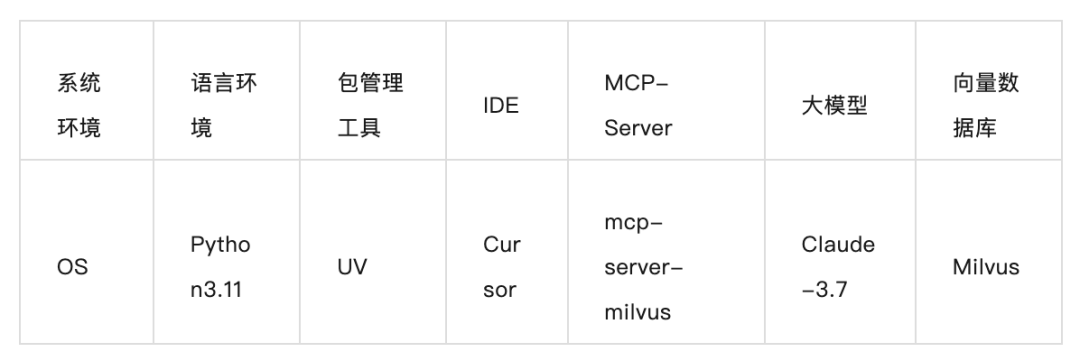
第二步:安装UV
curl -LsSf https://astral.sh/uv/install.sh | sh或者
pip3 install uv -i https://mirrors.aliyun.com/pypi/simple安装完成之后,我们需要对UV进行验证。
uv --versionuvx --version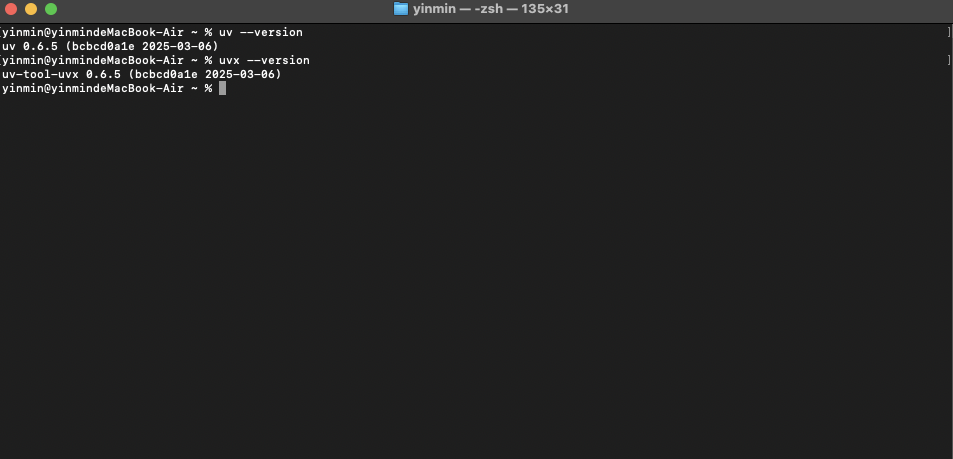
第三步:安装Milvus
Milvus 是由Zilliz全球首款开源向量数据库产品,能够处理数百万乃至数十亿级的向量数据,在Github取得3w+star数量。基于开源 Milvus ,Zilliz还构建了商业化向量数据库产品 Zilliz Cloud,这是一款全托管的向量数据库服务,通过采用云原生设计理念,在易用性、成本效益和安全性上实现了全面提升。
通过MCP服务器,开发者无需深入了解Milvus的底层API细节,就可以轻松实现向量数据的实时查询、相似度搜索和数据管理等操作,极大地降低了向量数据库应用的开发门槛。
部署Milvus环境要求,可参考Milvus官网:https://milvus.io/docs/prerequisite-docker.md
必要条件:
-
软件要求统:docker、docker-compose
-
内存:至少16GB
-
硬盘:至少100GB
下载milvus部署文件
[]
启动Milvus
[]
[]


第四步:Cursor中配置mcp-server-milvus服务
Clone项目到本地
clone https://github.com/zilliztech/mcp-server-milvus.git
优先在本地执行依赖下载
建议:由于网络原因,建议优先在本地执行nv命令进行安装验证后在前往cursor添加mcp-server
uv run src/mcp_server_milvus/server.py --milvus-uri http://192.168.4.48:19530
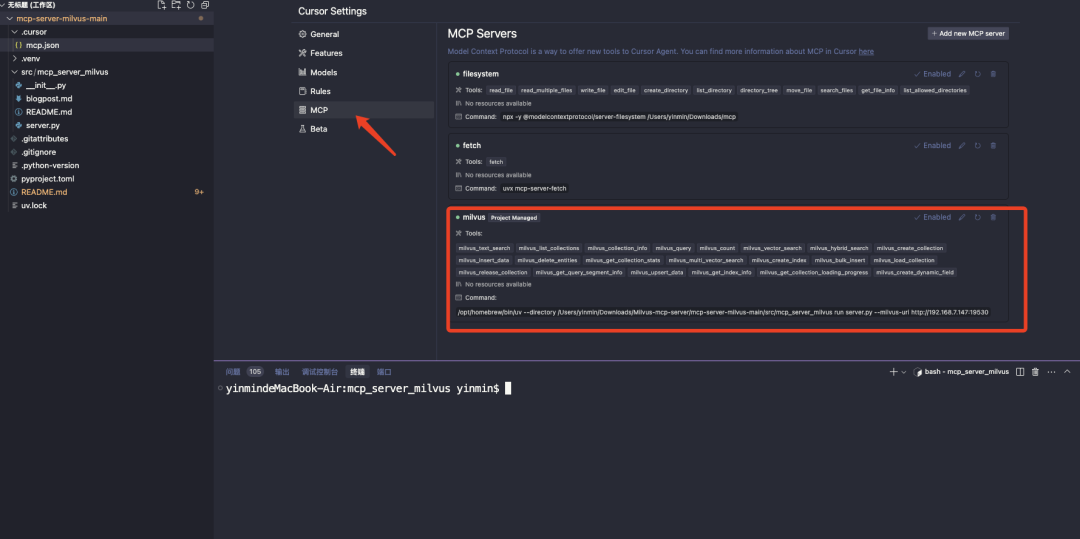
新增mcp配置
在项目根目录中创建一个.cursor/mcp.json文件:
说明:这里填写自己的文件路径
mkdir -p /path/to/your/project/.cursor
参数说明:
1./PATH/TO/uv
替换uv可执行命令的路径
2.--directory
替换刚才clone下来的项目的完整路径
3.--milvus-uri
替换部署的milvus的服务地址
{"mcpServers": {"milvus": {"command": "/PATH/TO/uv","args": ["--directory","/path/to/mcp-server-milvus/src/mcp_server_milvus","run","server.py","--milvus-uri","http://127.0.0.1:19530"]}}}
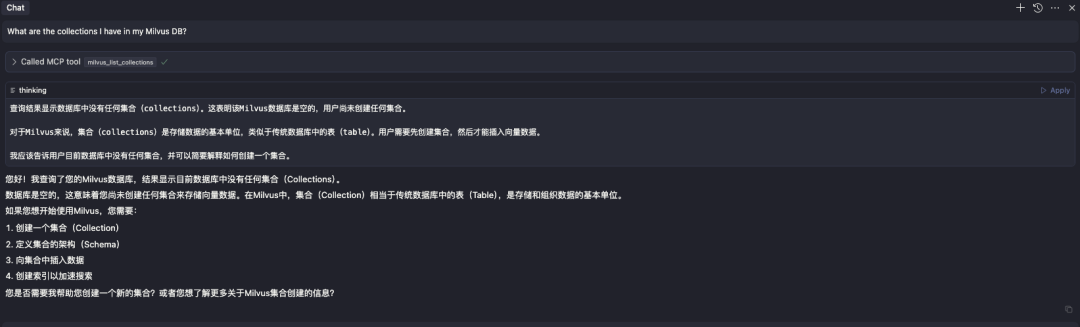
第五步:实测效果
注意在对话时务必选择Agent模式,否则Cursor是不会引用MCP服务的

首先,检查集群中的集合情况
What are the collections I have in my Milvus DB?
可以看到当前milvus数据库里是没有任何集合的
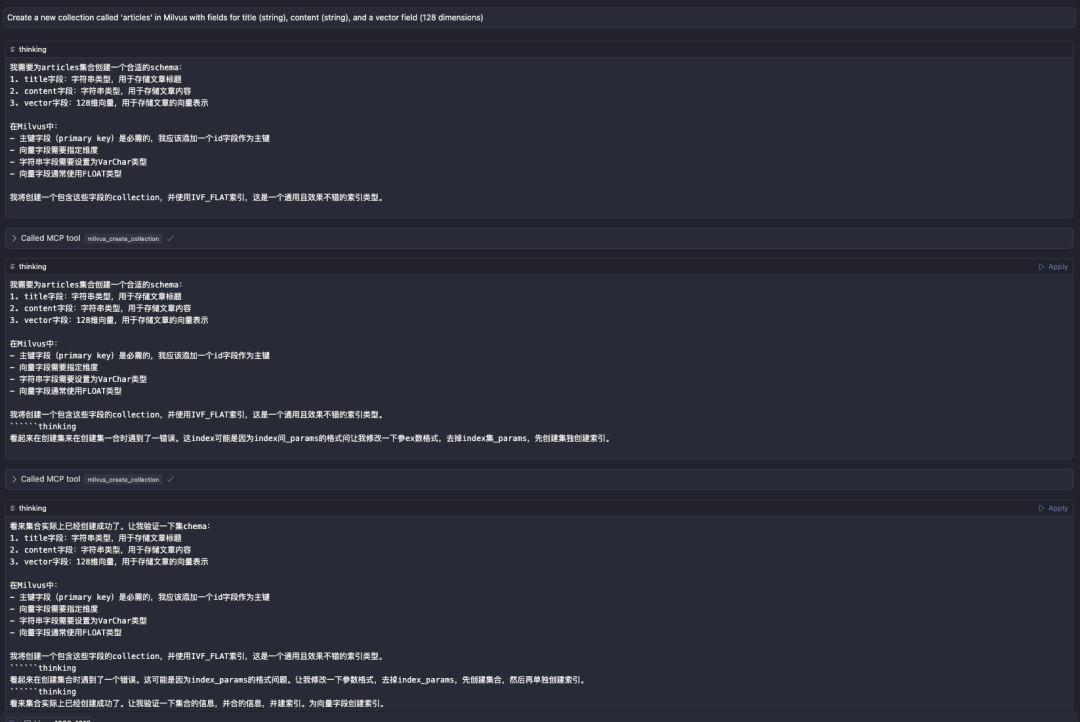
接下来,创建集合
Create a new collection called 'articles' in Milvus with fields for title (string), content (string), and a vector field (128 dimensions)
MCP自动为我创建了集合
接下来,再次查询集合
What are the collections I have in my Milvus DB?
再次查询的结果是已经查到了刚才创建的集合了
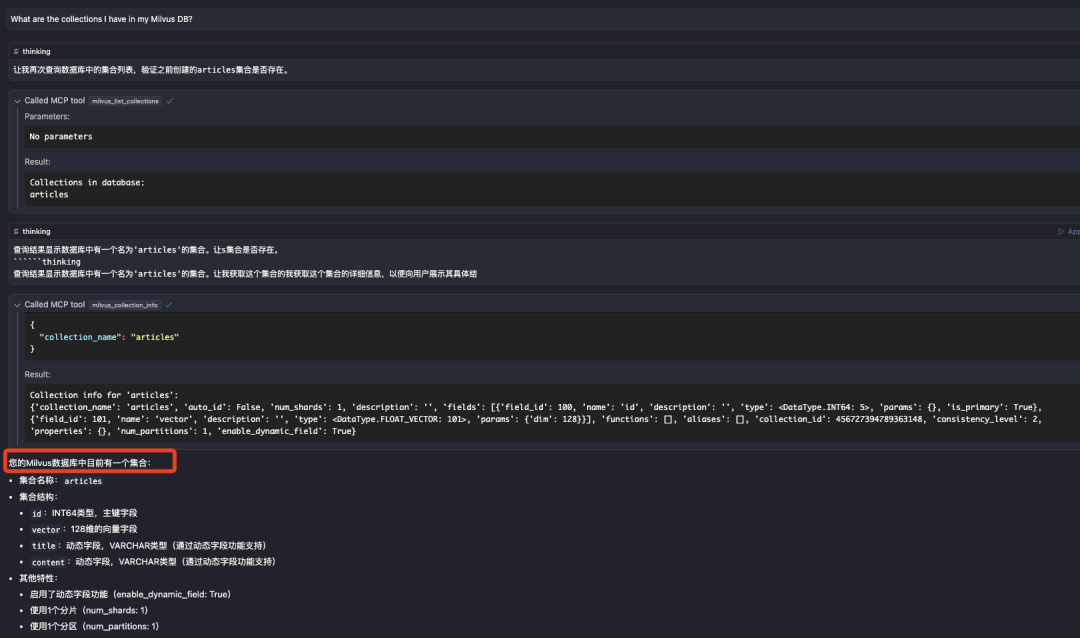
其实,案例里面这个case如果对于不太熟悉Milvus操作的人去做可能是需要半小时起步的时间的;
但通过mcp-server-milvus,跑完整个流程,只需要几分钟时间。
这不仅让开发者可以灵活地管理和查询向量数据,同时充分利用MCP协议的上下文处理优势与大语言模型的理解能力相结合,在海量向量数据中找到最相关的内容,实现更智能的信息检索和处理。
而这种范式,不仅为知识库检索和智能问答系统带来了全新的解决思路,更是一种全新的在线业务运维乃至开发范式:
在未来,运维平台,可能只有一种交互,即对话框+适当的引导信息;而更广义的开发层面,所有人都不再需要学习传统的软件交互范式,只需要理解业务,就能做任何事情,一个想法,就能撬动地球。
作者介绍

Milvus资深研发工程师:罗鑫宇
讨论|谁能统一Agent 接口?MCP 对比 A2A 、Function Calling
官宣,Milvus SDK v2发布!原生异步接口、支持MCP、性能提升
Agent的安卓时刻到了!MCP协议下的Cursor与Milvus部署指南
相关文章
